
AbstractQueuedSynchronizer的介紹和原理分析
感謝同事【魏鵬】投遞本稿。 Dedicate to Molly.
簡介
提供了一個基於FIFO佇列,可以用於構建鎖或者其他相關同步裝置的基礎框架。該同步器(以下簡稱同步器)利用了一個int來表示狀態,期望它能夠成為實現大部分同步需求的基礎。使用的方法是繼承,子類通過繼承同步器並需要實現它的方法來管理其狀態,管理的方式就是通過類似acquire和release的方式來操縱狀態。然而多執行緒環境中對狀態的操縱必須確保原子性,因此子類對於狀態的把握,需要使用這個同步器提供的以下三個方法對狀態進行操作:
- java.util.concurrent.locks.AbstractQueuedSynchronizer.getState()
- java.util.concurrent.locks.AbstractQueuedSynchronizer.setState(int)
- java.util.concurrent.locks.AbstractQueuedSynchronizer.compareAndSetState(int, int)
子類推薦被定義為自定義同步裝置的內部類,同步器自身沒有實現任何同步介面,它僅僅是定義了若干acquire之類的方法來供使用。該同步器即可以作為排他模式也可以作為共享模式,當它被定義為一個排他模式時,其他執行緒對其的獲取就被阻止,而共享模式對於多個執行緒獲取都可以成功。
同步器是實現鎖的關鍵,利用同步器將鎖的語義實現,然後在鎖的實現中聚合同步器。可以這樣理解:鎖的API是面向使用者的,它定義了與鎖互動的公共行為,而每個鎖需要完成特定的操作也是透過這些行為來完成的(比如:可以允許兩個執行緒進行加鎖,排除兩個以上的執行緒),但是實現是依託給同步器來完成;同步器面向的是執行緒訪問和資源控制,它定義了執行緒對資源是否能夠獲取以及執行緒的排隊等操作。鎖和同步器很好的隔離了二者所需要關注的領域,嚴格意義上講,同步器可以適用於除了鎖以外的其他同步設施上(包括鎖)。
同步器的開始提到了其實現依賴於一個FIFO佇列,那麼佇列中的元素Node就是儲存著執行緒引用和執行緒狀態的容器,每個執行緒對同步器的訪問,都可以看做是佇列中的一個節點。Node的主要包含以下成員變數:
Node {
int waitStatus;
Node prev;
Node next;
Node nextWaiter;
Thread thread;
}
以上五個成員變數主要負責儲存該節點的執行緒引用,同步等待佇列(以下簡稱sync佇列)的前驅和後繼節點,同時也包括了同步狀態。
| 屬性名稱 | 描述 |
| int waitStatus | 表示節點的狀態。其中包含的狀態有:
|
| Node prev | 前驅節點,比如當前節點被取消,那就需要前驅節點和後繼節點來完成連線。 |
| Node next | 後繼節點。 |
| Node nextWaiter | 儲存condition佇列中的後繼節點。 |
| Thread thread | 入佇列時的當前執行緒。 |
節點成為sync佇列和condition佇列構建的基礎,在同步器中就包含了sync佇列。同步器擁有三個成員變數:sync佇列的頭結點head、sync佇列的尾節點tail和狀態state。對於鎖的獲取,請求形成節點,將其掛載在尾部,而鎖資源的轉移(釋放再獲取)是從頭部開始向後進行。對於同步器維護的狀態state,多個執行緒對其的獲取將會產生一個鏈式的結構。
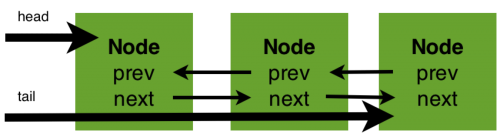
API說明
實現自定義同步器時,需要使用同步器提供的getState()、setState()和compareAndSetState()方法來操縱狀態的變遷。
| 方法名稱 | 描述 |
| protected boolean tryAcquire(int arg) | 排它的獲取這個狀態。這個方法的實現需要查詢當前狀態是否允許獲取,然後再進行獲取(使用compareAndSetState來做)狀態。 |
| protected boolean tryRelease(int arg) | 釋放狀態。 |
| protected int tryAcquireShared(int arg) | 共享的模式下獲取狀態。 |
| protected boolean tryReleaseShared(int arg) | 共享的模式下釋放狀態。 |
| protected boolean isHeldExclusively() | 在排它模式下,狀態是否被佔用。 |
實現這些方法必須是非阻塞而且是執行緒安全的,推薦使用該同步器的父類java.util.concurrent.locks.AbstractOwnableSynchronizer來設定當前的執行緒。
開始提到同步器內部基於一個FIFO佇列,對於一個獨佔鎖的獲取和釋放有以下偽碼可以表示。
獲取一個排他鎖。
while(獲取鎖) {
if (獲取到) {
退出while迴圈
} else {
if(當前執行緒沒有入佇列) {
那麼入佇列
}
阻塞當前執行緒
}
}
釋放一個排他鎖。
if (釋放成功) {
刪除頭結點
啟用原頭結點的後繼節點
}
示例
下面通過一個排它鎖的例子來深入理解一下同步器的工作原理,而只有掌握同步器的工作原理才能夠更加深入瞭解其他的併發元件。
排他鎖的實現,一次只能一個執行緒獲取到鎖。
class Mutex implements Lock, java.io.Serializable {
// 內部類,自定義同步器
private static class Sync extends AbstractQueuedSynchronizer {
// 是否處於佔用狀態
protected boolean isHeldExclusively() {
return getState() == 1;
}
// 當狀態為0的時候獲取鎖
public boolean tryAcquire(int acquires) {
assert acquires == 1; // Otherwise unused
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// 釋放鎖,將狀態設定為0
protected boolean tryRelease(int releases) {
assert releases == 1; // Otherwise unused
if (getState() == 0) throw new IllegalMonitorStateException();
setExclusiveOwnerThread(null);
setState(0);
return true;
}
// 返回一個Condition,每個condition都包含了一個condition佇列
Condition newCondition() { return new ConditionObject(); }
}
// 僅需要將操作代理到Sync上即可
private final Sync sync = new Sync();
public void lock() { sync.acquire(1); }
public boolean tryLock() { return sync.tryAcquire(1); }
public void unlock() { sync.release(1); }
public Condition newCondition() { return sync.newCondition(); }
public boolean isLocked() { return sync.isHeldExclusively(); }
public boolean hasQueuedThreads() { return sync.hasQueuedThreads(); }
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit)
throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
}
可以看到Mutex將Lock介面均代理給了同步器的實現。
使用方將Mutex構造出來之後,呼叫lock獲取鎖,呼叫unlock進行解鎖。下面以Mutex為例子,詳細分析以下同步器的實現邏輯。
實現分析
public final void acquire(int arg)
該方法以排他的方式獲取鎖,對中斷不敏感,完成synchronized語義。
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
上述邏輯主要包括:
1. 嘗試獲取(呼叫tryAcquire更改狀態,需要保證原子性);
在tryAcquire方法中使用了同步器提供的對state操作的方法,利用compareAndSet保證只有一個執行緒能夠對狀態進行成功修改,而沒有成功修改的執行緒將進入sync佇列排隊。
2. 如果獲取不到,將當前執行緒構造成節點Node並加入sync佇列;
進入佇列的每個執行緒都是一個節點Node,從而形成了一個雙向佇列,類似CLH佇列,這樣做的目的是執行緒間的通訊會被限制在較小規模(也就是兩個節點左右)。
3. 再次嘗試獲取,如果沒有獲取到那麼將當前執行緒從執行緒排程器上摘下,進入等待狀態。
使用LockSupport將當前執行緒unpark,關於LockSupport後續會詳細介紹。
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// 快速嘗試在尾部新增
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
上述邏輯主要包括:
1. 使用當前執行緒構造Node;
對於一個節點需要做的是將當節點前驅節點指向尾節點(current.prev = tail),尾節點指向它(tail = current),原有的尾節點的後繼節點指向它(t.next = current)而這些操作要求是原子的。上面的操作是利用尾節點的設定來保證的,也就是compareAndSetTail來完成的。
2. 先行嘗試在隊尾新增;
如果尾節點已經有了,然後做如下操作:
(1)分配引用T指向尾節點;
(2)將節點的前驅節點更新為尾節點(current.prev = tail);
(3)如果尾節點是T,那麼將當尾節點設定為該節點(tail = current,原子更新);
(4)T的後繼節點指向當前節點(T.next = current)。
注意第3點是要求原子的。
這樣可以以最短路徑O(1)的效果來完成執行緒入隊,是最大化減少開銷的一種方式。
3. 如果隊尾新增失敗或者是第一個入隊的節點。
如果是第1個節點,也就是sync佇列沒有初始化,那麼會進入到enq這個方法,進入的執行緒可能有多個,或者說在addWaiter中沒有成功入隊的執行緒都將進入enq這個方法。
可以看到enq的邏輯是確保進入的Node都會有機會順序的新增到sync佇列中,而加入的步驟如下:
(1)如果尾節點為空,那麼原子化的分配一個頭節點,並將尾節點指向頭節點,這一步是初始化;
(2)然後是重複在addWaiter中做的工作,但是在一個while(true)的迴圈中,直到當前節點入隊為止。
進入sync佇列之後,接下來就是要進行鎖的獲取,或者說是訪問控制了,只有一個執行緒能夠在同一時刻繼續的執行,而其他的進入等待狀態。而每個執行緒都是一個獨立的個體,它們自省的觀察,當條件滿足的時候(自己的前驅是頭結點並且原子性的獲取了狀態),那麼這個執行緒能夠繼續執行。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
上述邏輯主要包括:
1. 獲取當前節點的前驅節點;
需要獲取當前節點的前驅節點,而頭結點所對應的含義是當前站有鎖且正在執行。
2. 當前驅節點是頭結點並且能夠獲取狀態,代表該當前節點佔有鎖;
如果滿足上述條件,那麼代表能夠佔有鎖,根據節點對鎖佔有的含義,設定頭結點為當前節點。
3. 否則進入等待狀態。
如果沒有輪到當前節點執行,那麼將當前執行緒從執行緒排程器上摘下,也就是進入等待狀態。
這裡針對acquire做一下總結:
1. 狀態的維護;
需要在鎖定時,需要維護一個狀態(int型別),而對狀態的操作是原子和非阻塞的,通過同步器提供的對狀態訪問的方法對狀態進行操縱,並且利用compareAndSet來確保原子性的修改。
2. 狀態的獲取;
一旦成功的修改了狀態,當前執行緒或者說節點,就被設定為頭節點。
3. sync佇列的維護。
在獲取資源未果的過程中條件不符合的情況下(不該自己,前驅節點不是頭節點或者沒有獲取到資源)進入睡眠狀態,停止執行緒排程器對當前節點執行緒的排程。
這時引入的一個釋放的問題,也就是說使睡眠中的Node或者說執行緒獲得通知的關鍵,就是前驅節點的通知,而這一個過程就是釋放,釋放會通知它的後繼節點從睡眠中返回準備執行。
下面的流程圖基本描述了一次acquire所需要經歷的過程:

如上圖所示,其中的判定退出佇列的條件,判定條件是否滿足和休眠當前執行緒就是完成了自旋spin的過程。
public final boolean release(int arg)
在unlock方法的實現中,使用了同步器的release方法。相對於在之前的acquire方法中可以得出呼叫acquire,保證能夠獲取到鎖(成功獲取狀態),而release則表示將狀態設定回去,也就是將資源釋放,或者說將鎖釋放。
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
上述邏輯主要包括:
1. 嘗試釋放狀態;
tryRelease能夠保證原子化的將狀態設定回去,當然需要使用compareAndSet來保證。如果釋放狀態成功過之後,將會進入後繼節點的喚醒過程。
2. 喚醒當前節點的後繼節點所包含的執行緒。
通過LockSupport的unpark方法將休眠中的執行緒喚醒,讓其繼續acquire狀態。
private void unparkSuccessor(Node node) {
// 將狀態設定為同步狀態
int ws = node.waitStatus;
if (ws < 0) compareAndSetWaitStatus(node, ws, 0); // 獲取當前節點的後繼節點,如果滿足狀態,那麼進行喚醒操作 // 如果沒有滿足狀態,從尾部開始找尋符合要求的節點並將其喚醒 Node s = node.next; if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
上述邏輯主要包括,該方法取出了當前節點的next引用,然後對其執行緒(Node)進行了喚醒,這時就只有一個或合理個數的執行緒被喚醒,被喚醒的執行緒繼續進行對資源的獲取與爭奪。
回顧整個資源的獲取和釋放過程:
在獲取時,維護了一個sync佇列,每個節點都是一個執行緒在進行自旋,而依據就是自己是否是首節點的後繼並且能夠獲取資源;
在釋放時,僅僅需要將資源還回去,然後通知一下後繼節點並將其喚醒。
這裡需要注意,佇列的維護(首節點的更換)是依靠消費者(獲取時)來完成的,也就是說在滿足了自旋退出的條件時的一刻,這個節點就會被設定成為首節點。
protected boolean tryAcquire(int arg)
tryAcquire是自定義同步器需要實現的方法,也就是自定義同步器非阻塞原子化的獲取狀態,如果鎖該方法一般用於Lock的tryLock實現中,這個特性是synchronized無法提供的。
public final void acquireInterruptibly(int arg)
該方法提供獲取狀態能力,當然在無法獲取狀態的情況下會進入sync佇列進行排隊,這類似acquire,但是和acquire不同的地方在於它能夠在外界對當前執行緒進行中斷的時候提前結束獲取狀態的操作,換句話說,就是在類似synchronized獲取鎖時,外界能夠對當前執行緒進行中斷,並且獲取鎖的這個操作能夠響應中斷並提前返回。一個執行緒處於synchronized塊中或者進行同步I/O操作時,對該執行緒進行中斷操作,這時該執行緒的中斷標識位被設定為true,但是執行緒依舊繼續執行。
如果在獲取一個通過網路互動實現的鎖時,這個鎖資源突然進行了銷燬,那麼使用acquireInterruptibly的獲取方式就能夠讓該時刻嘗試獲取鎖的執行緒提前返回。而同步器的這個特性被實現Lock介面中的lockInterruptibly方法。根據Lock的語義,在被中斷時,lockInterruptibly將會丟擲InterruptedException來告知使用者。
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
// 檢測中斷標誌位
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
上述邏輯主要包括:
1. 檢測當前執行緒是否被中斷;
判斷當前執行緒的中斷標誌位,如果已經被中斷了,那麼直接丟擲異常並將中斷標誌位設定為false。
2. 嘗試獲取狀態;
呼叫tryAcquire獲取狀態,如果順利會獲取成功並返回。
3. 構造節點並加入sync佇列;
獲取狀態失敗後,將當前執行緒引用構造為節點並加入到sync佇列中。退出佇列的方式在沒有中斷的場景下和acquireQueued類似,當頭結點是自己的前驅節點並且能夠獲取到狀態時,即可以執行,當然要將本節點設定為頭結點,表示正在執行。
4. 中斷檢測。
在每次被喚醒時,進行中斷檢測,如果發現當前執行緒被中斷,那麼丟擲InterruptedException並退出迴圈。
private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException
該方法提供了具備有超時功能的獲取狀態的呼叫,如果在指定的nanosTimeout內沒有獲取到狀態,那麼返回false,反之返回true。可以將該方法看做acquireInterruptibly的升級版,也就是在判斷是否被中斷的基礎上增加了超時控制。
針對超時控制這部分的實現,主要需要計算出睡眠的delta,也就是間隔值。間隔可以表示為nanosTimeout = 原有nanosTimeout – now(當前時間)+ lastTime(睡眠之前記錄的時間)。如果nanosTimeout大於0,那麼還需要使當前執行緒睡眠,反之則返回false。
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
long lastTime = System.nanoTime();
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
if (nanosTimeout <= 0) return false; if (shouldParkAfterFailedAcquire(p, node) && nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
long now = System.nanoTime();
//計算時間,當前時間減去睡眠之前的時間得到睡眠的時間,然後被
//原有超時時間減去,得到了還應該睡眠的時間
nanosTimeout -= now - lastTime;
lastTime = now;
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
上述邏輯主要包括:
1. 加入sync佇列;
將當前執行緒構造成為節點Node加入到sync佇列中。
2. 條件滿足直接返回;
退出條件判斷,如果前驅節點是頭結點並且成功獲取到狀態,那麼設定自己為頭結點並退出,返回true,也就是在指定的nanosTimeout之前獲取了鎖。
3. 獲取狀態失敗休眠一段時間;
通過LockSupport.unpark來指定當前執行緒休眠一段時間。
4. 計算再次休眠的時間;
喚醒後的執行緒,計算仍需要休眠的時間,該時間表示為nanosTimeout = 原有nanosTimeout – now(當前時間)+ lastTime(睡眠之前記錄的時間)。其中now – lastTime表示這次睡眠所持續的時間。
5. 休眠時間的判定。
喚醒後的執行緒,計算仍需要休眠的時間,並無阻塞的嘗試再獲取狀態,如果失敗後檢視其nanosTimeout是否大於0,如果小於0,那麼返回完全超時,沒有獲取到鎖。 如果nanosTimeout小於等於1000L納秒,則進入快速的自旋過程。那麼快速自旋會造成處理器資源緊張嗎?結果是不會,經過測算,開銷看起來很小,幾乎微乎其微。Doug Lea應該測算了線上程排程器上的切換造成的額外開銷,因此在短時1000納秒內就讓當前執行緒進入快速自旋狀態,如果這時再休眠相反會讓nanosTimeout的獲取時間變得更加不精確。
上述過程可以如下圖所示:

上述這個圖中可以理解為在類似獲取狀態需要排隊的基礎上增加了一個超時控制的邏輯。每次超時的時間就是當前超時剩餘的時間減去睡眠的時間,而在這個超時時間的基礎上進行了判斷,如果大於0那麼繼續睡眠(等待),可以看出這個超時版本的獲取狀態只是一個近似超時的獲取狀態,因此任何含有超時的呼叫基本結果就是近似於給定超時。
public final void acquireShared(int arg)
呼叫該方法能夠以共享模式獲取狀態,共享模式和之前的獨佔模式有所區別。以檔案的檢視為例,如果一個程式在對其進行讀取操作,那麼這一時刻,對這個檔案的寫操作就被阻塞,相反,這一時刻另一個程式對其進行同樣的讀操作是可以進行的。如果一個程式在對其進行寫操作,那麼所有的讀與寫操作在這一時刻就被阻塞,直到這個程式完成寫操作。
以讀寫場景為例,描述共享和獨佔的訪問模式,如下圖所示:

上圖中,紅色代表被阻塞,綠色代表可以通過。
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0) doAcquireShared(arg); } private void doAcquireShared(int arg) { final Node node = addWaiter(Node.SHARED); boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head) { int r = tryAcquireShared(arg); if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
上述邏輯主要包括:
1. 嘗試獲取共享狀態;
呼叫tryAcquireShared來獲取共享狀態,該方法是非阻塞的,如果獲取成功則立刻返回,也就表示獲取共享鎖成功。
2. 獲取失敗進入sync佇列;
在獲取共享狀態失敗後,當前時刻有可能是獨佔鎖被其他執行緒所把持,那麼將當前執行緒構造成為節點(共享模式)加入到sync佇列中。
3. 迴圈內判斷退出佇列條件;
如果當前節點的前驅節點是頭結點並且獲取共享狀態成功,這裡和獨佔鎖acquire的退出佇列條件類似。
4. 獲取共享狀態成功;
在退出佇列的條件上,和獨佔鎖之間的主要區別在於獲取共享狀態成功之後的行為,而如果共享狀態獲取成功之後會判斷後繼節點是否是共享模式,如果是共享模式,那麼就直接對其進行喚醒操作,也就是同時激發多個執行緒併發的執行。
5. 獲取共享狀態失敗。
通過使用LockSupport將當前執行緒從執行緒排程器上摘下,進入休眠狀態。
對於上述邏輯中,節點之間的通知過程如下圖所示:

上圖中,綠色表示共享節點,它們之間的通知和喚醒操作是在前驅節點獲取狀態時就進行的,紅色表示獨佔節點,它的被喚醒必須取決於前驅節點的釋放,也就是release操作,可以看出來圖中的獨佔節點如果要執行,必須等待前面的共享節點均釋放了狀態才可以。而獨佔節點如果獲取了狀態,那麼後續的獨佔式獲取和共享式獲取均被阻塞。
public final boolean releaseShared(int arg)
呼叫該方法釋放共享狀態,每次獲取共享狀態acquireShared都會操作狀態,同樣在共享鎖釋放的時候,也需要將狀態釋放。比如說,一個限定一定數量訪問的同步工具,每次獲取都是共享的,但是如果超過了一定的數量,將會阻塞後續的獲取操作,只有當之前獲取的消費者將狀態釋放才可以使阻塞的獲取操作得以執行。
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
上述邏輯主要就是呼叫同步器的tryReleaseShared方法來釋放狀態,並同時在doReleaseShared方法中喚醒其後繼節點。
一個例子
在上述對同步器AbstractQueuedSynchronizer進行了實現層面的分析之後,我們通過一個例子來加深對同步器的理解:
設計一個同步工具,該工具在同一時刻,只能有兩個執行緒能夠並行訪問,超過限制的其他執行緒進入阻塞狀態。
對於這個需求,可以利用同步器完成一個這樣的設定,定義一個初始狀態,為2,一個執行緒進行獲取那麼減1,一個執行緒釋放那麼加1,狀態正確的範圍在[0,1,2]三個之間,當在0時,代表再有新的執行緒對資源進行獲取時只能進入阻塞狀態(注意在任何時候進行狀態變更的時候均需要以CAS作為原子性保障)。由於資源的數量多於1個,同時可以有兩個執行緒佔有資源,因此需要實現tryAcquireShared和tryReleaseShared方法,這裡謝謝luoyuyou和同事小明指正,已經修改了實現。
public class TwinsLock implements Lock {
private final Sync sync = new Sync(2);
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = -7889272986162341211L;
Sync(int count) {
if (count <= 0) {
throw new IllegalArgumentException("count must large than zero.");
}
setState(count);
}
public int tryAcquireShared(int reduceCount) {
for (;;) {
int current = getState();
int newCount = current - reduceCount;
if (newCount < 0 || compareAndSetState(current, newCount)) {
return newCount;
}
}
}
public boolean tryReleaseShared(int returnCount) {
for (;;) {
int current = getState();
int newCount = current + returnCount;
if (compareAndSetState(current, newCount)) {
return true;
}
}
}
}
public void lock() {
sync.acquireShared(1);
}
public void lockInterruptibly() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public boolean tryLock() {
return sync.tryAcquireShared(1) >= 0;
}
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireSharedNanos(1, unit.toNanos(time));
}
public void unlock() {
sync.releaseShared(1);
}
@Override
public Condition newCondition() {
return null;
}
}
這裡我們編寫一個測試來驗證TwinsLock是否能夠正常工作並達到預期。
public class TwinsLockTest {
@Test
public void test() {
final Lock lock = new TwinsLock();
class Worker extends Thread {
public void run() {
while (true) {
lock.lock();
try {
Thread.sleep(1000L);
System.out.println(Thread.currentThread());
Thread.sleep(1000L);
} catch (Exception ex) {
} finally {
lock.unlock();
}
}
}
}
for (int i = 0; i < 10; i++) {
Worker w = new Worker();
w.start();
}
new Thread() {
public void run() {
while (true) {
try {
Thread.sleep(200L);
System.out.println();
} catch (Exception ex) {
}
}
}
}.start();
try {
Thread.sleep(20000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
上述測試用例的邏輯主要包括:
1. 列印執行緒
Worker在兩次睡眠之間列印自身執行緒,如果一個時刻只能有兩個執行緒同時訪問,那麼打印出來的內容將是成對出現。
2. 分隔執行緒
不停的列印換行,能讓Worker的輸出看起來更加直觀。
該測試的結果是在一個時刻,僅有兩個執行緒能夠獲得到鎖,並完成列印,而表象就是列印的內容成對出現。
