
Spring , Hadoop, Spark , BI , ML
Flume是一個分散式的、可靠的資料收集、集合和移動的元件。基於流式資料模型,非常健壯、支援容錯、故障轉移等特性。本用例項輔助說明Flume的大部分核心概念。
版本記錄:
2016-07-23 初稿
安裝FLume
Flume的安裝非常簡單,其核心就是agent。
從官網下載穩定版本:
wget http://apache.fayea.com/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
tar zxvf apache-flume-1.6.0-bin.tar.gz
mv apache-flume-1.6.0-bin apache-flume-1.6 為了執行方便,我們把bin目錄加到Path中:
vim /etc/profile
export FLUME_HOME=/opt/flume/apache-flume-1.6.0
export PATH=$PATH:$FLUME_HOME/bin
source /etc/profile測試一下是否安裝成功:
flume-ng help
入門例子
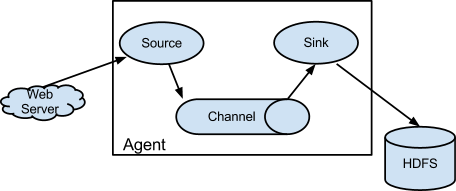
Flume的核心工作都是通過Flume Agent來完成的,Flume agent是一個長期執行的Java程序,其中執行著source和sink,source和sink之間通過channel連線。source作為生產者,產生資料,輸送到channel,sink從則從channel中讀取資料,並儲存到HDFS之類的資料目的地。Flume中自帶了非常豐富的各個元件實現。例如從目錄中拉取新檔案資料的spool source,收集執行命令輸出結果的exec source。channel的實現由記憶體memory,檔案file channel等。sink有簡單的logger輸出,HDFS sink,avro sink等。
資料在Flume中用事件event來表示,因此一個執行中的Flume agent就是一個event的流動系統,由source產生,傳送到channel,再傳送到sink用於儲存或者下一步處理。
多個Flume Agent可以相互連線構成一個拓撲圖,從而提供穩定的、高吞吐的資料收集系統。因此Flume系統中,核心是配置。使用Flume提供的豐富元件,構成滿足自己需求的系統。如果原生元件不足以滿足需求,完全可以擴充套件自己需要的元件,Flume提供了非常好的拓展點。
Agent的示意圖如下:
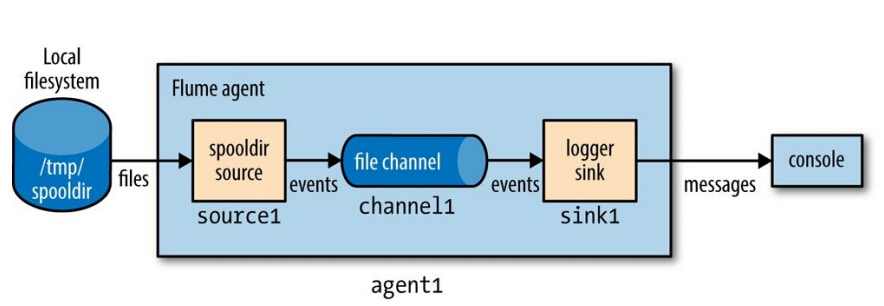
假設我們現在想監控/tmp/spooldir目錄下的檔案變動,一旦有新增檔案後,讀取每一行,輸出到控制檯。我們首先配置一個名為test-agent.properties的檔案,內容如下:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels=channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/tmp/spooldir
agent1.sinks.sink1.type=logger
agent1.channels.channel1.type=file配置檔案的屬性名稱採用級聯的層次結構來設定各種屬性。我們採用Flume自帶的spooldir作為source,使用具有持久化特性的file channel以及簡單的logger sink。
接下來先建立監控的目錄:
mkdir /tmp/spooldir
````
使用flume-ng啟動agent:
<div class="se-preview-section-delimiter"></div>
flume-ng agent –conf-file /opt/flume/conf/spool-to-logger.properties –name agent1 –conf $FLUME_HOME/conf -Dflume.root.logger=INFO,console

日誌中主要是一些source sink的啟動資訊。
接著我們在在一個終端中,往/tmp/spooldir中新增一個檔案,為了儲存新增檔案的原子操作,我們先建立一個隱藏檔案:
<div class="se-preview-section-delimiter"></div>
echo “Hello Flume” > /tmp/spooldir/.file1.txt
然後使用原子性操作mv改變為可見檔案:
<div class="se-preview-section-delimiter"></div>
mv /tmp/spooldir/.file1.txt /tmp/spooldir/file1.txt
此時日誌中可以看到如下輸出:

成功。一行會被當做一個事件,我們寫入一行,所以控制檯收到一個事件的日誌。多行檔案的輸出類似:

body的輸出中是UTF-8編碼格式。成功處理完之後,file channel中的檔名添加了COMPLETE的字尾,表示該檔案已經處理過。
<div class="se-preview-section-delimiter"></div>
#事務與可靠性
Flume使用獨立的事務在source-channel和channel-sink之間傳送事件。在上面的例子中,只有當事件被成功提交到file channel之後,原始檔案才會被標記為完成(COMPLETE字尾)。類似的,從channel到logger輸出控制檯也封裝在事務中,如果某種原因導致無法輸出到控制檯,則事務回滾,事件資料依然儲存在file channel中。
file channel雖然提供了持久化,但是其效能較差,吞吐量會受到一定的限制。相反,memory channel則犧牲可靠性換取吞吐量,如果記憶體中的事件因為機器故障重啟而丟失,則這些事件無法恢復。
Flume在傳送事件時,保證至少一次到達(at-least-once),也就是說可能出現重複。例如,上述的spool source中,當重啟Agent之後,如果檔案在上次還沒有被標識為完成,可能提交了部分資料到channel,因此重啟後會重新處理這些未完成的檔案。如果上次處理過程中,有些資料已經輸出到控制檯,但是事務還沒有提交(在輸出之後以提交之間發生故障),則這些事件會被重試,重現重複。
如果需要精確的一次到達,可以使用exactly onece,要達到精確一次到達,需要使用兩階段提交協議,這樣的協議開銷非常昂貴。因此Flume區別於傳統的訊息中介軟體的一點在於其使用至少一次到達來達到高容量的併發。而傳統的訊息中介軟體一般採用精確的一次到達。很多場合中,完全可以在資料的其他處理環節中對重複的資料進行去重,通常是採用MapReduce或者Hive作業。
<div class="se-preview-section-delimiter"></div>
##批量處理
為了效率,Flume在一次事務中會嘗試批量讀取事件。這對於file channel的效能提升尤為明顯,因此一次在一次file channel的事務中,需要產生一次昂貴的fsync呼叫。例如,在上面提到的spool source中,可以使用batchSize屬性來配置一次讀取多少行。在Avro sink中,在呼叫RPC傳送事件給Avro source之前,也會嘗試讀取100個事件,然後再批量傳送。當然,如果沒有達到100個事件,不會阻塞。
<div class="se-preview-section-delimiter"></div>
#HDFS Sink
Flume最初的出發點就是用於收集大量資料到Hadoop儲存中。下面是一個HDFS sink的配置例如:
<div class="se-preview-section-delimiter"></div>
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.sinks.sink1.hdfs.filePrefix = events
agent1.sinks.sink1.hdfs.fileSuffix = .log
agent1.sinks.sink1.hdfs.inUsePrefix = _
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.channels.channel1.type = file
HDFS sink的sink 型別為hdfs,配置項包括檔案路徑,檔案字首字尾,檔案格式等。
正在處理但是還未完成的檔案會有一個.tmp字尾,正在處理的字首使用inUsePredix屬性設定,我們這裡設定為下劃線,在MapReduce作業中,會自動忽略下劃線開頭的檔案。一個典型的臨時檔案(未完成)名稱如_events.1386734789.log.tmp,其中的數字是HDFS Sink生成的時間戳。
檔案會一直處於開啟狀態,直到下面的任意條件滿足:
- 時間達到30秒(通過hdfs.rollInterval屬性配置)
- 達到hdfs.rollSize配置的大小(預設為1024位元組)
- 事件數量達到hdfs.rollCount配置的數量(預設為10)
當上述任意條件滿足之後,檔案被關閉,字首字尾被移除。新到來的時間寫入新的檔案,然後繼續上述過程。
HDFS sink使用執行agent的使用者名稱寫入HDFS,可以通過hdfs.proxyUser配置。
<div class="se-preview-section-delimiter"></div>
##分割槽與攔截器
大量的資料集經常會進行分割槽,使用時間來分割槽是很常見的一種形式,例如每天一個分割槽,然後MapReduce作業定期處理分割槽。通過設定HDFS Sink的Path,很容易對資料進行分割槽:
<div class="se-preview-section-delimiter"></div>
agent1.sinks.sink1.hdfs.path = /tmp/flume/year=%Y/month=%m/day=%d
上述配置按照天對資料進行分割槽。如果使用Hive,一樣可以對映到Hive中的分割槽和Buckets。
事件被寫入哪一個分割槽,根據事件頭部中的timestamp來判斷。預設情況下,事件頭部中沒有時間,但是可以配置一個時間攔截器來新增。Flume的攔截器(Interceptor)機制用於修改或者刪除事件資料,攔截器被繫結到source中,並在事件到達channel之前執行。下面的配置為source1添加了一個攔截器:
<div class="se-preview-section-delimiter"></div>
agent1.sources.source1.interceptors=interceptor1
agent1.sources.source1.interceptors.interceptor1.type=timestamp
這個時間戳是在agent機器上產生事件的時間戳,如果agent執行在大規模的agent拓撲中,資料HDFS的時間可能與時間產生的時間有較大差別。HDFS Sink提供了一個屬性用於配置使用資料到達HDFS的時間作為時間戳,這個屬性是```hdfs.userLocalTimeStamp```.
<div class="se-preview-section-delimiter"></div>
##檔案格式
通常情況下,使用二進位制儲存資料所需要的空間會比儲存為文字所需空間小。HDFS sink提供了hdfs.fileType用於控制檔案型別。
這個屬性預設為SequenceFile,這種檔案格式使用時間的時間戳作為LongWritable Key,然後沒有時間戳頭部,則使用當前時間。事件的body作為BytesWritable寫入到value。如果value要儲存為Text,可以將hdfs.writeFormar設定為Text。
如果要以Avro的檔案格式寫入資料,hdfs.fileType設定為DateStream。另外需要設定一個值為avro_event的serializer屬性(沒有hdfs.字首)。serializer.compressionCodec屬性用於設定壓縮。
<div class="se-preview-section-delimiter"></div>
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=/tmp/flume
agent1.sinks.sink1.hdfs.filePrefix=events
agent1.sinks.sink1.hdfs.fileSuffix=.avro
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.serializer=avro_event
agent1.sinks.sink1.hdfs.serializer.compressionCodec=snappy
一個事件將被轉化為一條Avro記錄,這個記錄中有2個filed:headers和body。headers是一個字串Avro Map,body則為Avro Bytes。avro記錄的schema也可以自定義。
如果要將記憶體中的Avro 物件傳送到Flume,可以選擇使用Log4jAppender,這個Appender允許我們將Avro的通用物件或者特定物件(generic,specifix)寫入到日誌中,然後傳送到Avro Source(充當Avro RPC Server)。此時serializer的值要設為:
<div class="se-preview-section-delimiter"></div>
org.apache.flume.sink.hdfs.AvroEventSerializer$Builder
Avro schema在header中設定。如果要將其他物件轉化為Avro物件(進而傳送給Avro Source),可以通過實現AbstractAvroEventSerializer來完成。
<div class="se-preview-section-delimiter"></div>
#Fan Out
Fan out(扇出)是指一個source的資料被傳送給多個channel。事件發生時,同時傳送給多個channel,進而到達多個sink(一個sink只能對應一個channel)。例如我們想把資料傳到HDFS進行存檔,同時想把資料放到Solr或者ElasticSearch進行搜尋,此時可以給source配置兩個channel:
<div class="se-preview-section-delimiter"></div>
agent.sources.source1.channels=filechannel solrchannel
下圖是同時傳送到file channel和memory的示意圖:

當一個source配置有多個channel時,Flume針對每個channel使用單獨的事務進行資料傳送。在上面的例子中,Flume將使用一個事務把資料從spool目錄傳送到file channel。另一個memory channel則使用另一個事務。如果兩個事務都失敗(例如因為空間不足),則事件不會從source中移除,而是繼續保留在source,稍後再重試。
如果我們對某個channel的資料完整性比較不在乎,例如上述的logger sink,我們不太關心其資料可靠性,因此我們可以把這個channel配置為可選的:
<div class="se-preview-section-delimiter"></div>
agent1.sources.source1.selector.optional = memorychannel
此時,如果memory channel對應的事務失敗了,則事件不會被留在source被在稍後重試,而是忽略掉optional channel的事務失敗,把事件從source中移除。
在正常的fan-out模式中,事件被複制到所有的channel,但是Flume還提供了更靈活的選擇。所以我們可以把某些事件傳送到channela,把另一個型別的事件傳送到channelb。要達到這種多路複用的效果,可以使用multiplexing selector設定source,使得我們可以精確定義事件到channel的路由或者對映關係。
<div class="se-preview-section-delimiter"></div>
#分散式Agent拓撲
當我們有多個數據源時,在把資料送到類似HDFS的儲存之前,我們可能想先做一次聚合或者預處理。例如,如果資料要存到HDFS中供MapReduce作業處理,如果資料以無數的小檔案存在,對MapReduce的效能是極不利的。因此我們可以在資料原始來源處部署Agent,然後多個來源的資料先做一個去重和聚合,組成比較大的檔案,然後再彙總到HDFS。此時Agent之間是分層的:

上圖中,tier2對tier1的資料進行聚合,他們之間的連線通過tier1一個特殊的sink和tier2一個特殊的source完成。tier1使用Avro sink通過RPC將事件遠端傳送給位於tier2的Avro source。此時tier1的sink充當的是RPC的客戶端呼叫,tier2Avro source則充當RPC Server。
注意這裡的Avro sink和source並沒有讀寫Avro檔案的能力,它們之間只是使用AVRO RPC作為通訊協議,傳輸事件。如果需要使用sink把資料寫入到Avro檔案中,則需要使用類似HDFS的sink來完成。
第一層的agent配置如下:
<div class="se-preview-section-delimiter"></div>
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = avro
agent1.sinks.sink1.hostname = localhost
agent1.sinks.sink1.port = 10000
agent1.channels.channel1.type = file
agent1.channels.channel1.checkpointDir=/tmp/agent1/file- channel/checkpoint
agent1.channels.channel1.dataDirs=/tmp/agent1/file- channel/data
第二層agent配置如下:
<div class="se-preview-section-delimiter"></div>
agent2.sources = source2
agent2.sinks = sink2
agent2.channels = channel2
agent2.sources.source2.channels = channel2
agent2.sinks.sink2.channel = channel2
agent2.sources.source2.type = avro
agent2.sources.source2.bind = localhost
agent2.sources.source2.port = 10000
agent2.sinks.sink2.type = hdfs
agent2.sinks.sink2.hdfs.path = /tmp/flume
agent2.sinks.sink2.hdfs.filePrefix = events
agent2.sinks.sink2.hdfs.fileSuffix = .log
agent2.sinks.sink2.hdfs.fileType = DataStream
agent2.channels.channel2.type = file
agent2.channels.channel2.checkpointDir=/tmp/agent2/file- channel/checkpoint
agent2.channels.channel2.dataDirs=/tmp/agent2/file- channel/data
最後的結構圖如下:

在Flume Agent中,分別使用不同的事務在source-channel和channel-sink之間傳遞事件,保證事件的可靠傳遞。在Avro Source-Sink的情況下,Flume也使用事務能確保事件可靠地從Avro sink傳輸到Avto source並且寫入channel。
在agent1中,Avro Sink從channel中讀取事件(批次),並且傳送給agent1的source,這一整個邏輯被包含在一個事務中,只有當sink收到來自agent2 Avro Source的確認訊息之後,才會提交事務。訊息確認採用非同步機制。
在agent2中,Avro source讀取來自agent1的事件,並寫入到channel的邏輯也封裝在一個事務中,只有當資料確保寫入channel之後,才會向agent1傳送確認訊息。從而確保事件從一個agent的channel可靠傳送到另一個agent的channel。
在這樣的架構中,agent1和agent2只要其中一個出現故障,資料就無法被傳送到HDFS。為了解決這個問題,可以使用下一節中的Sink group來達到故障轉移。
<div class="se-preview-section-delimiter"></div>
#Sink Group
Sink group在邏輯上封裝一組sink,使用時(與Channel配合時)當做一個sink使用。利用sink group,可以達到負載均衡、故障轉移等目的。例如,下圖中的兩個tier2 agent被封裝成成一個sink group,當其中一個不可用時,資料被髮往另一個,避免全部中斷。

看一個sink group的配置:
<div class="se-preview-section-delimiter"></div>
agent1.sources = source1
agent1.sinks =sink1a sink1b
group
agent1.sinkgroups= sinkgroup1
agent1.channels = channel1
link
agent1.sources.source1.channels= channel1
agent1.sinks.sink1a.channel=channel1
agent1.sinks.sink1b.channel=channel1
sink group
agent1.sinkgroups.sinkgroup1.sinks=sink1a sink1b
agent1.sinkgroups.sinkgroup1.processor.type=load_balance
agent1.sinkgroups.sinkgroup1.processor.backoff=true
source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/tmp/spooldir
sink1a
agent1.sinks.sink1a.type=avro
agent1.sinks.sink1a.hostname=slave1
agent1.sinks.sink1a.port=10000
sink1b
agent1.sinks.sink1b.type=avro
agent1.sinks.sink1b.hostname=slave1
agent1.sinks.sink1b.port=10001
channel1
agent1.channels.channel1.type=file
agent1.channels.chennel1.checkpointDir=/opt/flume/checkpoint/agent1/file-channel/checkpoint
agent1.channels.channel1.dataDir=/opt/flume/data/agent1/file-channel/data
上述配置中,我們配置了2個sink共享一個file channel,並使用avro將資料傳遞到下一級agent。這些都是常規配置,除此之外,我們為agent定義了sink group:
<div class="se-preview-section-delimiter"></div>
agent1.sinkgroups= sinkgroup1
以及相應的sink group屬性。這個group包含sink1a和sink1b,type配置為load_balance,Flume事件將被負載均衡到這兩個sink,預設採用round-robin決定事件應該傳送到哪一個sink,如果sink1a不可用,則發往sink1b,如果兩個都不用,則事件保留在file channel。負載均衡的策略可以通過processor.selector來修改。
預設情況下,sink的不可用是不會被processor記住的,如果這一次sink1a不可用,下一批事件的時候,還會再次嘗試sink1a,這可能導致效率很低。因此,我們配置了processor.backoff=true,當某個sink不可用時,就會被加入黑名單列表中,一定時間之後再從黑名單中移除,繼續被嘗試。黑名單的最長有效期通過processor.selector.maxTimeOut配置。
另一種processor的型別是failover,這種型別的sink group,事件被髮送到一個優先的sink,如果這個優先的sink不可用,則切換到備用的sink。failover sink processor在組內維護一個優先順序順序,分發事件時,按照優先順序從高到低依次分發直到有可用的sink。不可用的sink將被暫時加入黑名單,時間通過processor.maxpenalty配置,最長30秒。
在下一級agent中,我們再10000和10001埠分配配置兩個avro source。agent2a的配置如下:
<div class="se-preview-section-delimiter"></div>
agent2a.sources=source2a
agent2a.sinks = sink2a
agent2a.channels = channel2a
agent2a.sources.source2a.channels =channel2a
agent2a.sinks.sink2a.channel=channel2a
agent2a.sources.source2a.type=avro
agent2a.sources.source2a.bind=slave1
agent2a.sources.source2a.port=10000
agent2a.sinks.sink2a.type=hdfs
agent2a.sinks.sink2a.hdfs.path=/tmp/flume
避免衝突
agent2a.sinks.sink2a.hdfs.filePrefix = events-a
agent2a.sinks.sink2a.hdfs.fileSuffix = .log
agent2a.sinks.sink2a.hdfs.fileType = DataStream
agent2a.channels.channel2a.type=file
agent2a.channels.chennel2a.checkpointDir=/opt/flume/checkpoint/agent2a/file-channel/checkpoint
agent2a.channels.channel2a.dataDir=/opt/flume/data/agent2a/file-channel/data
agent2b的配置完全類似:
<div class="se-preview-section-delimiter"></div>
agent2b.sources=source2b
agent2b.sinks = sink2b
agent2b.channels = channel2b
agent2b.sources.source2b.channels =channel2b
agent2b.sinks.sink2b.channel=channel2b
agent2b.sources.source2b.type=avro
agent2b.sources.source2b.bind=slave1
agent2b.sources.source2b.port=10001
agent2b.sinks.sink2b.type=hdfs
agent2b.sinks.sink2b.hdfs.path=/tmp/flume
避免衝突
agent2b.sinks.sink2b.hdfs.filePrefix = events-b
agent2b.sinks.sink2b.hdfs.fileSuffix = .log
agent2b.sinks.sink2b.hdfs.fileType = DataStream
agent2b.channels.channel2b.type=file
agent2b.channels.chennel2b.checkpointDir=/opt/flume/checkpoint/agent2b/file-channel/checkpoint
agent2b.channels.channel2b.dataDir=/opt/flume/dataagent2b/file-channel/data
配置了hdfs的檔案字首,是為了避免兩個agent同時寫入的時候出現衝突。如果二級的agent部署在不同的機器上,可以配置一個hostname攔截器,然後使用hostname作為檔案字首:
<div class="se-preview-section-delimiter"></div>
agent2a.sinks.sink2a.hdfs.filePrefix=event-%{host}
最終整個示意圖如下:

OK,我們在真實環境中執行一下這個系統:
在/opt/fluem/conf目錄下放著我們剛才的三個屬性檔案:
<div class="se-preview-section-delimiter"></div>
spool-tier1.properties
spool-tier2-a.properties
spool-tier2-b.properties
啟動HDFS:
<div class="se-preview-section-delimiter"></div>
start-dfs.sh
使用jps確保正常啟動。
啟動tier2的agent:
<div class="se-preview-section-delimiter"></div>
flume-ng agent –conf-file /opt/flume/conf/spool-tier2-a.properties –name agent2a –conf $FLUME_HOME/conf -Dflume.root.logger=INFO,console
flume-ng agent –conf-file /opt/flume/conf/spool-tier2-a.properties –name agent2a –conf $FLUME_HOME/conf -Dflume.root.logger=INFO,console

啟動tier1的agent:
<div class="se-preview-section-delimiter"></div>
flume-ng agent –conf-file /opt/flume/conf/spool-tier1.properties –name agent1 –conf $FLUME_HOME/conf -Dflume.root.logger=INFO,console
“`
往/tmp/spooldir目錄新增檔案。可以在日誌中看到,正常情況下,agent2a和agent2b採用round-robin方式輪流,如果我們退出其中的agent2a,則此時負載全部落到agent2b上。
在應用中基礎Flume
Avro Source作為一個RPC Server,可以接受RPC請求,所以可以寫客戶端程式往Avro Source傳送事件。
Flume SDK提供了Avro和Thrift Source的客戶端介面,通過這個SDK,很容易將事件傳送到Avro Source或者Thrift Source。同時支援負載均衡、故障轉移等。
Flume嵌入式的Agent提供了類似的功能,它執行在一個Java引用程式中,可以通過其暴露的EmbeddedAgent物件傳送時間,事件的接受端目前只支援Avro。
Flume元件一覽
上文中只提到了Flume的部分元件,除此外還有很多元件可供使用和擴充套件,下表列出一些常見的元件:
| 類別 | 元件 | 描述 |
|---|---|---|
| Source | Avro | 監聽Avro RPC呼叫(來自Avro sink或者Flume SDK) |
| Source | Exec | 執行Unix命令,例如tail -f,並將標準輸出中的每一行轉化成一個事件,注意該source不保證傳送事件到channel |
| HTTP | 在埠上監聽,並通過可插拔的Handler將請求轉化為事件 | |
| JMS | 從JMS佇列或者topic讀取訊息,轉化為事件 | |
| Netcat | 監聽埠,每行文字轉化為事件 | |
| Sequencegenerator | 遞增生成序列號,用於測試 | |
| Spooling directory | 檢測目錄中新增檔案,把檔案中的每一行轉化為事件 | |
| Syslog | 從系統日誌中讀取每一行並轉化為事件 | |
| Thrift | 監聽埠,接受Thrift RPC呼叫(來自Thrift Sink或者FLume SDK) | |
| 對接Twitter的Straming API | ||
| Sink | Avro | 通過Avro RPC傳送事件到Avro Source |
| Elasticsearch | 按照Logstash的格式將事件寫入ES叢集 | |
| File roll | 將事件寫入本地檔案系統 | |
| HBase | 使用指定的serializer將事件寫入HBase | |
| HDFS | 以文字、序列檔案、Avro或者其他格式寫入事件到HDFS | |
| IRC | 傳送事件到IRC channel | |
| Logger | 使用SLF4J將事件輸出到日誌,測試用 | |
| Morphline(Solr) | 常用與載入資料到Solr,執行一系列Marphline命令 | |
| Null | 忽略事件 | |
| Thrift | 使用Thrift RPC傳送事件到Thrift Source | |
| Channel | File | 事件儲存在本地檔案 |
| JDBC | 事件寫入到嵌入式的Derby資料庫 | |
| Memory | 在記憶體佇列中儲存事件 | |
| Interceptor | Host | 新增agent所在的機器的host或者ip到事件頭部 |
| Morphline | 基於Morphline配置檔案過濾事件或者修改頭部 | |
| Regex extractor | 從事件body中提取匹配的表示式 | |
| Static | 設定固定的Header到事件 | |
| TimeStamp | 設定時間戳頭部 | |
| UUID | 設定id頭部 |
參考資料
- 《Hadoop權威指南》