
《C++ 併發程式設計》- 第1章 你好,C++的併發世界

本文是《C++ 併發程式設計》的第一章,感謝人民郵電出版社授權併發程式設計網發表此文,版權所有,請勿轉載。該書將於近期上市。
本章主要內容
- 何謂併發和多執行緒
- 為什麼要在應用程式中使用併發和多執行緒
- C++併發支援的發展歷程
- 一個簡單的C++多執行緒程式是什麼樣的
這是C++使用者的振奮時刻。距1998年初始的C++標準釋出13年後,C++標準委員會給予程式語言和它的支援庫一次重大的變革。新的C++標準(也被稱為C++11或C++0x)於2011年釋出並帶來了很多的改變,使得C++的應用更加容易並富有成效。
在C++11標準中一個最重要的新特性就是支援多執行緒程式。這是C++標準第一次在語言中承認多執行緒應用的存在,並在庫中為編寫多執行緒應用程式提供元件。這將使得在不依賴平臺相關擴充套件下編寫多執行緒C++程式成為可能,從而允許以有保證的行為來編寫可移植的多執行緒程式碼。這也恰逢程式設計師更多地尋求普遍的併發,特別是多執行緒程式,來提高應用程式的效能。
這本書講述的就是在C++程式設計中對多執行緒併發的使用,以及令其成為可能的C++語言特性和庫工具。我會以解釋併發和多執行緒的含義以及為什麼要在應用程式中使用併發開始。在快速繞行闡述為什麼在應用程式中會不使用併發之後,我會對C++中併發支援進行概述,並以一個簡單的C++併發例項結束這一章。具有開發多執行緒應用程式經驗的讀者可以跳過前面的小節。在隨後幾章會將涵蓋更多廣泛的例子,並且更深入地瞭解庫工具。本書最後附有多執行緒與併發全部的C++標準庫工具的深入參考。
那麼,什麼是併發(concurrency)和多執行緒(multithreading)?
1.1 什麼是併發
在最簡單和最基本的層面,併發是指兩個或更多獨立的活動同時發生。併發在生活中隨處可見;我們可以一邊走路一邊說話,也可以兩隻手同時作不同的動作,還有我們每個人都相互獨立地過我們的生活——我在游泳的時候你可以看球賽,等等。
1.1.1 計算機系統中的併發
當我們提到計算機術語的併發,我們指的是在單個系統裡同時執行多個獨立的活動,而不是順序地或是一個接一個地。這並不是新現象,多工作業系統通過任務切換允許一臺計算機在同一時間執行多個應用程式已司空見慣多年,一些高階的多處理器伺服器啟用真正的併發的時間更為長久。真正有新意的是增加計算機真正並行執行多工的普遍性,而不只是給人這種錯覺。
以前,大多數計算機都有一個處理器,具有單個處理單元或核心,至今許多臺式機器仍是這樣。這種計算機在某一時刻只可以真正執行一個任務,但它可以每秒切換任務許多次。通過做一點這個任務然後再做一點別的任務,看起來像是任務在並行發生。這就是任務切換(task switching
包含多個處理器的計算機用於伺服器和高效能運算任務已有多年,現在基於單個晶片上具有多於一個核心的處理器(多核心處理器)的計算機也成為越來越常見的桌上型電腦器。無論它們擁有多個處理器或一個多核處理器(或兩者兼具),這些計算機能夠真正的並行執行超過一個任務。我們稱之為硬體併發(hardware concurrency)。
圖1.1顯示了一個計算機處理恰好兩個任務時的理想情景,每個任務被分為10個相等大小的塊。在一個雙核機器(具有兩個處理核心)中,每個任務可以在各自的核心執行。在單核機器上做任務切換時,每個任務的塊交織進行。但它們也隔開了一位(圖中所示灰色分隔條的厚度大於雙核機器的分隔條);為了實現交織進行,該系統每次從一個任務切換到另一個時都得執行一次上下文切換(context switch),而這是需要時間的。為了執行上下文切換,作業系統必須得為當前執行的任務儲存CPU的狀態和指令指標,算出要切換到哪個任務,併為要切換到的任務重新載入處理器狀態。然後CPU可能要將新任務的指令和資料的記憶體載入到快取中,這可能阻止CPU執行任何指令,造成的進一步延遲。
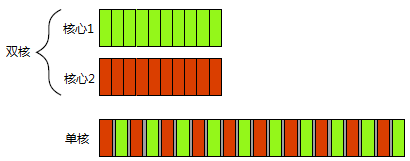
圖 1.1併發的兩種方式:雙核機器的並行執行對比單核機器的任務切換
儘管硬體併發的可用性在多處理器或多核系統上更顯著,有些處理器卻可以在一個核心上執行多個執行緒。要考慮的最重要的因素是硬體執行緒(hardware threads)的數量:即硬體可以真正併發執行多少獨立的任務。即便是具有真正硬體併發的系統,也很容易有超過硬體可並行執行的任務要執行,所以在這些情況下任務切換仍將被使用。例如,在一個典型的臺式計算機上可能會有幾百個的任務在執行,執行後臺操作,即使在計算機名義上是空閒的。正是任務切換使得這些後臺任務可以執行,並使得你可以同時執行文書處理器、編譯器、編輯器和web瀏覽器(或任何應用的組合)。圖1.2顯示了四個任務在一臺雙核機器上的任務切換,仍然是將任務整齊地劃分為同等大小塊的理想情況。實際上,許多因素會使得分割不均和排程不規則。這些因素中的一部分將涵蓋在第8章中,那時我們來看一看影響並行程式碼效能的因素。
所有的技術、功能和本書所涉及的類都可以被使用,無論你的應用程式是在單核處理器或多核處理器上執行,也不管是任務切換或是真正的硬體併發。但你可以想象,如何在你的應用程式中使用併發將很大程度上取決於可用的硬體併發。這將在第8章中涵蓋,在那裡我們具體研究C++程式碼並行設計問題。
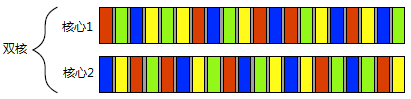
圖 1.2四個任務在兩個核心之間的切換
1.1.2 併發的途徑
想象一下兩個程式設計師一起做一個軟體專案。如果你的開發人員在獨立的辦公室,它們可以各自平靜地工作,而不會互相干擾,並且他們各有自己的一套參考手冊。然而,溝通起來就不那麼直接了;不能轉身然後互相交談,他們必須用電話、電子郵件或走到對方的辦公室。同時,你需要掌控兩個辦公室的開銷,還要購買多份參考手冊。
現在想象一下把開發人員移到同一間辦公室。他們現在可以地相互交談來討論應用程式的設計,他們也可以很容易的用紙或白板來繪製圖表,輔助闡釋設計思路。你現在只有一個辦公室要管理,只要一組資源就可以滿足。消極的一面是,他們可能會發現難以集中注意力,並且還可能存在資源共享的問題(“參考手冊跑哪去了?”)
組織開發人員的這兩種方法代表著併發的兩種基本途徑。每個開發人員代表一個執行緒,每個辦公室代表一個處理器。第一種途徑是有多個單執行緒的程序,這就類似讓每個開發人員在他們自己的辦公室,而第二種途徑是在單一程序裡有多個執行緒,這就類似在同一個辦公室裡有兩個開發人員。你可以隨意進行組合,並且擁有多個程序,其中一些是多執行緒的,一些是單執行緒的,但原理是一樣的。讓我們在一個應用程式中簡要地看一看這兩種途徑。
多程序併發
在一個應用程式中使用併發的第一種方法,是將應用程式分為多個、獨立的、單執行緒的程序,它們執行在同一時刻,就像你可以同時進行網頁瀏覽和文書處理。這些獨立的程序可以通過所有的常規的程序間通訊渠道互相傳遞消訊息(訊號、套接字、檔案、管道等等),如圖1.3所示。有一個缺點是這種程序之間的通訊通常設定複雜,或是速度較慢,或兩者兼備,因為作業系統通常在程序間提供了大量的保護,以避免一個程序不小心修改了屬於另一個程序的資料。另一個缺點是執行多個程序所需的固有的開銷:啟動程序需要時間,作業系統必須投入內部資源來管理程序,等等。
當然,也並不全是缺點:作業系統線上程間提供的附加保護操作和更高級別的通訊機制,意味著可以比執行緒更容易地編寫安全的併發程式碼。事實上,類似於為Erlang程式語言提供的環境,使用程序作為重大作用併發的基本構造快。
使用獨立的程序實現併發還有一個額外的優勢——你可以在通過網路連線的不同的機器上執行的獨立的程序。雖然這增加了通訊成本,但在一個精心設計的系統上,它可能是一個提高並行可用行和提高效能的低成本方法。
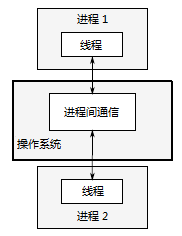
圖 1.3一對併發執行的程序之間的通訊
多執行緒併發
併發的另一個途徑是在單個程序中執行多個執行緒。執行緒很像輕量級的程序:每個執行緒相互獨立執行,且每個執行緒可以執行不同的指令序列。但程序中的所有執行緒都共享相同的地址空間,並且從所有執行緒中訪問到大部分資料——全域性變數仍然是全域性的,指標、物件的引用或資料可以線上程之間傳遞。雖然通常可以在程序之間共享記憶體,但這難以建立並且通常難以管理,因為同一資料的記憶體地址在不同的程序中也不盡相同。圖1.4顯示了一個程序中的兩個執行緒通過共享記憶體進行通訊。
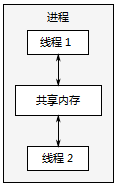
圖 1.4同一程序中的一對併發執行的執行緒之間的通訊
共享的地址空間,以及缺少執行緒間的資料保護,使得使用多執行緒相關的開銷遠小於使用多個程序,因為作業系統有更少的簿記要做。但是,共享記憶體的靈活性是有代價的:如果資料要被多個執行緒訪問,那麼程式設計師必須確保當每個執行緒訪問時所看到的資料是一致的。執行緒間資料共享可能會遇到的問題、所使用的工具以及為了避免問題而要遵循的指導方針在本書中都有涉及,特別是在第3、4、5和8章中。這些問題並非不可克服,只要在編寫程式碼時適當地注意即可,但這卻意味著必須對執行緒之間的通訊作大量的思考。
相比於啟動多個單執行緒程序並在其間進行通訊,啟動單一程序中的多執行緒並在其間進行通訊的開銷更低,這意味著若不考慮共享記憶體可能會帶來的潛在問題,它是包括C++在內的主流語言更青睞的併發途徑。此外,C++標準沒有為程序間通訊提供任何原生支援,所以使用多程序的應用程式將不得不依賴平臺相關的API來實現。因此,本書專門關注使用多執行緒的併發,並且之後提到併發均是假定通過使用多執行緒來實現的。
明確了什麼是併發後,現在讓我們來看看為什麼要在應用程式中使用併發。
1.2 為什麼使用併發?
在應用程式中使用併發的原因主要有兩個:關注點分離和效能。事實上,我甚至可以說它們差不多是使用併發的唯一原因;當你觀察的足夠仔細時,一切其他因素都可以歸結到這兩者之一(或者可能是二者兼有,當然,除了像“因為我願意”這樣的原因之外)。
1.2.1 為了關注點分離而使用併發
在編寫軟體時,關注點分離幾乎總是個好主意;通過將相關的程式碼放在一起並將無關的程式碼分開,可以使你的程式更容易理解和測試,從而減少出錯的可能性。你可以使用併發來分隔不同的功能區域,即使在這些不同功能區域的操作需要在同一時刻發生的窮況下;若不顯式地使用併發,你要麼被迫編寫任務切換框架,要麼在操作中主動地呼叫不相關的一段程式碼。
考慮一類帶有使用者介面的密集處理型應用程式,例如為臺式計算機提供的DVD播放程式。這樣一個應用程式基本上具備兩套職能:它不僅要從光碟中讀取資料,解碼影象和聲音,並把它們及時輸出至視訊和音訊硬體,從而實現DVD的無錯播放;它還要接受來自使用者的輸入,例如當用戶單擊暫停或返回選單甚至退出按鍵的時候。在單個執行緒中,應用程式須在回放期間定期檢查使用者的輸入,於是將將DVD回放程式碼和使用者介面程式碼合在一起。通過使用多執行緒來分隔這些關注點,使用者介面程式碼和DVD回放程式碼不再需要如此緊密的交織在一起;一個執行緒可以處理使用者介面,另一個處理DVD回放。它們之間會有互動,例如使用者點選暫停,但現在這些互動直接與眼前的任務有關。
這會帶來響應性的錯覺,因為使用者介面執行緒通常可以立即響應使用者的請求,即使在請求被傳達給幹活的執行緒時,響應為簡單地顯示正忙的游標或請等待的訊息。類似地,獨立的執行緒常被用於執行必須在後臺連續執行的任務,例如在桌面搜尋程式中監視檔案系統的變化。以這種方式使用執行緒一般會使每個執行緒的邏輯更加簡單,因為它們之間的互動可以被限制為清晰可辨的點,而不是到處散播不同任務的邏輯。
在這種情況下,執行緒的數量與CPU可用核心的數量無關,因為對執行緒的劃分是基於概念上的設計而不是試圖增加吞吐量。
1.2.2 為了效能而使用併發
多處理器系統已經存在了幾十年,但直到最近,他們幾乎只能在超級計算機、大型機和大型伺服器系統中才能看到。然而晶片製造商越來越傾向於多核晶片的設計,即在單個晶片上整合2、4、16或更多的處理器,從而達到比單核心更好的效能。因此,多核臺式計算機,甚至多核嵌入式裝置,現在越來越普遍。這些計算機的計算能力的提高不是源自使單一任務執行的更快,而是源自並行執行多個任務。在過去,程式設計師曾坐看他們的程式隨著處理器的更新換代而變得更快,無需他們這邊做出任何努力。但是現在,就像Herb Sutter所說的,“免費的午餐結束了。”[1]如果軟體想要利用日益增長的計算能力,它必須設計為併發執行多個任務。程式設計師因此必須留意,而且那些迄今都忽略併發的人們在必須注意它並將其加入他們的工具箱中。
有兩種方式為了效能使用併發。首先,也是最明顯的,是將一個單個任務分成幾部分且各自並行執行,從而降低總執行時間。這就是任務並行(task parallelism)。雖然這聽起來很直觀,但它可以是一個相當複雜的過程,因為在各個部分之間可能存在很多的依賴。區別可能是在過程方面——一個執行緒執行演算法的一部分而另一個執行緒執行演算法的另一個部分——或是在資料方面——每個執行緒在不同的資料部分上執行相同的操作。後一種方法被稱為資料並行(data parallelism)。
容易受這種並行影響的演算法常被稱為易並行(embarrassingly parallel)。拋開你可能會尷尬地面對很容易並行化的程式碼這一含義,這是一件好事情:我曾遇到過的關於此演算法的別的術語是自然並行(naturally parallel)和便利併發(conveniently concurrent)。易並行演算法具有良好的可擴充套件特性——隨著可用硬體執行緒數量的提升,演算法的並行性可以隨之增加與之匹配。這樣的一個演算法是諺語“人多力量大”的完美體現。對於非易並行演算法的那一部分,你可以將演算法劃分為一個固定(因而不可擴充套件)數量的並行任務。線上程之間劃分任務的技巧涵蓋在第8章中。
使用併發來提升效能的第二種方法是使用可用的並行方式來解決更大的問題;與其同時處理一個檔案,不如酌情處理2個或10個或20個。雖然這實際上只是資料並行的一種應用,通過對多組資料同時執行相同的操作,但還是有不同的重點。處理一個數據塊仍然需要同樣的時間,但在相同的時間內卻可以處理更多的資料。當然,這種方法也存在限制,且並非在所有情況下都是有益的,但是這種方法所帶來的吞吐量提升可以讓一些新玩意變得可能,例如,如果圖片的各部分可以並行處理,就能提高視訊處理的解析度。
1.2.3 什麼時候不使用併發
知道何時不使用併發與知道何時使用它一樣重要。基本上,不使用併發的唯一原因就是在收益比不上成本的時候。使用併發的程式碼在很多情況下難以理解,因此編寫和維護的多執行緒程式碼就有直接的腦力成本,同時額外的複雜性也可能導致更多的錯誤。除非潛在的效能增益足夠大或關注點分離地足夠清晰,能抵消確保其正確所需的額外的開發時間以及與維護多執行緒程式碼相關的額外成本,否則不要使用併發。
同樣地,效能增益可能不會如預期的那麼大;在啟動執行緒時存在固有的開銷,因為作業系統必須分配相關的核心資源和堆疊空間,然後將新執行緒加入排程器中,所有這一切都佔用時間。如果線上程上執行的任務完成得很快,那麼任務實際上佔據的時間與啟動執行緒的開銷時間相比顯得微不足道,可能會導致應用程式的整體效能還不如通過產生執行緒直接執行該任務。
此外,執行緒是有限的資源。如果讓太多的執行緒同時執行,則會消耗作業系統資源,並且使得作業系統整體上執行得更緩慢。不僅如此,執行太多的執行緒會耗盡程序的可用記憶體或地址空間,因為每個執行緒都需要一個獨立的堆疊空間。對於一個可用地址空間限制為4GB的扁平架構的32位程序來說,這尤其是個問題:如果每個執行緒都有一個1MB的堆疊(對於很多系統來說是典型的),那麼4096個執行緒將會用盡所有地址空間,不再為程式碼、靜態資料或者堆資料留有空間。雖然64位(或者更大)的系統不存在這種直接的地址空間限制,它們仍然只具備有限的資源:如果你執行太多的執行緒,最終會導致問題。儘管執行緒池(參見第9章)可以用來限制執行緒的數量,但這並不是靈丹妙藥,它們也有它們自己的問題。
如果客戶端/伺服器應用程式的伺服器端為每一個連結啟動一個獨立的執行緒,對於少量的連結是可以正常工作的,但當同樣的技術用於需要處理大量連結的高需求伺服器時,就會因為啟動太多執行緒而迅速耗盡系統資源。在這種場景下,謹慎地使用執行緒池可以提供優化的效能(參見第9章)。
最後,執行越多的執行緒,作業系統就需要做越多的上下文切換。每個上下文切換都需要耗費本可以花在有價值工作上的時間,所以在某些時候,增加一個額外的執行緒實際上會降低而不是提高應用程式的整體效能。為此,如果你試圖得到系統的最佳效能,考慮可用的硬體併發(或缺乏之)並調整執行執行緒的數量是必需的。
為了效能而使用併發就像所有其他優化策略一樣:它擁有極大提高應用程式效能的潛力,但它也可能使程式碼複雜化,使其更難理解和更容易出錯。因此,只有對應用程式中的那些具有顯著增益潛力的效能關鍵部分才值得這樣做。當然,如果效能收益的潛力僅次於設計清晰或關注點分離,可能也值得使用多執行緒設計。
假設你已經決定確實要在應用程式中使用併發,無論是為了效能、關注點分離,或是因為“多執行緒星期一”,對於C++程式設計師來說意味著什麼?
1.3 在C++中使用併發和多執行緒
通過多執行緒為併發提供標準化的支援對C++來說是新鮮事物。只有在即將到來的C++11標準中,你才能不依賴平臺相關的擴充套件來編寫多執行緒程式碼。為了理解新版本C++執行緒庫中眾多規則背後的基本原理,瞭解其歷史是很重要的。
1.3.1 C++多執行緒歷程
1998 C++標準版不承認執行緒的存在,並且各種語言要素的操作效果都以順序抽象機的形式編寫。不僅如此,記憶體模型也沒有被正式定義,所以對於1998 C++標準,你沒辦法在缺少編譯器相關擴充套件的情況下編寫多執行緒應用程式。
當然,編譯器供應商可以自由地向語言新增擴充套件,並且針對多執行緒的C API的流行——例如在POSIX C和Microsoft Windows API中的那些——導致很多C++編譯器供應商通過各種平臺相關的擴充套件來支援多執行緒。這種編譯器支援普遍地受限於只允許使用該平臺相應的C API以及確保該C++執行時庫(例如異常處理機制的程式碼)在多執行緒存在的情況下執行。儘管極少有編譯器供應商提供了一個正式的多執行緒感知記憶體模型,但編譯器和處理器的實際表現也已經足夠好,以至於大量的多執行緒的C++程式已被編寫出來。
由於不滿足於使用平臺相關的C API來處理多執行緒,C++程式設計師曾期望他們的類庫提供面向物件的多執行緒工具。像MFC這樣的應用程式框架,以及像Boost和ACE這樣的C++通用C++類庫曾積累了多套C++類,封裝了下層的平臺相關API並提供高階的多執行緒工具以簡化任務。各類庫的具體細節,特別是在啟動新執行緒的方面,存在很大差異,但是這些類的總體構造存在很多共通之處。有一個為許多C++類庫共有的,同時也是為程式設計師提供很大便利的特別重要的設計,就是帶鎖的資源獲得即初始化(RAII, Resource Acquisition Is Initialization)的習慣用法,來確保當退出相關作用域的時候互斥元被解鎖。
許多情況下,現有的C++編譯器所提供的多執行緒支援,例如Boost和ACE,綜合了平臺相關API以及平臺無關類庫的可用性,為編寫多執行緒C++程式碼提供一個堅實的基礎,也因此大約有數百萬行C++程式碼作為多執行緒應用程式的一部分而被編寫出來。但缺乏標準的支援,意味著存在缺少執行緒感知記憶體模型從而導致問題的場合,特別是對於那些試圖通過使用處理器硬體能力來獲取更高效能,或是編寫跨平臺程式碼但是在不同平臺之間編譯器的實際表現存在差異的情況。
1.3.2 新標準中的併發支援
所有這些都隨著新的C++11標準的釋出而改變了。不僅有了一個全新的執行緒感知記憶體模型,C++標準庫也被擴充套件了,包含了用於管理執行緒(參見第2章)、保護共享資料(參見第3章)、執行緒間同步操作(參見第4章)以及低階原子操作(參見第5章)的各個類。
新的C++執行緒庫很大程度上基於之前通過使用上文提到的C++類庫而積累的經驗。特別地,Boost執行緒庫被用作新類庫所基於的主要模型,很多類與Boost中的對應者共享命名和結構。在新標準演進的過程中,這是個雙向流動,Boost執行緒庫也改變了自己,以便在多個方面匹配C++標準,因此從Boost遷移過來的使用者將會發現自己非常習慣。
正如本章開篇提到的那樣,對併發的支援僅僅是新C++標準的變化之一,此外還存在很多對於程式語言自身的改善,可以使得程式設計師們的工作更便捷。這些內容雖然不在本書的論述範圍之內,但是其中的一些變化對於執行緒庫本身及其使用方式已經形成了直接的衝擊。附錄A對這些語言特性做了簡要的介紹。
C++中對原子操作的直接支援,允許程式設計師編寫具有確定語義的高效程式碼,而無需平臺相關的組合語言。這對於那些試圖編寫高效的、可移植程式碼的程式設計師們來說是一個真正的福利;不僅有編譯器可以搞定平臺的具體內容,還可以編寫優化器來考慮操作的語義,從而讓程式作為一個整體得到更好的優化。
1.3.3 C++執行緒庫的效率
對於C++整體以及包含低階工具的C++類——特別是在新版C++執行緒庫裡的那些,參與高效能運算的開發者常常關注的一點就是效率。如果你正尋求極致的效能,那麼理解與直接使用底層的低階工具相比,使用高階工具所帶來的實現成本,是很重要的。這個成本就是抽象懲罰(abstraction penalty)。
C++標準委員會在整體設計C++標準庫以及專門設計標準C++執行緒庫的時候,就已經十分注重這一點了;其設計的目標之一就是在提供相同的工具時,通過直接使用低階API就幾乎或完全得不到任何好處。因此該類庫被設計為在大部分主要平臺上都能高效實現(帶有非常低的抽象懲罰)。
C++標準委員會的另一個目標,是確保C++能提供足夠的低階工具給那些希望與硬體工作得更緊密的程式設計師,以獲取終極效能。為了達到這個目的,伴隨著新的記憶體模型,出現了一個全面的原子操作庫,用於直接控制單個位、位元組、執行緒間同步以及所有變化的可見性。這些原子型別和相應的操作現在可以在很多地方加以使用,而這些地方以前通常被開發者選擇下放到平臺相關的組合語言中。使用了新的標準型別和操作的程式碼因而具有更佳的可移植性,並且更易於維護。
C++標準庫也提供了更高級別的抽象和工具,它們使得編寫多執行緒程式碼更簡單和不易出錯。有時候運用這些工具確實會帶來效能成本,因為必須執行額外的程式碼。但是這種效能成本並不一定意味著更高的抽象懲罰;總體來看,這種效能成本並不比通過手工編寫等效的函式而招致的成本更高,同時編譯器可能會很好地內聯大部分額外的程式碼。
在某些情況下,高階工具提供超出特定使用需求的額外功能。在大部分情況下這都不是問題:你沒有為你不使用的那部分買單。在罕見的情況下,這些未使用的功能會影響其他程式碼的效能。如果你更看重程式的效能,且代價過高,你可能最好是通過較低級別的工具來手工實現需要的功能。在絕大多數情況下,額外增加的複雜性和出錯的機率遠大於小小的效能提升帶來的潛在收益。即使有證據確實表明瓶頸出現在C++標準庫的工具中,這也可能歸咎於低劣的應用程式設計而非低劣的類庫實現。例如,如果過多的執行緒競爭一個互斥元,這將會顯著影響效能。與其試圖在互斥操作上刮掉一點點的時間,還不如重新構造應用程式以減少互斥元上的競爭來的划算。設計應用程式以減少競爭會在第8章中加以闡述。
在非常罕見的情況下,C++標準庫不提供所需的效能或行為,這時則有必要運用使用平臺相關的工具。
1.3.4 平臺相關的工具
雖然C++執行緒庫為多執行緒和併發處理提供了頗為全面的工具,但是在所有的平臺上,都會有些額外的平臺相關工具。為了能方便的訪問那些工具而又不用放棄使用標準C++執行緒庫帶來的好處,C++執行緒庫中的型別可以提供一個native_handle()成員函式,允許通過使用平臺相關API直接操作底層實現。就其本質而言,任何使用native_handle()執行的操作是完全依賴於平臺的,這也超出了本書(同時也是標準C++庫本身)的範圍。
當然,在考慮使用平臺相關的工具之前,明白標準庫能夠提供什麼是很重要的,那麼讓我們通過一個例子來開始。
1.4 開始入門
好,現在你有一個很棒的與C++11相容的編譯器。接下來呢?一個多執行緒C++程式是什麼樣子的?它看上去和其他所有C++程式一樣,通常是變數、類以及函式的組合。唯一真正的區別在於某些函式可以併發執行,所以你需要確保共享資料的併發訪問是安全的,詳見第3章。當然,為了併發地執行函式,必須使用特定的函式以及物件來管理各個執行緒。
1.4.1 你好,併發世界
讓我們從一個經典的例子開始:一個列印“Hello World.”的程式。一個非常簡單的在單執行緒中執行的Hello, World程式如下所示,當我們談到多執行緒時,它可以作為一個基準。
1 #include <iostream> 2 int main() 3 { 4 std::cout << "Hello World\n"; 5 }
這個程式所做的一切就是將“Hello World”寫進標準輸出流。讓我們將它與下面清單所示的簡單的Hello, Concurrent World程式做個比較,它啟動了一個獨立的執行緒來顯示這個資訊。
清單 1.1一個簡單的Hello, Concurrent World程式
1 #include <iostream> 2 #include <thread> //① 3 void hello() //② 4 { 5 std::cout << "Hello Concurrent World\n"; 6 } 7 int main() 8 { 9 std::thread t(hello); //③ 10 t.join(); //④ 11 }
第一個區別是增加了#include<thread>①。在標準C++庫中對多執行緒支援的宣告在新的標頭檔案中:用於管理執行緒的函式和類在<thread>中宣告,而那些保護共享資料的函式和類在其他標頭檔案中宣告。
其次,寫資訊的程式碼被移動到了一個獨立的函式中②。這是因為每個執行緒都必須具有一個初始函式(initial function),新執行緒的執行在這裡開始。對於應用程式來說,初始執行緒是main(),但是對於所有其他執行緒,這在std::thread物件的建構函式中指定──在本例中,被命名為t③的std::thread物件擁有新函式hello()作為其初始函式。
下一個區別:與直接寫入標準輸出或是從main()呼叫hello()不同,該程式啟動了一個全新的執行緒來實現,將執行緒數量一分為二──初始執行緒始於main()而新執行緒始於hello()。
在新的執行緒啟動之後③,初始執行緒繼續執行。如果它不等待新執行緒結束,它就將自顧自地繼續執行到main()的結束,從而結束程式──有可能發生在新執行緒有機會執行之前。這就是為什麼在④這裡呼叫join()的原因──詳見第2章,這會導致呼叫執行緒(在main()中)等待與std::thread物件相關聯的執行緒,即這個例子中的t。
如果這看起來像是僅僅為了將一條資訊寫入標準輸出而做了大量的工作,那麼它確實如此──正如上文1.2.3節所描述的,一般來說並不值得為了如此簡單的任務而使用多執行緒,尤其是如果在這期間初始執行緒無所事事。在本書後面的內容中,我們將通過例項來展示在哪些情景下使用多執行緒可以獲得明確的收益。
1.5 小結
在本章中,我提及了併發與多執行緒的含義以及在你的應用程式中為什麼你會選擇使用(或不使用)它。我還提及了多執行緒在C++中的發展歷程,從1998標準中完全缺乏支援,經歷了各種平臺相關的擴充套件,再到新的C++11標準中具有合適的多執行緒支援。該支援到來的正是時候,它使得程式設計師們可以利用隨著新的CPU而帶來的更加強大的硬體併發,因為晶片製造商選擇了以多核心的形式使得更多工可以同時執行的方式來增加處理能力,而不是增加單個核心的執行速度。
我在1.4節中的示例,來展示了C++標準庫中的類和函式有多麼的簡單。在C++中,使用多執行緒本身並不複雜,複雜的是如何設計程式碼以實現其預期的行為。
在嘗試了1.4節的示例之後,是時候看看更多實質性的內容了。在第2章中,我們將看一看用於管理執行緒的類和函式。
[1] “The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software,” Herb Sutter, Dr. Dobb’s
Journal, 30(3), March 2005. http://www.gotw.ca/publications/concurrency-ddj.htm.
