
Redis Cluster遷移目標節點宕機下填坑
問題背景
應@冬洪兄邀請,讓我把最近在處理Redis Cluster中遇到的坑分享下,由於個人時間問題,大致整理了一個比較大,比較坑的問題,它可能會導致叢集部分slot不可用,甚至需要重建叢集。如果對redis cluster不瞭解的可以檢視redis原理分享。
架構圖如下
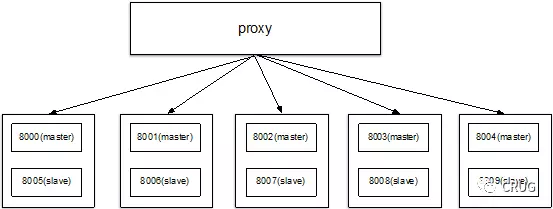

1. 遷移8000例項的資料到8001例項
2.此時kill掉8001例項模擬目標節點宕機

3.連線8000例項檢視cluster nodes發現8001例項已經fail,但是還負責槽166-234
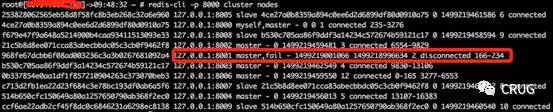
4.連線8002埠檢視cluster nodes發現8001例項已經fail,但是還負責槽166-234

5.連線8003埠檢視cluster nodes發現8001例項已經fail,但是還負責槽166-234
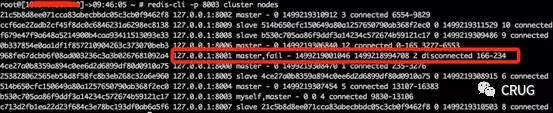
6. 連線8004埠檢視cluster nodes發現8001例項已經fail,但是還負責槽166-234
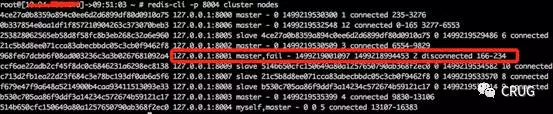
7. 連線8006埠(8001的slave升級為master)cluster nodes發現8001例項已經fail,但是槽166-234,在8000例項(源節點上)
問題-
8000例項遷移資料到8001例項
-
kill掉8001例項(目標節點)
-
發現8001機器從ok->fail, 但是仍然負責一部分槽號166-234
-
新的slave(8006)正常升級為master
-
8000例項:認為槽166-234在8001例項上
-
8002例項:認為槽166-234在8001例項上
-
8003例項:認為槽166-234在8001例項上
-
8004例項:認為槽166-234在8001例項上
-
8005例項:認為槽166-234在8001例項上
-
8006例項:認為槽166-234在8000例項上
說明:
只有宕機的8001例項的slave8006升級為master之後,認為槽166-234在(8000例項)源節點上,其他的master節點均認為該槽166-234在(8001例項)目標節點上。
修復步驟1.此時通過redis-trib.rbfix 127.0.0.1:8002,不成功,報錯如下

2.在8001例項(源節點)上強制把166-234指向自己,並且讓大家強制同意
cluster setslot 166 node4ce27a0b8359a894c0ee6d2d6899df80d0910a75
cluster setslot 234 node4ce27a0b8359a894c0ee6d2d6899df80d0910a75
cluster bumpepoch
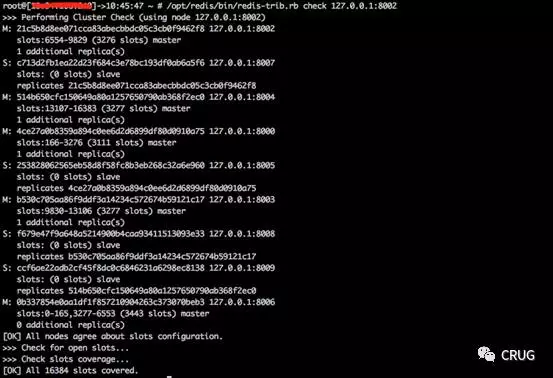
3.redis-trib.rb check叢集
1. 植入日誌列印slot->nodeid資訊cluster.c clusterUpdateSlotsConfWith函式

2.查詢部署的clusternodes(此時,已經模擬完遷移的時候,目標節點宕機)
3.分析8000例項日誌資訊142槽
4.分析8002例項日誌資訊142槽
5.分析8003例項日誌資訊142槽
6.分析8004例項日誌資訊142槽
7.分析8005例項日誌資訊142槽
8.分析8006例項日誌資訊142槽
9.分析8007例項日誌資訊142槽
10.分析8008例項 日誌資訊142槽
11.分析8009例項 日誌資訊142槽
說明:
遷移完的槽142, 除了8006例項(8001例項的slave升級為master的例項),其他所有的master節點都認為8001例項目標節點。
所有的slave節點和新的master例項8006都認為槽142在8000例項源節點。
總結由於遷移速度比較快,雖然遷移完畢了,但是也需要一段時間同步給其他節點。而這個資訊靠新的owner來同步,此時還沒來得及gossip訊息傳播。有可能遷移結束了, 但是這個槽資訊同步到了除了slave的所有節點上面。總體來說redis cluster問題還是不少的。
在擴容的時候也遇到過腦裂的請情況,投票各自佔一半的情況,最後也是通過手動強制指定slot來修復的。還有更多小問題就不細說了。