
Redis叢集的方案總結:客戶端Sharding/Redis Cluster/Proxy
一、Redis叢集
由於Redis出眾的效能,其在眾多的移動網際網路企業中得到廣泛的應用。Redis在3.0版本前只支援單例項模式,雖然現在的伺服器記憶體可以到100GB、200GB的規模,但是單例項模式限制了Redis沒法滿足業務的需求(例如新浪微博就曾經用Redis儲存了超過1TB的資料)。Redis的開發者Antirez早在部落格上就提出在Redis 3.0版本中加入叢集的功能,但3.0版本等到2015年才釋出正式版。各大企業在3.0版本還沒釋出前為了解決Redis的儲存瓶頸,紛紛推出了各自的Redis叢集方案。這些方案的核心思想是把資料分片(sharding)儲存在多個Redis例項中,每一片就是一個Redis例項。
二、再論一致性雜湊
三、Redis叢集的簡單方案:Redis Sharding
1. Redis Sharding
Redis Sharding可以說是Redis Cluster出來之前,業界普遍使用的多Redis例項叢集方法。其主要思想是採用雜湊演算法將Redis資料的key進行雜湊,通過hash函式,特定的key會對映到特定的Redis節點上。這樣,客戶端就知道該向哪個Redis節點操作資料。
客戶端分片是把分片的邏輯放在Redis客戶端實現,通過Redis客戶端預先定義好的路由規則,把對Key的訪問轉發到不同的Redis例項中,最後把返回結果彙集。這種方案的模式如圖1所示。

客戶端分片的好處是所有的邏輯都是可控
客戶端分片方案有下面這些缺點。
1. 這是一種靜態的分片方案,需要增加或者減少Redis例項的數量,需要手工調整分片的程式。
2. 可運維性差,叢集的資料出了任何問題都需要運維人員和開發人員一起合作,減緩了解決問題的速度,增加了跨部門溝通的成本。
3. 在不同的客戶端程式中,維護相同的分片邏輯成本巨大。例如,系統中有兩套業務系統共用一套Redis叢集,一套業務系統用Java實現,另一套業務系統用PHP實現。為了保證分片邏輯的一致性,在Java客戶端中實現的分片邏輯也需要在PHP客戶端實現一次。相同的邏輯在不同的系統中分別實現,這種設計本來就非常糟糕,而且需要耗費巨大的開發成本保證兩套業務系統分片邏輯的一致性。
2. Redis Sharding的擴容問題
Redis Sharding採用客戶端Sharding方式,服務端Redis還是一個個相對獨立的Redis例項節點,沒有做任何變動。同時,我們也不需要增加額外的中間處理元件,這是一種非常輕量、靈活的Redis多例項叢集方法。當然,Redis Sharding這種輕量靈活方式必然在叢集其它能力方面做出妥協。比如擴容,當想要增加Redis節點時,儘管採用一致性雜湊,畢竟還是會有key匹配不到而丟失,這時需要鍵值遷移。
作為輕量級客戶端sharding,處理Redis鍵值遷移是不現實的,這就要求應用層面允許Redis中資料丟失或從後端資料庫重新載入資料。但有些時候,擊穿快取層,直接訪問資料庫層,會對系統訪問造成很大壓力。有沒有其它手段改善這種情況?
Redis作者給出了一個比較討巧的辦法–presharding,即預先根據系統規模儘量部署好多個Redis例項,這些例項佔用系統資源很小,一臺物理機可部署多個,讓他們都參與sharding,當需要擴容時,選中一個例項作為主節點,新加入的Redis節點作為從節點進行資料複製。資料同步後,修改sharding配置,讓指向原例項的Shard指向新機器上擴容後的Redis節點,同時調整新Redis節點為主節點,原例項可不再使用。
這樣,我們的架構模式變成一個Redis節點切片包含一個主Redis和一個備Redis。在主Redis宕機時,備Redis接管過來,上升為主Redis,繼續提供服務。主備共同組成一個Redis節點,通過自動故障轉移,保證了節點的高可用性。則Sharding架構演變成:

3. Redis Sentinel模式實現故障轉移
Redis 2.8版開始正式提供名為Sentinel的主從切換方案,Sentinel用於管理多個Redis伺服器例項,主要負責三個方面的任務:
1. 監控(Monitoring): Sentinel 會不斷地檢查你的主伺服器和從伺服器是否運作正常。
2. 提醒(Notification): 當被監控的某個 Redis 伺服器出現問題時, Sentinel 可以通過 API 向管理員或者其他應用程式傳送通知。
3. 自動故障遷移(Automatic failover): 當一個主伺服器不能正常工作時, Sentinel 會開始一次自動故障遷移操作, 它會將失效主伺服器的其中一個從伺服器升級為新的主伺服器, 並讓失效主伺服器的其他從伺服器改為複製新的主伺服器; 當客戶端試圖連線失效的主伺服器時, 叢集也會向客戶端返回新主伺服器的地址, 使得叢集可以使用新主伺服器代替失效伺服器。
特殊狀態的Redis
一個Sentinel就是一個執行在特殊狀態下的Redis,以至於可以用啟動Redis Server的方式啟動Sentinel。不過Sentinel有自己的命令列表,它支援的命令不多。
配置Redis主節點,自動發現從節點
Sentinel執行起來後,會根據配置檔案的"sentinel monitor <master-name> <ip> <redis-port> <quorum>"去連線master,這裡我們把master-name下的所有節點看成一個group,一個group由一個master,若干個slave組成。Sentinel只需配置主節點的ip、port即可。Sentinel會通過向master傳送INFO命令來獲取master下的slave,然後把slave加入group。
自動發現監控同一個group的其他Sentinel
Sentinel連線Redis節點,會建立兩條對節點的連線,一條用來向節點發送命令,另一條用來訂閱“__sentinel__:hello”頻道(hello頻道)發來的訊息,這個頻道用做Gossip協議發現其他監控此Redis節點的Sentinel。每個Sentinel會定時向頻道傳送訊息,然後也會接收到其他Sentinel從hello頻道發來的訊息,訊息的格式如下:
sentinel_ip,sentinel_port,sentinel_runid,current_epoch,master_name,master_ip,master_port,master_config_epoch(127.0.0.1,26381,99ce8dc79e55ce9de040b0cd13d152900db9a7e1,24,mymaster2,127.0.0.1,8000,0)。推送訊息
Sentinel在監控Redis和其他Sentinel的時候,發現的異常以及完成的操作都會通過Publish的方式推送出去,客戶端想了解Sentinel的處理結果,只要訂閱相應的訊息型別即可。Sentinel使用的推送方式用的是Redis現有的Pub/Sub方式。Sentinel基本上會把它整個處理流程都推送出來,然而客戶端一般只要關注主從切換的訊息即可。
故障檢查
Sentinel會跟group的每個節點以及監控同一個group的其他Sentinel保持心跳,Sentinel會定時向這些節點發送Ping命令,然後等待Pong命令回覆。如果一段時間沒有收到Pong命令。Sentinel就會主觀的認為該節點離線。對於其他Sentinel和group內的slave掛了,Sentinel檢測到他們離線也不需要做什麼事情,只是簡單的推送一條+sdown的訊息。如果檢測到master離線,Sentinel就要確定是否需要進行主從切換。此時Sentinel會向其他Sentinel傳送is-master-down-by-addr命令(命令格式:SENTINEL IS-master-DOWN-BY-ADDR <ip> <port> <current-epoch> <runid>),這個命令有2個功能,這時候的用法是用來向其他節點獲取master是否離線的資訊。還有一個用法是用來選舉leader的,該命令會讓其他Sentinel給自己投票,已經投過票的Sentinel會返回投票的結果。Sentinel在監控group的時候會配置一個quorum,Sentinel接收到超過quorum個Sentinel認為master掛了(quorum包含自己),Sentinel就會認為該master是客觀下線了。接著Sentinel就進入了自動故障轉移狀態。
Sentinel間投票選leader
Sentinel認為master客觀下線了,就開始故障轉移流程,故障轉移的第一步就是競選leaderSentinel採用了Raft協議實現了Sentinel間選舉Leader的演算法,不過也不完全跟論文描述的步驟一致。Sentinel叢集執行過程中故障轉移完成,所有Sentinel又會恢復平等。Leader僅僅是故障轉移操作出現的角色。
故障轉移
Sentinel一旦確定自己是leader後,就開始從slave中選出一個節點來作為master。如果依據選擇流程沒有選出可用的slave,leader Sentinel會終止本次故障轉移。
如果選擇出了可用的slave,那麼leader Sentinel會給該slave傳送slaveof no one命令,表示該slave不再複製其他節點,成為了master。然後leader Sentinel就會一直等待選出slave的INFO資訊裡面確認了自己的master身份。如果等待超時了,leader Sentinel只得終止本次故障轉移。
如果選出的slave確認了自己的master身份,leader Sentinel會讓其他slave複製新的master,由於初次複製會帶來很大的IO開銷,Sentinel有個parallel_syncs引數,用來確定一次讓多少個slave複製新master。一個slave複製master如果超過10s,leader Sentinel會重新發送複製命令。如果在指定的故障轉移時間內還沒有完成全部的複製工作,leader
Sentinel就會忽略那些沒複製的slave。leader Sentinel只是向這些slave傳送一次複製命令,不等待他們複製成功就直接完成了全部故障轉移工作。
全部故障轉移工作完成後,leader Sentinel就會推送+switch-master訊息,同時重置master,重置操作會釋放掉原來master全部的slave物件和監聽該master的其他Sentinel物件,然後創建出新的slave物件。
客戶端處理流程
客戶端可以通過Sentinel獲得group的資訊。官方給出了客戶端操作的推薦方式。看了下Jedis的實現,基本就是按照官方的操作流程進行的。首先客戶端配置監聽該group的全部Sentinel。連線第一個Sentinel,如果連不上就重新連線下一個,直到連上一個Sentinel。
連上Sentinel後,傳送SENTINEL get-master-addr-by-name master-name命令可以得到該group的master,如果該Sentinel返回了null,那就重複上面的流程,重新連線下一個Sentinel。
得到group的master後,連上master,傳送ROLE命令,確認該master自身確實是作為master在執行。這個確認是必須的,如果Sentinel和group網路分割槽了,那麼該Sentinel認為的master就不會變化了,而group如果出現主從切換,此時Sentinel就拿不到真實的master了。如果ROLE得到的不再是master了,客戶端需要重複最前面的流程,重新連線下一個Sentinel。
確認好master的ROLE也是master後,客戶端可以從每個Sentinel上訂閱訊息。一般客戶端只要關心+switch-master即可,這個訊息會告訴客戶端發生了主從切換,並把新老master的ip、port都推送在訊息裡。客戶端根據新的master,傳送ROLE命令確認後,就可以和新的master通訊了。
有些客戶端希望把讀流量分給slave,那麼可以通過SENTINEL slaves master-name命令來獲得該group下的slave列表。
如果客戶端需要重連master,那麼建議按照初始化連線的方式重新從Sentinel獲取master。
如果採用連線池的方式,官方建議在每次有連線斷開需要重連的時候所有的連線都關閉,從而重建連線池。這麼做也是為了防止新的連接獲取的master跟原來不一致了。
客戶端還可以通過SENTINEL sentinels <master-name>命令更新自己的Sentinel列表,從而獲得最新存活的Sentinel。
4. Jedis Sharding:ShardedJedis和ShardedJedisPool的使用
Java redis客戶端驅動jedis已支援Redis Sharding功能,即ShardedJedis以及結合快取池的ShardedJedisPool。
Jedis的Redis Sharding實現具有如下特點:
1、採用一致性雜湊演算法(consistent hashing),將key和節點name同時hashing,然後進行對映匹配,採用的演算法是MURMUR_HASH。採用一致性雜湊而不是採用簡單類似雜湊求模對映的主要原因是當增加或減少節點時,不會產生由於重新匹配造成的rehashing。一致性雜湊隻影響相鄰節點key分配,影響量小。
2.為了避免一致性雜湊隻影響相鄰節點造成節點分配壓力,ShardedJedis會對每個Redis節點根據名字(沒有,Jedis會賦予預設名字)會虛擬化出160個虛擬節點進行雜湊。根據權重weight,也可虛擬化出160倍數的虛擬節點。用虛擬節點做對映匹配,可以在增加或減少Redis節點時,key在各Redis節點移動再分配更均勻,而不是隻有相鄰節點受影響。
3.ShardedJedis支援keyTagPattern模式,即抽取key的一部分keyTag做sharding,這樣通過合理命名key,可以將一組相關聯的key放入同一個Redis節點,這在避免跨節點訪問相關資料時很重要。
ShardedJedis的使用方法除了配置時有點區別,其他和Jedis基本類似,有一點要注意的是 ShardedJedis不支援多命令操作,像mget、mset、brpop等可以在redis命令後一次性操作多個key的命令,具體包括哪些,大家可以看Jedis下的 MultiKeyCommands 這個類,這裡面就包含了所有的多命令操作。很貼心的是,Redis作者已經把這些命令從ShardedJedis過濾掉了,使用時也調用不了這些方法,大家知道下就行了。好了,現在來看基本的使用
//設定連線池的相關配置
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(2);
poolConfig.setMaxIdle(1);
poolConfig.setMaxWaitMillis(2000);
poolConfig.setTestOnBorrow(false);
poolConfig.setTestOnReturn(false);
//設定Redis資訊
String host = "127.0.0.1";
JedisShardInfo shardInfo1 = new JedisShardInfo(host, 6379, 500);
shardInfo1.setPassword("test123");
JedisShardInfo shardInfo2 = new JedisShardInfo(host, 6380, 500);
shardInfo2.setPassword("test123");
JedisShardInfo shardInfo3 = new JedisShardInfo(host, 6381, 500);
shardInfo3.setPassword("test123");
//初始化ShardedJedisPool
List<JedisShardInfo> infoList = Arrays.asList(shardInfo1, shardInfo2, shardInfo3);
ShardedJedisPool jedisPool = new ShardedJedisPool(poolConfig, infoList);
//進行查詢等其他操作
ShardedJedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.set("test", "test");
jedis.set("test1", "test1");
String test = jedis.get("test");
System.out.println(test);
......
} finally {
//使用後一定關閉,還給連線池
if(jedis!=null) {
jedis.close();
} 四、Redis叢集的折中方案:中介軟體實現的Redis叢集
1. Twemproxy
Twemproxy是一種代理分片機制,由Twitter開源。Twemproxy作為代理,可接受來自多個程式的訪問,按照路由規則,轉發給後臺的各個Redis伺服器,再原路返回。該方案很好的解決了單個Redis例項承載能力的問題。
當然,Twemproxy本身也是單點,需要用Keepalived做高可用方案。通過Twemproxy可以使用多臺伺服器來水平擴張redis服務,可以有效的避免單點故障問題。雖然使用Twemproxy需要更多的硬體資源和在redis效能有一定的損失(twitter測試約20%),但是能夠提高整個系統的HA也是相當划算的。不熟悉twemproxy的同學,如果玩過nginx反向代理或者mysql
proxy,那麼你肯定也懂twemproxy了。其實twemproxy不光實現了redis協議,還實現了memcached協議,什麼意思?換句話說,twemproxy不光可以代理redis,還可以代理memcached。

但是從上面我們可以看到這樣以來Twemproxy就成了單點,所以通常會結合keepalived來實現Twemproxy的高可用。架構圖如下:

上面的架構通常只有一臺Twemproxy在工作,另外一臺處於備機,當一臺掛掉以後,vip自動漂移,備機接替工作。
2. Codis
Codis是一個分散式的Redis解決方案(豌豆莢),對於上層的應用來說,連線Codis Proxy和連線原生的Redis Server沒有明顯的區別(不支援的命令列表),上層應用可以像使用單機的Redis一樣使用,Codis底層會處理請求的轉發,不停機的資料遷移等工作,所有後邊的一切事情,對於前面客戶端來說是透明的,可以簡單的認為後邊連線是一個記憶體無限大的Redis服務。

以上我們可以看到codis-proxy是單個節點的,因為我們可以通過結合keepalived來實現高可用:

其系統中包含的元件如下:
codis-proxy : 是客戶端連線的Redis代理服務,codis-proxy 本身實現了Redis協議,表現得和一個原生的Redis沒什麼區別(就像Twemproxy),對於一個業務來說,可以部署多個codis-proxy,codis-proxy本身是沒狀態的。
codis-config :是Codis的管理工具,支援包括,新增/刪除Redis節點,新增/刪除Proxy節點,發起資料遷移等操作,codis-config本身還自帶了一個http server,會啟動一個dashboard,使用者可以直接在瀏覽器上觀察Codis叢集的狀態。
codis-server:是Codis專案維護的一個Redis分支,基於2.8.13開發,加入了slot的支援和原子的資料遷移指令,Codis上層的codis-proxy和codis-config只能和這個版本的Redis互動才能正常執行。
ZooKeeper :用來存放資料路由表和codis-proxy節點的元資訊,codis-config發起的命令都會通過ZooKeeper同步到各個存活的codis-proxy
五、Redis叢集的官方方案:Redis Cluster
Redis 3正式推出了官方叢集技術,解決了多Redis例項協同服務問題。Redis Cluster可以說是服務端Sharding分片技術的體現,即將鍵值按照一定演算法合理分配到各個例項分片上,同時各個例項節點協調溝通,共同對外承擔一致服務。
redis的叢集分割槽,最主要的目的都是在移除、新增一個節點時對已經存在的快取資料的定位影響儘可能的降到最小。redis將雜湊槽分佈到不同節點的做法使得使用者可以很容易地向叢集中新增或者刪除節點, 比如說:
1. 如果使用者將新節點 D 新增到叢集中, 那麼叢集只需要將節點 A 、B 、 C 中的某些槽移動到節點 D 就可以了。
2. 與此類似, 如果使用者要從叢集中移除節點 A , 那麼叢集只需要將節點 A 中的所有雜湊槽移動到節點 B 和節點 C , 然後再移除空白(不包含任何雜湊槽)的節點 A 就可以了。
因為將一個雜湊槽從一個節點移動到另一個節點不會造成節點阻塞, 所以無論是新增新節點還是移除已存在節點, 又或者改變某個節點包含的雜湊槽數量, 都不會造成叢集下線,從而保證叢集的可用性。
1. Redis Cluster的架構
Redis 叢集鍵分佈演算法使用資料分片(sharding)而非一致性雜湊(consistency hashing)來實現: 一個 Redis 叢集包含 16384 個雜湊槽(hash slot), 它們的編號為0、1、2、3……16382、16383,這個槽是一個邏輯意義上的槽,實際上並不存在。redis中的每個key都屬於這 16384 個雜湊槽的其中一個,存取key時都要進行key->slot的對映計算。
和memcached一樣,redis也採用一定的演算法進行鍵-槽(key->slot)之間的對映。memcached採用一致性雜湊(consistency hashing)演算法進行鍵-節點(key-node)之間的對映,而redis叢集使用叢集公式來計算鍵 key 屬於哪個槽:
HASH_SLOT(key)= CRC16(key) % 16384![wps71B9.tmp[4]](http://images2015.cnblogs.com/blog/783994/201607/783994-20160718161342169-233368796.png)
(1)所有的redis節點彼此互聯(PING-PONG機制),內部使用二進位制協議優化傳輸速度和頻寬.
(2)節點的fail是通過叢集中超過半數的節點檢測失效時才生效.
(3)客戶端與redis節點直連,不需要中間proxy層.客戶端不需要連線叢集所有節點,連線叢集中任何一個可用節點即可。
(4)redis-cluster把所有的物理節點對映到[0-16383]slot上(雜湊槽),cluster 負責維護。
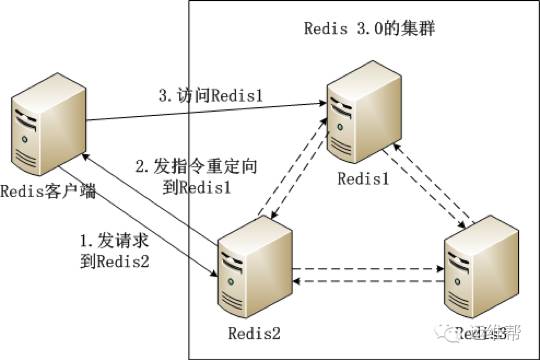
Redis叢集內的機器定期交換資料,工作流程如下。
(1) Redis客戶端在Redis2例項上訪問某個資料。
(2) 在Redis2內發現這個資料是在Redis3這個例項中,給Redis客戶端傳送一個重定向的命令。
(3) Redis客戶端收到重定向命令後,訪問Redis3例項獲取所需的資料。
2. Redis-cluster投票:容錯
(1) 領著投票過程是叢集中所有master參與,如果半數以上master節點與其中一個master節點通訊超時(cluster-node-timeout),認為當前master節點掛掉.
(2) 什麼時候整個叢集不可用(cluster_state:fail)?
a:如果叢集任意master掛掉,且當前master沒有slave.叢集進入fail狀態,也可以理解成叢集的slot對映[0-16383]不完成時進入fail狀態. ps : redis-3.0.0.rc1加入cluster-require-full-coverage引數,預設關閉,開啟叢集相容部分失敗.
b:如果叢集超過半數以上master掛掉,無論是否有slave叢集進入fail狀態.
ps:當叢集不可用時,所有對叢集的操作做都不可用,收到((error)CLUSTERDOWN The cluster is down)錯誤。
3. Redis的問題
Redis 3.0的叢集方案有以下兩個問題。
1. 一個Redis例項具備了“資料儲存”和“路由重定向”,完全去中心化的設計。這帶來的好處是部署非常簡單,直接部署Redis就行,不像Codis有那麼多的元件和依賴。但帶來的問題是很難對業務進行無痛的升級,如果哪天Redis叢集出了什麼嚴重的Bug,就只能回滾整個Redis叢集。
2. 對協議進行了較大的修改,對應的Redis客戶端也需要升級。升級Redis客戶端後誰能確保沒有Bug?而且對於線上已經大規模執行的業務,升級程式碼中的Redis客戶端也是一個很麻煩的事情。
綜合上面所述的兩個問題,Redis 3.0叢集在業界並沒有被大規模使用。
六、雲伺服器上的叢集服務
國內的雲伺服器提供商阿里雲、UCloud等均推出了基於Redis的雲端儲存服務。這個服務的特性如下。
(1)動態擴容
使用者可以通過控制面板升級所需的Redis儲存空間,擴容的過程中服務部不需要中斷或停止,整個擴容過程對使用者透明、無感知,這點是非常實用的,在前面介紹的方案中,解決Redis平滑擴容是個很煩瑣的任務,現在按幾下滑鼠就能搞定,大大減少了運維的負擔。
(2)資料多備
資料儲存在一主一備兩臺機器中,其中一臺機器宕機了,資料還在另外一臺機器上有備份。
(3)自動容災
主機宕機後系統能自動檢測並切換到備機上,實現服務的高可用。
(4)實惠
很多情況下為了使Redis的效能更高,需要購買一臺專門的伺服器用於Redis的儲存服務,但這樣子CPU、記憶體等資源就浪費了,購買Redis雲端儲存服務就很好地解決了這個問題。
有了Redis雲端儲存服務,能使App後臺開發人員從煩瑣運維中解放出來。App後臺要搭建一個高可用、高效能的Redis服務,需要投入相當的運維成本和精力。如果使用雲端儲存服務,就沒必要投入這些成本和精力,可以讓App後臺開發人員更專注於業務。