
Consumer 加入&離開 Group詳解(九)
文章目錄
一、GroupCoordinator 概念
GroupCoordinator是執行在Broker上的一個服務,用來管理Consumer Group的member和各個partition的消費進度,這裡的member指的是我們的KafkaConsumer例項。
broker在啟動的時候會啟動一個GroupCoordinator例項。一個叢集可能有多個broker,那麼怎麼確定一個新的Consumer要和哪個broker上的GroupCoordinator互動呢?
這就和kafka上的一個內部使用的topic __consumer_offsets
__consumer_offsets
consumer_offsets是kafka內部使用的一個topic,專門用來儲存group具體消費的情況,預設情況下,這個topic有50個partition,每個partition有3個副本。我們進入某個broker的日誌目錄,一般都能看到該topic對應的partition目錄,如下圖:

Consumer如何找到對應的GroupCoordinator
__consumer_offsets的會分佈在各個broker,當一個新的Consumer要尋找和它互動的GroupCoordinator時,需要先對它的GroupId進行hash,然後取模__consumer_offsets的partition數量,最後得到的值就是對應partition,那麼這個partition的leader所在的broker就是我們要互動的那個broker了。獲取partition公式如下:
abs(GroupId.hashCode()) % NumPartitions
NumPartitions為__consumer_offsets的數量。GroupId為初始化Consumer時指定的groupId。
舉個例子,假設一個GroupId計算出來的hashcode是5,之後取模50得到5。那麼partition-5的leader所在的broker就是我們要找的那個節點。這個Consumer後面都會直接和該broker上的GroupCoordinator互動。
二、Consumer加入Group流程
Consumer在拉取資料之前,必須加入某個group,在consumer加入到group的整個流程中,主要涉及到了3種請求:
- GROUP_COORDINATOR請求
- JOIN_GROUP請求
- SYNC_GROUP請求
GROUP_COORDINATOR請求
前面我們知道了通過__consumer_offsets和對應的公式可以算出要和哪臺broker上的GroupCoordinator做互動,但是我們並不知道__consumer_offsets的各個partition位於哪些broker上。比如我們通過公式算出了要和__consumer_offsets的partition-5所在的broker做互動,但是我們不知道它的partition-5的leader在哪個broker上。因此我們需要先往叢集的一個broker傳送一個GROUP_COORDINATOR請求來獲取對應的brokerId。
要往哪個broker傳送GROUP_COORDINATOR請求也不是隨機選擇的,kafka會預設選擇一個當前連線數最少的broker來發送該請求。這個連線數是指inFightRequest,也就是當前客戶端發往broker還未返回的那些連線數量。
broker處理:
kafka的broker接收到GROUP_COORDINATOR請求後,會通過公式abs(GroupId.hashCode()) % NumPartitions算出對應的partition,然後搜尋__consumer_offsets的metadata,找到該partition leader所在的brokerId,最後返回給客戶端。
這裡要注意一點:
- 如果__consumer_offsets被刪除了或者還未建立,broker找不到對應的metadata時,會自動建立一個新的名為__consumer_offsets的topic然後再查詢對應的brokerId。
JOIN_GROUP請求
找到要互動的broker後,客戶端就會往該broker傳送 JOIN_GROUP請求了。
JOIN_GROUP請求主要是讓Consumer加入到指定的group中,broker上的GroupCoordinator服務會管理group的各個Consumer。
broker收到 JOIN_GROUP請求後,讓目標group進入 PreparingRebalance狀態,等待一段時間後,返回一些資訊,這些資訊包括Consumer在group中對應的memberId以及該group的leaderId、generationId(每次reblance都會+1)等等,如果對應consumer是leader,那麼還會將當期組中所有的members資訊返回給leader用於後面讓leader來分配各個member要消費的partition(第一個加入該group的consumer就是該group的leader)。
Consumer收到broker返回的資訊後,如果沒有錯誤則表示已經加入到該Group中了。接著繼續傳送SYNC_GROUP請求。
SYNC_GROUP請求
前面的JOIN_GROUP請求只是加入目標group,還沒有真正的分配partiton。SYNC_GROUP請求就是用於獲取consumer要消費哪些partition用的。
Consumer根據前面JOIN_GROUP請求的返回值,會判斷自己是否是leader,如果是leader,就直接獲取group中的所有members然後使用PartitionAssignor的實現類來為group中的各個Consumer分配要消費哪些partition,PartitionAssignor的預設實現是RangeAssignor,也可以通過配置partition.assignment.strategy來指定不同的分配策略。最後leader把分配好的資訊封裝成SYNC_GROUP請求傳送給broker。
如果consumer是follower,就直接傳送一個SYNC_GROUP請求給broker。
broker收到SYNC_GROUP請求後,根據group中的leader給的分配資訊在記憶體中給每個member分配對應的partiton,然後將這些資訊返回給對應的consumer。
最後,各個group中的consumer就得到了自己要消費的partition,就可以開始拉取資料了。
三、Group的狀態變更
對於一個 Consumer Group,它會有五種狀態:Dead、Empty、AwaitingSync、PreparingRebalance、Stable。狀態間的變更關係如下圖所示:
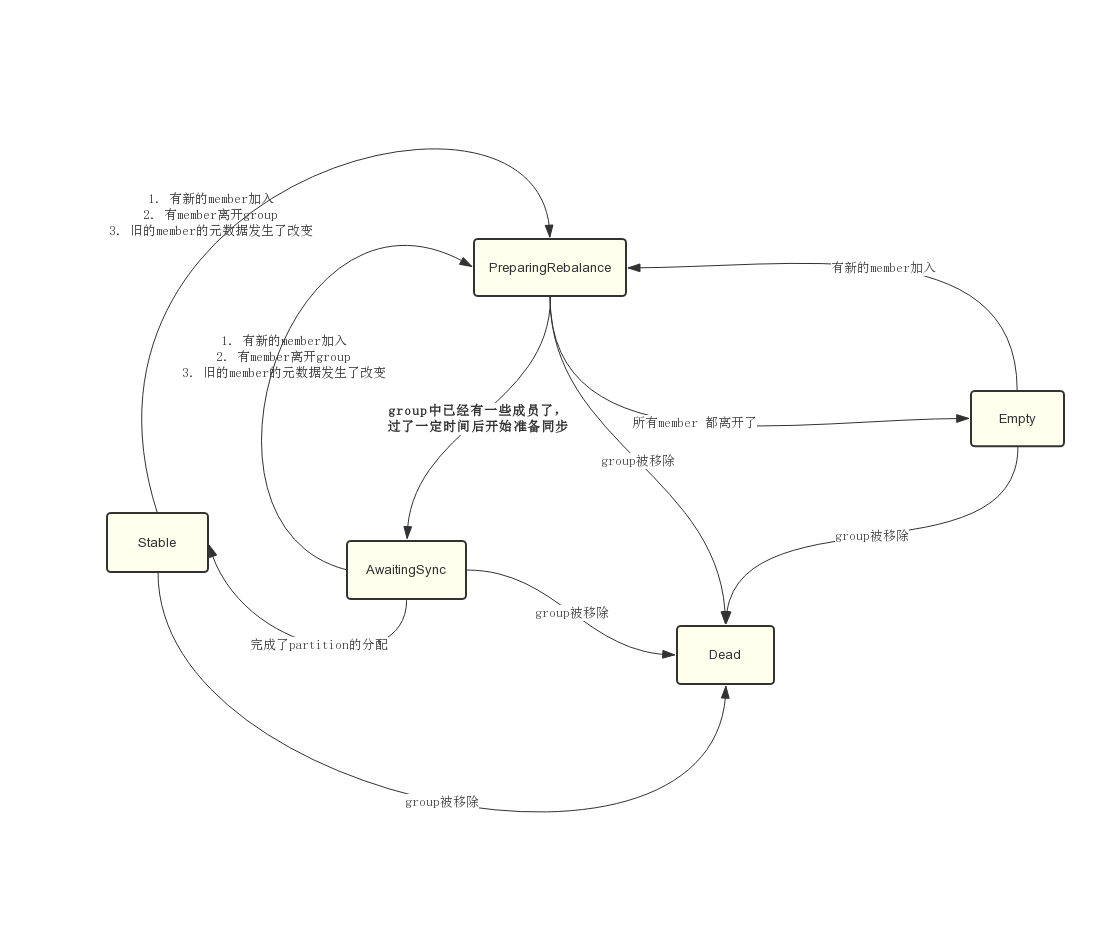
Empty狀態
Empty狀態表示該Consumer Group中沒有任何member。新建的Group都是處於這個狀態,它可能轉化為以下兩種狀態
- PreparingRebalance:如果有新的member加入,狀態就會變更成PreparingRebalance,等待partition-rebalance開始。
- Dead:如果該group被移除掉,狀態就會變成Dead。
PreparingRebalance狀態
PreparingRebalance狀態表示該Group正在等待partition-rebalance開始。這個狀態存在的目的主要是為了等待所有的member都加入到該Group中了,然後開始進行partition rebalance(也就是進入AwaitingSync狀態)。這樣就可以儘量保證在進行partition reblance時,group中的member不會發送變動。它可能轉化為以下三種狀態:
- Dead:如果該group被移除掉,狀態就會變成Dead
- AwaitingSync:第一個傳送PreparingRebalance請求的Consumer返回後,group的狀態就會變成AwaitingSync,等待重新分配partition
- Empty:group中最後一個member離開了,group重新變為Empty狀態
AwaitingSync狀態
AwaitingSync狀態表示該Group正在等待重新分配partition的結果,partiton的分配是由member的leader來進行的,等leader發來SYNC_GROUP請求,GroupCoordinator知道partiton的分配情況了,Group狀態就會變成Stable。它可能轉化為以下三種狀態:
- Dead:如果該group被移除掉,狀態就會變成Dead
- PreparingRebalance:如果有新的member加入或者舊成員離開,狀態會重新變回PreparingRebalance,等待新的一輪partition分配
- Stable:partition分配完成,進入Stable狀態
Stable狀態
Stable狀態表示目前Group已經給各個Consumer分配好各自要消費的partition了。只要Group沒有發生成員變動或者member要消費的元資料沒傳送變動(比如某topic的partition數量變更),狀態就會一直維持在Stable。它也可能轉化為以下兩種狀態:
- Dead:如果該group被移除掉,狀態就會變成Dead
- PreparingRebalance:如果有新的member加入或者舊成員離開,狀態會重新變回PreparingRebalance,等待新的一輪partition分配
Dead狀態
Dead狀態表示該Group已經被移除掉了。如果__consumer_offsets的partition分佈發生變動,就會導致Group可能不屬於該broker上的GroupCoordinator管理,GroupCoordinator就會移除Group。
正常consumer加入group中的狀態變動情況
Empty —> PreparingRebalance —> AwaitingSync —> Stable
當一個consumer傳送 JOIN_GROUP請求要求加入一個新的group時,GroupCoordinator發現之前沒有這個group,就會新建一個group,此時該group的狀態為Empty。之後由於有新成員加入,狀態迅速轉變為PreparingRebalance。另外,GroupCoordinator收到JOIN_GROUP請求後會等待一段時間再返回,讓該Group在PreparingRebalance狀態等待一定時間,以確保該加入的member都加入了。
PreparingRebalance再返回JOIN_GROUP請求後,就會把Group的狀態置為AwaitingSync。 Consumer收到響應後,會再發送SYNC_GROUP請求等待partition分配完成。如果該Consumer是leader,則該Consumer會在本地進行partition的分配,然後把partition的分配結果隨著SYNC_GROUP請求一起上報給GroupCoordinator。之後GroupCoordinator收到leader傳送過來的分配情況,就會將狀態置為Stable,之後將這些資訊作為SYNC_GROUP請求的響應傳送給各個Consumer,各個Consumer就都得到了自己要消費的partition。
四、Consumer心跳機制
Consumer在加入Group後,會開啟一個執行緒,不斷的向GroupCoordinator傳送心跳請求,報告自己還活著。GroupCoordinator會管理group中所有Consumer的心跳,如果發現有一個Consumer超過一定時間沒有傳送心跳過來,GroupCoordinator會認為這個Consumer已經離開group。這時GroupCoordinator會將該group的狀態重新置為PreparingRebalance,開啟新一輪的partition分配。
心跳的傳送頻率和consumer的配置
heartbeat.interval.ms有關,預設是3000,也就是每3s傳送一次心跳。GroupCoordinator判斷member是否過期和consumer的配置
session.timeout.ms有關,預設為10000,也就是超過10s沒收到心跳請求,就移除該member。
Group處於Stable狀態下,新加入一個Consumer
如果目前group已經處於stable狀態了(各個consumer都在消費了),又新加入了一個Consumer,那麼狀態會怎麼變更呢?
首先,新的Consumer會發送一個 JOIN_GROUP請求給GroupCoordinator,GroupCoordinator收到請求後發現這是一個新的member,就會將group的狀態置為PreparingRebalance,然後等待其他member也傳送 JOIN_GROUP請求。
那麼其他正在消費的consumer怎麼知道要重新分配partition呢?這個就和心跳機制有關係了。Consumer傳送心跳給GroupCoordinator的時候,如果GroupCoordinator發現此刻group的狀態是PreparingRebalance,就會告訴Consumer需要重新分配partition了,各個Consumer收到訊息後就開始重新發送JOIN_GROUP請求。
Consumer離開可能引發的Group狀態變更
當Consumer超過一定時間沒有傳送心跳,GroupCoordinator會認為該Consumer已經離開group。此時GroupCoordinator會將該group的狀態置為PreparingRebalance,等待新一輪的parition分配。
五、 __consumer_offsets topic中的訊息
在之前老的版本中,consumer消費的offset情況是儲存在zookeeper中的,但是kafka對zk的依賴性很強,當consumer的數量不斷增多,zk的負擔也會越來越大,最終可能會影響到zk的正常執行。因此,在後面的版本中,kafka設計者將consumer的commitedoffset寫到內部的一個topic中,也就是__consumer_offsets。
__consumer_offsets儲存的兩種訊息型別
除了儲存Consumer Group的commitedOffset外, __consumer_offsets中其他還儲存了另外一種訊息型別:GroupCoordinator管理的元資料資訊,這些元資料包括GroupCoordinator管理的所有Group的資訊,比如Group的狀態,Group的leader資訊,以及Group的各個member資訊,但不包括Group中各個topic-partition的commitedOffset。kafka通過訊息key的不同來區分兩種訊息型別
- commitedOffset 訊息型別
它的key是 GroupId+topic+partition,value是對應的offset。
- GroupCoordinator 訊息型別
它的key是 GroupId,value是對應的元資料資訊
__consumer_offsets 訊息的載入和寫入
資料載入
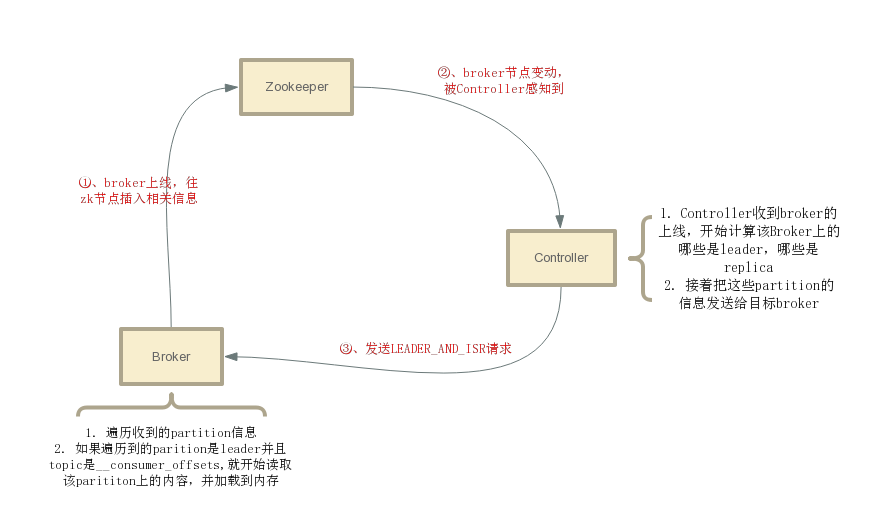
為了讀取更快,無論是commitedOffset,還是GroupCoordinator的元資料,都會從 __consumer_offsets中加載出來快取起來。這些資料在broker啟動的時候載入的。
一個broker在啟動的時候,並不會知道自己機器上的那些partition是leader還是replica,所以無法立即從 __consumer_offsets中載入資料。如果這時有Consumer來拉取offset,kafka就會丟擲一個異常給Consumer,Consumer等待會等待若干時間後再次請求。
在broker啟動後,Controller會感應到有新的broker啟動,然後知道這個broker上的partition哪些是leader,哪些是replica,之後傳送一個LEADER_AND_ISR請求給該broker。該Broker收到這個請求,解析附帶的請求資料,就可以知道自己機器上的parition哪些是leader,哪些是replica了。接著,如果發現這些partition有__consumer_offsets的話,就開始讀取__consumer_offsets的資料並載入的記憶體中。
載入的流程也很簡單,kafka會預先申請5M的記憶體空間,然後從目標partition的第一條offset開始讀取,直到讀取到最後一個offset為止。由於kafka會定時對 __consumer_offsets進行compact,因此__consumer_offsets的partition大小一般也不會太大。
commitedOffset訊息寫入
當有Consumer提交OFFSET_COMMIT請求時,就會往__consumer_offsets的對應partition寫入訊息了。由於kafka對這個topic開始了訊息壓縮(Compact),因此隨著時間的流逝,相同的key,舊的記錄會被清除掉,只剩下最新的那個key
GroupCoordinator元資料寫入
在Group狀態變為Stable後,GroupCoordinator會將當前Group的相關元資料寫入對應partiiton。當有成員離開Group,Group狀態變成Empty的時候,也會寫一條訊息到partition。