
HashMap原始碼註解 之 靜態工具方法hash()、tableSizeFor()(四)
注意 , 本文基於JDK 1.8

HashMap#hash()
為什麼要有HashMap的hash()方法,難道不能直接使用KV中K原有的hash值嗎?在HashMap的put、get操作時為什麼不能直接使用K中原有的hash值。
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in 從上面的程式碼可以看到key的hash值的計算方法。key的hash值高16位不變,低16位與高16位異或作為key的最終hash值。(h >>> 16,表示無符號右移16位,高位補0,任何數跟0異或都是其本身,因此key的hash值高16位不變。)
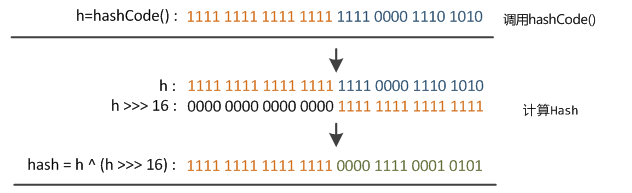
為什麼要這麼幹呢?
這個與HashMap中table下標的計算有關。
n = table.length;
index = (n-1) & hash;因為,table的長度都是2的冪,因此index僅與hash值的低n位有關(此n非table.leng,而是2的冪指數),hash值的高位都被與操作置為0了。
假設table.length=2^4=16。

由上圖可以看到,只有hash值的低4位參與了運算。
這樣做很容易產生碰撞。設計者權衡了speed, utility, and quality,將高16位與低16位異或來減少這種影響。設計者考慮到現在的hashCode分佈的已經很不錯了,而且當發生較大碰撞時也用樹形儲存降低了衝突。僅僅異或一下,既減少了系統的開銷,也不會造成的因為高位沒有參與下標的計算(table長度比較小時),從而引起的碰撞。
HashMap#tableSizeFor()
原始碼:
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}這個方法被呼叫的地方:
public HashMap(int initialCapacity, float loadFactor) {
/**省略此處程式碼**/
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}由此可以看到,當在例項化HashMap例項時,如果給定了initialCapacity,由於HashMap的capacity都是2的冪,因此這個方法用於找到大於等於initialCapacity的最小的2的冪(initialCapacity如果就是2的冪,則返回的還是這個數)。
下面分析這個演算法:
首先,為什麼要對cap做減1操作。int n = cap - 1;
這是為了防止,cap已經是2的冪。如果cap已經是2的冪, 又沒有執行這個減1操作,則執行完後面的幾條無符號右移操作之後,返回的capacity將是這個cap的2倍。如果不懂,要看完後面的幾個無符號右移之後再回來看看。
下面看看這幾個無符號右移操作:
如果n這時為0了(經過了cap-1之後),則經過後面的幾次無符號右移依然是0,最後返回的capacity是1(最後有個n+1的操作)。
這裡只討論n不等於0的情況。
第一次右移
n |= n >>> 1;由於n不等於0,則n的二進位制表示中總會有一bit為1,這時考慮最高位的1。通過無符號右移1位,則將最高位的1右移了1位,再做或操作,使得n的二進位制表示中與最高位的1緊鄰的右邊一位也為1,如000011xxxxxx。
第二次右移
n |= n >>> 2;注意,這個n已經經過了n |= n >>> 1; 操作。假設此時n為000011xxxxxx ,則n無符號右移兩位,會將最高位兩個連續的1右移兩位,然後再與原來的n做或操作,這樣n的二進位制表示的高位中會有4個連續的1。如00001111xxxxxx 。
第三次右移
n |= n >>> 4;這次把已經有的高位中的連續的4個1,右移4位,再做或操作,這樣n的二進位制表示的高位中會有8個連續的1。如00001111 1111xxxxxx 。
以此類推
注意,容量最大也就是32bit的正數,因此最後n |= n >>> 16; ,最多也就32個1,但是這時已經大於了MAXIMUM_CAPACITY ,所以取值到MAXIMUM_CAPACITY 。
舉一個例子說明下吧。
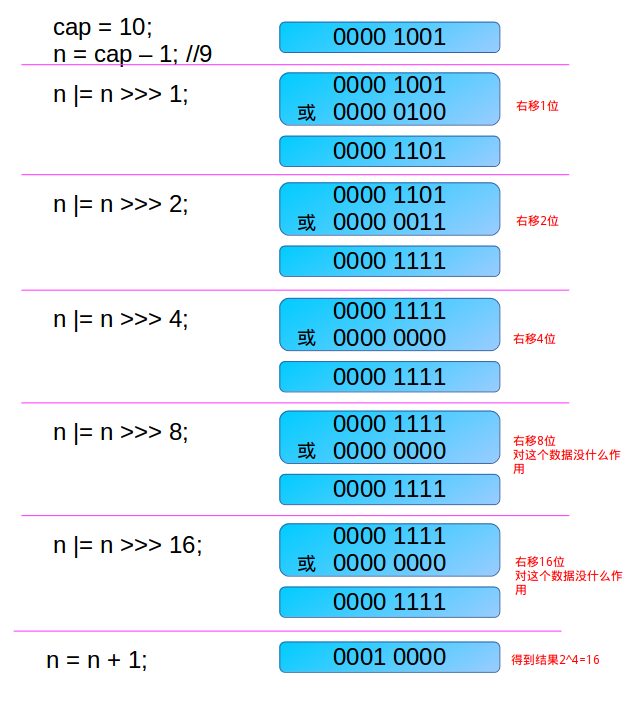
這個演算法著實牛逼啊!
注意,得到的這個capacity卻被賦值給了threshold。
this.threshold = tableSizeFor(initialCapacity);開始以為這個是個Bug,感覺應該這麼寫:
this.threshold = tableSizeFor(initialCapacity) * this.loadFactor;這樣才符合threshold的意思(當HashMap的size到達threshold這個閾值時會擴容)。
但是,請注意,在構造方法中,並沒有對table這個成員變數進行初始化,table的初始化被推遲到了put方法中,在put方法中會對threshold重新計算,put方法的具體實現請看這篇博文。