
線上查詢系統性能優化
背景
在最近的一個專案是一個後臺管理工具,WEB端需要根據後端錄入的資料,顯示一個龐大的表格。主要的幾點需求如下:
- 每條記錄包含多個欄位,都需要顯示在WEB端介面上
- 其中有些欄位並不能通過資料庫查詢直接得出,需要另外計算得出
- 支援設定過濾條件和按欄位排序
- 需求變化很快,欄位可能隨時調整
對此,後端為了整體解決,會把查詢得到的所有記錄都合併到一起作計算,得到包含所有欄位的完整資料。有了完整的資料,之後的過濾和排序就相對容易實現了。
問題
這種設計在專案初期的確對快速變化的需求表現出了良好的應變能力。然而隨著資料量的增加,該方案也出現了明顯的效能問題,經分析發現主要的問題出在以下幾個方面:
- 隨著資料量增加,對所有記錄做計算越來越耗時
- 因為資料量的關係,從資料庫伺服器取出記錄的過程本身也很耗時
解決這兩個問題的根本都是是減少資料量。很明顯,不符合過濾條件的記錄沒有必要傳輸到後端伺服器上,也沒有必要做欄位計算。如果可以提前得到甚至縮小符合過濾條件的記錄ID,可以大大加速整個過程。
索引表
針對前端特殊的展示需求(一張大表格),一個直觀的解決方案是扁平化所有的資料。為此我們新建了一張索引表SearchTable,將每條記錄的相應欄位預先計算並填入。資料表結構如下:
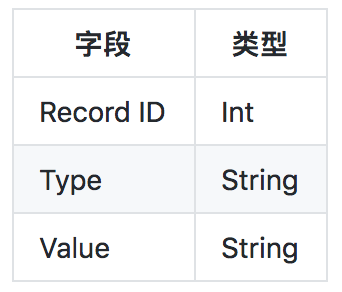
索引表中的每一行對應一條記錄的欄位及其取值,其中type標識了該行欄位名稱,value則是對應的值。
這樣過濾條件可以轉化為類似如下的查詢語句,無需任何計算就可以直接得到滿足條件記錄的ID:
SELECT record_id FROM SearchTable WHERE record_id in (SELECT record_id FROM SearchTable WHERE type='typeA' AND value in (valueA1, valueA2, ...)) AND record_id in (SELECT record_id FROM SearchTable WHERE type='typeB' AND value in (valueB1, valueB2, ...)) AND ...
索引表初始化
索引表上線前需要對當前所有記錄做初始化,另外如果上線後發生不一致的問題,也需要一個重建過程。因此重建是一個重要功能,需要做成一個相對獨立的模組以供將來方便呼叫。重建過程即是對指定記錄,重新計算其所有欄位的值填入索引表。
索引表更新
任何對記錄的刪改,都必須同時更新索引表,否則會造成之後的查詢結果不一致。需要注意的是索引表更新必須跟記錄更新在同一個資料庫事務中進行,保證資料一致性。
索引表本質上是用空間(冗餘資料)換時間(查詢速度)。
分頁
使用者不可能一次性檢視所有記錄,分頁是前端普遍採用的優化策略。但使用索引表之前,分頁起到的作用僅僅是減少了WEB伺服器到瀏覽器的資料傳輸,資料庫到WEB伺服器,以及WEB伺服器本身的資料處理量完全沒有減少。
引入索引表後,直接利用索引表進行排序分頁操作成為了可能。一旦最終分頁結果可以通過索引表確定,資料庫到WEB伺服器和WEB伺服器本身的資料量也可以享受到分頁的優化效果。
利用索引表做分頁有兩個條件:
- 所有過濾條件都在索引表中
- 分頁排序的欄位也在索引表中
如下是一個按照建立時間排序並按每頁300條記錄分頁的例子(注意排序時候cast函式的使用):
SELECT record_id FROM SearchTable WHERE
record_id in (SELECT record_id FROM SearchTable WHERE type='typeA' AND value in (valueA1, valueA2, ...))
AND
record_id in (SELECT record_id FROM SearchTable WHERE type='typeB' AND value in (valueB1, valueB2, ...))
AND
...
AND
type='time_created'
ORDER BY cast(value as unsigned) DESC
LIMIT 300
分步遷移
效能優化從來都是一項複雜、長期的工程,尤其在大型系統中更為如此。因此優化的分步推進有很大的必要性,既可以讓系統不斷享受到優化的紅利,也可以保證系統的穩定性,不會因為大規模的改動引入過高的風險。索引表也恰恰滿足了我們這方面的需求。
對此,我們改造了原有的程式碼,使其支援在給定記錄ID範圍內進行處理。
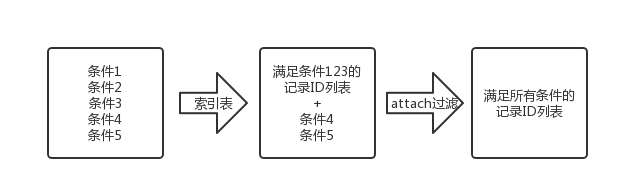
這樣,不用等到所有欄位遷移完索引表便可以上線工作。通過已經遷移的欄位可以預先查詢到一個相對較大的記錄範圍,再交給原來的過濾程式進行處理。也能起到一定的優化效果,也給優化爭取了寶貴的時間。效能優化是一個大工程,從來不可能一蹴而就。
分佈遷移的好處還有:
- 可以分步到線上檢驗實際效果,及時修復暴露出的問題
- 可以根據效果及時調整優化方案
快取的合理使用
最後說一下資料庫系統中快取的使用。快取作為一個傳統優化技術,還是有其不可替代的作用。
在本專案中,索引表的引入雖然很大程度上解決了目前碰到的效能問題,但並不能解決所有問題,特別是一些小粒度上的優化,還得依賴傳統的快取技術。快取的合理使用可以很大程度上緩解資料庫的訪問壓力。
快取的使用原則一般遵循80/20原則:如果80%的訪問集中在20%的資料上,這些資料很可能非常適合做快取優化。快取的命中率是一個很重要的指標,如果命中率太低,說明快取效果很差,可能還不如不設定快取。
一個簡單的例子是從索引表得到記錄ID後,需要根據ID取出對應的記錄。這時候快取就派上用場了,如果事先將記錄資料快取在記憶體中,那麼可以很大程度上減少對資料庫的訪問。
可見快取和資料庫的合理搭配使用,才是後端效能優化的關鍵。