JVM:GC-垃圾收集器
Serial收集器
作用:單執行緒、新生代收集器
演算法:使用複製演算法
說明:
單執行緒的含義有兩層:
只有一個垃圾回收執行緒參與GC,
在GC的過程中需要暫停其他工作執行緒。
缺陷:
1、在多CPU下,單執行緒收集的效率不高
2、在GC時必須暫停其他工作執行緒,對很多應用來說難以接受。
優點:
單CPU下,顯得簡單高效。
應用場景:
桌面級客戶端應用,分配給虛擬機器管理的記憶體不會很大。
收集幾十到一兩百的新生代物件,停頓也是毫秒級的,這點停頓還是可以接受的。
Serial Old收集器
作用:單執行緒、老年代收集器,Serial的老年代版本
演算法:標記-整理
作用:
1、client下回收器
2、server下:
jdk1.5下與Parallel Scavenge搭配使用,
作為CMS的後備收集器
ParNew收集器
作用:多執行緒,新生代收集器。Serial的多執行緒版本
演算法:同Serial 複製演算法
應用場景:在CMS作為老年代收集器時,能配合使用的新生代收集器只有ParNew和Serial
注意:ParNew在單CPU環境下,通過超執行緒技術實現垃圾回收的效率遠比不上Serial收集器,因為本身還存線上程互動的開銷。但是隨著CPU數量的提升,它對系統資源的有效利用還是有好處的。
Parallel Scavenge 收集器
作用:新生代、多執行緒並行收集
演算法:複製。。
看起來跟ParNew一樣,有什麼區別嗎?
ParNew及其他收集器著重的目標是縮短GC是使用者執行緒的停頓時間。
而Parallel Scavenge 側重 吞吐量
吞吐量=(執行使用者執行緒時間)/(執行使用者執行緒時間)+GC時間。因此被稱為吞吐量優先收集器。
注意:
停頓時間越短,越適合需要使用者互動的程式,迅速的響應可以提升使用者體驗。
而吞吐量優先的收集器適用於後臺運算,而不需要與使用者互動的執行緒,可以最大效率的使用CPU時間,快速完成任務。
老年代可以使用Serial Old/Parallel Old(優先)搭配。
Parallel Old 收集器
作用:Parallel Scavenge老年代版本,多執行緒,並行
演算法:標記-整理
在注意吞吐量和CPU資源敏感的場景下,使用Parallel Scavenge+Parallel Old
CMS收集器
作用:老年代、與使用者執行緒併發
演算法:標記-清除
四個步驟:
1、初始標記:
只標記與GC ROOT直接關聯的物件。速度很快。存在短暫的STOP THE WORLD.
2、併發標記:
從 GC ROOT 開始搜素的過程,耗時長。與使用者執行緒併發。
3、重新標記:
標記併發標記過程中產生的垃圾,耗時比初始標記長,比並發標記短。需要STOP THE WORLD
4、併發清除:
清除標記的物件。與使用者執行緒併發
缺陷:
1、對CPU資源敏感:
在與使用者執行緒併發操作的過程中,雖然不會導致使用者執行緒停頓,但是因為佔用了一部分CPU資源而導致應用程式變慢,吞吐量降低。
CMS預設啟動的垃圾回收執行緒數為
(CPU數+3)/4 佔用超過25%的CPU資源,並且隨著CPU數量的上升而下降。
當CPU為2時,需要有一半的CPU資源參與回收,對使用者執行緒影響很大。
為了解決這個問題,出現了增量式的CMS,實現原理是搶佔式來模擬多工機制。就是在併發標記階段,時GC執行緒與使用者執行緒交替執行,但是實際效果很一般。
2、存在浮動垃圾。因為併發清除的時候,使用者執行緒還在執行,會源源不斷產生新的垃圾,這些垃圾只能在下一次GC才能被清理。
因此CMS不能等到年老代佔滿了才開始GC,需要預留一部分空間給浮動垃圾。
JDK1.5的啟動閾值68%。
而JDK1.6的啟動閾值是92%,要是CMS執行期間記憶體不足,就會Concurrent Mode Failure。此時就會啟動備選收集器,Serial Old.
3、存在大量的記憶體碎片。因為使用的是標記清除演算法。
因此CMS還提供了:
-XX:+UserCMSCompactAtFullCollection,用於要在頂不住執行FullGC時來一次記憶體碎片整理,此時無法併發,因此停頓時間不得不變長。
-XX:CMSFullGCBeforeCompaction:用於設定多少次不壓縮的FullGC之後,跟著來一次壓縮的。預設0,代表每次都要壓縮。
G1收集器
關於Region:
G1把堆記憶體劃分為多個大小相等的Region區域,
注意:
雖然保留了新生代老年代的概念,但是不再是物理隔離,而是一系列Region的集合。
關於Remebered Set:
G1為每個Region維護一個 Remebered Set,因此在標記階段,不需要進行全堆掃描。
回收方式,可預測停頓時間:
G1跟蹤每一個Region垃圾堆積的價值大小(回收所獲得的空間與回收時間之比),在後臺維護一個優先列表。
每次GC時,在允許的收集時間內,回收最有價值的Region,以求在有限的時間內,儘可能的達到回收的最高效率。
G1的幾個步驟:
1、初始標記:
同CMS
2、併發標記:
同CMS
3、最終標記:
將併發標記階段,使用者執行緒執行導致引用關係變化而記錄的Remembered Set Logs合併到Remembered Set上。
這個階段需要STW.
4、篩選回收:
回收最有回收價值的Region
特點:
1、併發並行。
2、分代回收:保留了分代回收的概念。但是不需要其他回收集器配合。能夠用不同的方式處理新物件和熬過多次GC的老物件。
3、空間整合:整體看是標記-整理,區域性【兩個Region】看是複製演算法,兩者都不產生記憶體碎片,在GC後都能得到規整的記憶體空間。
4、可預測的停頓:以Region劃分空間,根據回收價值排序優先回收價值高的Region,以求在有限時間內達到更高的回收效率。
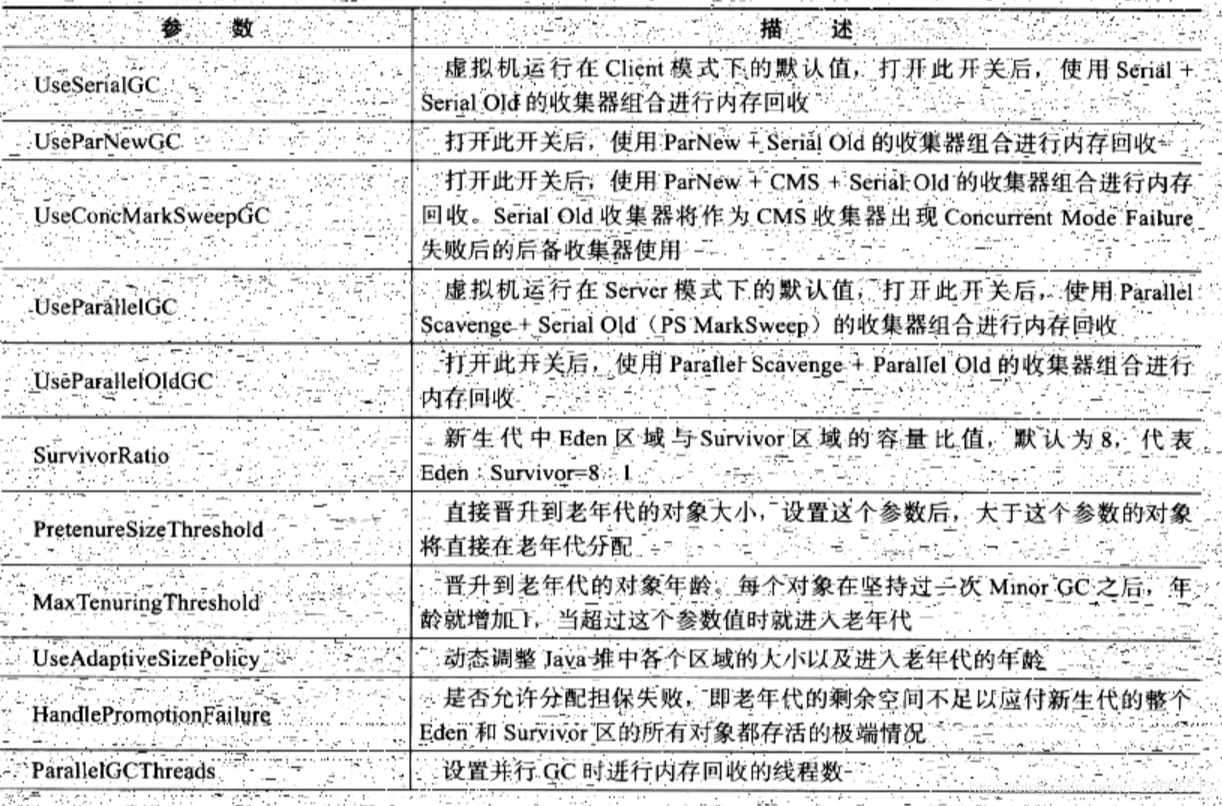
垃圾收集器引數記錄