
單鏈表的逆置(頭插法和就地逆置)
今天課間的時候偶然看到了一個面試題:單鏈表的逆置,看了題解感覺乖乖的,貌似和以前看的版本不搭,於是重新進行了一番探究
單鏈表的逆置分為兩種方法:頭插法和就地逆置法,這兩種方法雖然都能夠達到逆置的效果,但還是有著不小的差別
頭插法

演算法思路:依次取原連結串列中的每一個節點,將其作為第一個節點插入到新連結串列中,指標用來指向當前節點,p為空時結束。
核心程式碼
void reverse(node*head)
{
node*p;
p=head->next;
head->next=NULL;
while(p)
{
q 以上面圖為例子,說白了就是不斷的將1後面的節點插入到head後面,即為頭插法
完整程式碼
#include<stdio.h>
#include<malloc.h>
typedef struct node
{
int data;
struct node*next;
}node;
node*creat()
{
node*head,*p,*q;
char ch;
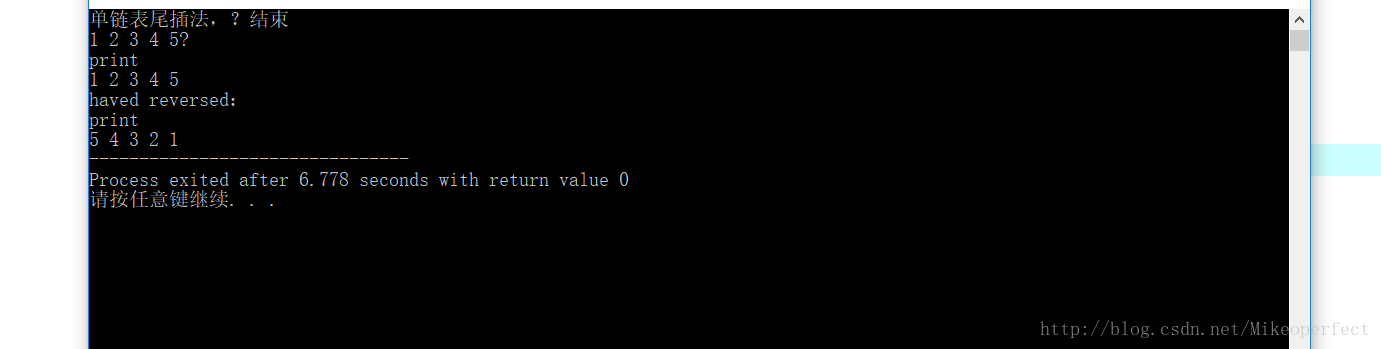
head=(node*) 程式截圖
就地逆置法
//單鏈表定義
typedef struct ListNode{
int m_nValue;
ListNode* pNext;
};
//單鏈表逆置實現
ListNode* ReverseList(ListNode* pHead)
{
if (pHead == NULL || pHead->pNext == NULL)
{
retrun pHead;
}
ListNode* pRev = NULL;
ListNode* pCur = pHead;
while(pCur != NULL)
{
ListNode* pTemp = pCur; // 步驟①
pCur = pCur->pNext; // 步驟②
pTemp->pNext = pRev; // 步驟③
pRev = pTemp;
}
return pRev;
}下面我們來用圖解的方法具體介紹整個程式碼的實現流程:
初始狀態:

第一次迴圈:
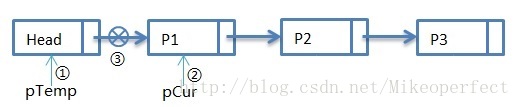
第一次迴圈過後,步驟①:pTemp指向Head,步驟②:pCur指向P1,步驟③:pTemp->pNext指向NULL。
此時得到的pRev為:

第二次迴圈:
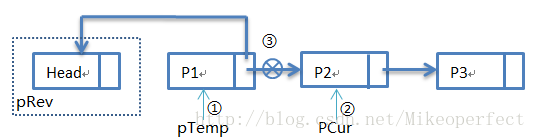
第二次迴圈過後,步驟①:pTemp指向P1,步驟②:pCur指向P2,步驟③:pTemp->pNext指向Head。
此時得到的pRev為:

第三次迴圈:

第三次迴圈過後:步驟①:pTemp指向P2,步驟②:pCur指向P3,步驟③:pTemp->pNext指向P1。
此時得到的pRev為:
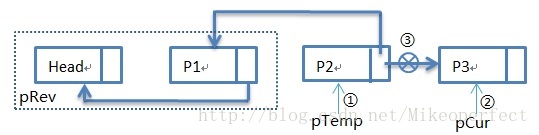
第四次迴圈:

第四次迴圈過後:步驟①:pTemp指向P3,步驟②:pCur指向NULL,步驟③:pTemp->pNext指向P2。
此時得到的pRev為:
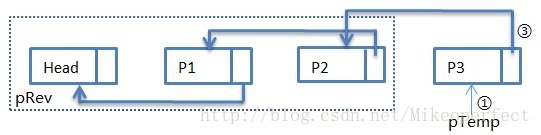
至此,單鏈表的逆置完成。
如果還沒有看懂,可以去參考一下這個
連結串列的翻轉是程式設計師面試中出現頻度最高的問題之一,常見的解決方法分為遞迴和迭代兩種。最近在複習的時候,發現網上的資料都只告訴了怎麼做,但是根本沒有好好介紹兩種方法的實現過程與原理。所以我覺得有必要好好的整理一篇博文,來幫忙大家一步步理解其中的實現細節。
我們知道迭代是從前往後依次處理,直到迴圈到鏈尾;而遞迴恰恰相反,首先一直迭代到鏈尾也就是遞迴基判斷的準則,然後再逐層返回處理到開頭。總結來說,連結串列翻轉操作的順序對於迭代來說是從鏈頭往鏈尾,而對於遞迴是從鏈尾往鏈頭。下面我會用詳細的圖文來剖析其中實現的細節。
1、非遞迴(迭代)方式
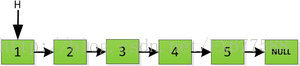
迭代的方式是從鏈頭開始處理,如下圖給定一個存放5個數的連結串列。
首先對於連結串列設定兩個指標:
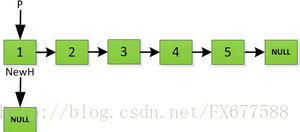
然後依次將舊連結串列上每一項新增在新連結串列的後面,然後新連結串列的頭指標NewH移向新的連結串列頭,如下圖所示。此處需要注意,不可以上來立即將上圖中P->next直接指向NewH,這樣存放2的地址就會被丟棄,後續連結串列儲存的資料也隨之無法訪問。而是應該設定一個臨時指標tmp,先暫時指向P->next指向的地址空間,儲存原連結串列後續資料。然後再讓P->next指向NewH,最後P=tmp就可以取回原連結串列的資料了,所有迴圈訪問也可以繼續展開下去。
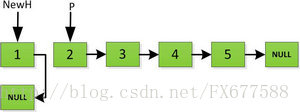
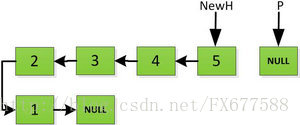
指標繼續向後移動,直到P指標指向NULL停止迭代。
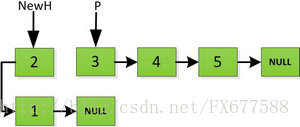
最後一步:
2、非遞迴實現的程式
node* reverseList(node* H)
{
if (H == NULL || H->next == NULL) //連結串列為空或者僅1個數直接返回
return H;
node* p = H, *newH = NULL;
while (p != NULL) //一直迭代到鏈尾
{
node* tmp = p->next; //暫存p下一個地址,防止變化指標指向後找不到後續的數
p->next = newH; //p->next指向前一個空間
newH = p; //新連結串列的頭移動到p,擴長一步連結串列
p = tmp; //p指向原始連結串列p指向的下一個空間
}
return newH;
}3、遞迴方式
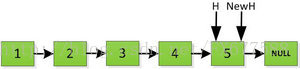
我們再來看看遞迴實現連結串列翻轉的實現,前面非遞迴方式是從前面數1開始往後依次處理,而遞迴方式則恰恰相反,它先迴圈找到最後面指向的數5,然後從5開始處理依次翻轉整個連結串列。
首先指標H迭代到底如下圖所示,並且設定一個新的指標作為翻轉後的連結串列的頭。由於整個連結串列翻轉之後的頭就是最後一個數,所以整個過程NewH指標一直指向存放5的地址空間。
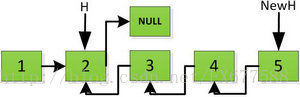
然後H指標逐層返回的時候依次做下圖的處理,將H指向的地址賦值給H->next->next指標,並且一定要記得讓H->next =NULL,也就是斷開現在指標的連結,否則新的連結串列形成了環,下一層H->next->next賦值的時候會覆蓋後續的值。
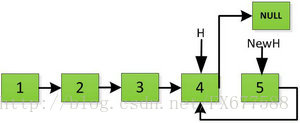
繼續返回操作:
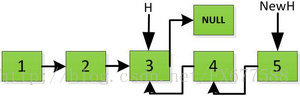
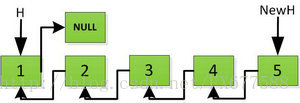
上圖第一次如果沒有將存放4空間的next指標賦值指向NULL,第二次H->next->next=H,就會將存放5的地址空間覆蓋為3,這樣連結串列一切都大亂了。接著逐層返回下去,直到對存放1的地址空間處理。
返回到頭:
4、迭代實現的程式
node* In_reverseList(node* H)
{
if (H == NULL || H->next == NULL) //連結串列為空直接返回,而H->next為空是遞迴基
return H;
node* newHead = In_reverseList(H->next); //一直迴圈到鏈尾
H->next->next = H; //翻轉連結串列的指向
H->next = NULL; //記得賦值NULL,防止連結串列錯亂
return newHead; //新連結串列頭永遠指向的是原連結串列的鏈尾
}5、整體實現的程式:
#include<iostream>
using namespace std;
struct node{
int val;
struct node* next;
node(int x) :val(x){}
};
/***非遞迴方式***/
node* reverseList(node* H)
{
if (H == NULL || H->next == NULL) //連結串列為空或者僅1個數直接返回
return H;
node* p = H, *newH = NULL;
while (p != NULL) //一直迭代到鏈尾
{
node* tmp = p->next; //暫存p下一個地址,防止變化指標指向後找不到後續的數
p->next = newH; //p->next指向前一個空間
newH = p; //新連結串列的頭移動到p,擴長一步連結串列
p = tmp; //p指向原始連結串列p指向的下一個空間
}
return newH;
}
/***遞迴方式***/
node* In_reverseList(node* H)
{
if (H == NULL || H->next == NULL) //連結串列為空直接返回,而H->next為空是遞迴基
return H;
node* newHead = In_reverseList(H->next); //一直迴圈到鏈尾
H->next->next = H; //翻轉連結串列的指向
H->next = NULL; //記得賦值NULL,防止連結串列錯亂
return newHead; //新連結串列頭永遠指向的是原連結串列的鏈尾
}
int main()
{
node* first = new node(1);
node* second = new node(2);
node* third = new node(3);
node* forth = new node(4);
node* fifth = new node(5);
first->next = second;
second->next = third;
third->next = forth;
forth->next = fifth;
fifth->next = NULL;
//非遞迴實現
node* H1 = first;
H1 = reverseList(H1); //翻轉
//遞迴實現
node* H2 = H1; //請在此設定斷點檢視H1變化,否則H2再翻轉,H1已經發生變化
H2 = In_reverseList(H2); //再翻轉
return 0;
}總結
頭插法和就地逆置法是有區別的,其區別就在於逆置後的連結串列如果需要列印的話,那麼頭插法是從head開始的,而就地逆置則是從表尾開始的,從便捷性來說,頭插法還是較之就地逆置法要好上那麼一點點,當然因題而異了