
【轉載】十分鐘一起學會ResNet殘差網路
深層次網路訓練瓶頸:梯度消失,網路退化
深度卷積網路自然的整合了低中高不同層次的特徵,特徵的層次可以靠加深網路的層次來豐富。從而,在構建卷積網路時,網路的深度越高,可抽取的特徵層次就越豐富。所以一般我們會傾向於使用更深層次的網路結構,以便取得更高層次的特徵。但是在使用深層次的網路結構時我們會遇到兩個問題,梯度消失,梯度爆炸問題和網路退化的問題。
但是當使用更深層的網路時,會發生梯度消失、爆炸問題,這個問題很大程度通過標準的初始化和正則化層來基本解決,這樣可以確保幾十層的網路能夠收斂,但是隨著網路層數的增加,梯度消失或者爆炸的問題仍然存在。
還有一個問題就是網路的退化,舉個例子,假設已經有了一個最優化的網路結構,是18層。當我們設計網路結構的時候,我們並不知道具體多少層次的網路時最優化的網路結構,假設設計了34層網路結構。那麼多出來的16層其實是冗餘的,我們希望訓練網路的過程中,模型能夠自己訓練這五層為恆等對映,也就是經過這層時的輸入與輸出完全一樣。但是往往模型很難將這16層恆等對映的引數學習正確,那麼就一定會不比最優化的18層網路結構效能好,這就是隨著網路深度增加,模型會產生退化現象。它不是由過擬合產生的,而是由冗餘的網路層學習了不是恆等對映的引數造成的。
ResNet簡介
ResNet是在2015年有何凱明,張翔宇,任少卿,孫劍共同提出的,ResNet使用了一個新的思想,ResNet的思想是假設我們涉及一個網路層,存在最優化的網路層次,那麼往往我們設計的深層次網路是有很多網路層為冗餘層的。那麼我們希望這些冗餘層能夠完成恆等對映,保證經過該恆等層的輸入和輸出完全相同。具體哪些層是恆等層,這個會有網路訓練的時候自己判斷出來。將原網路的幾層改成一個殘差塊,殘差塊的具體構造如下圖所示:
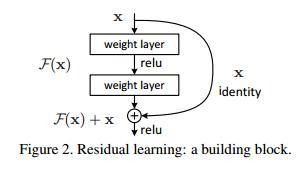
可以看到X是這一層殘差塊的輸入,也稱作F(x)為殘差,x為輸入值,F(X)是經過第一層線性變化並激活後的輸出,該圖表示在殘差網路中,第二層進行線性變化之後啟用之前,F(x)加入了這一層輸入值X,然後再進行啟用後輸出。在第二層輸出值啟用前加入X,這條路徑稱作shortcut連線。
ResNet解決深度網路瓶頸的魔力
網路退化問題的解決:
我們發現,假設該層是冗餘的,在引入ResNet之前,我們想讓該層學習到的引數能夠滿足h(x)=x,即輸入是x,經過該冗餘層後,輸出仍然為x。但是可以看見,要想學習h(x)=x恆等對映時的這層引數時比較困難的。ResNet想到避免去學習該層恆等對映的引數,使用瞭如上圖的結構,讓h(x)=F(x)+x;這裡的F(x)我們稱作殘差項,我們發現,要想讓該冗餘層能夠恆等對映,我們只需要學習F(x)=0。學習F(x)=0比學習h(x)=x要簡單,因為一般每層網路中的引數初始化偏向於0,這樣在相比於更新該網路層的引數來學習h(x)=x,該冗餘層學習F(x)=0的更新引數能夠更快收斂,如圖所示:
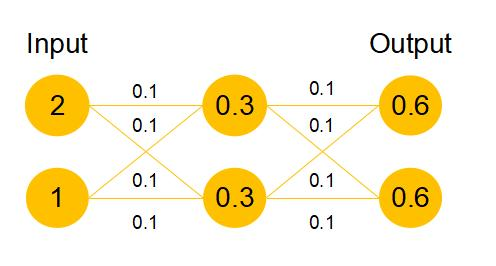
假設該曾網路只經過線性變換,沒有bias也沒有啟用函式。我們發現因為隨機初始化權重一般偏向於0,那麼經過該網路的輸出值為[0.6 0.6],很明顯會更接近與[0 0],而不是[2 1],相比與學習h(x)=x,模型要更快到學習F(x)=0。
並且ReLU能夠將負數啟用為0,過濾了負數的線性變化,也能夠更快的使得F(x)=0。這樣當網路自己決定哪些網路層為冗餘層時,使用ResNet的網路很大程度上解決了學習恆等對映的問題,用學習殘差F(x)=0更新該冗餘層的引數來代替學習h(x)=x更新冗餘層的引數。
這樣當網路自行決定了哪些層為冗餘層後,通過學習殘差F(x)=0來讓該層網路恆等對映上一層的輸入,使得有了這些冗餘層的網路效果與沒有這些冗餘層的網路效果相同,這樣很大程度上解決了網路的退化問題。
梯度消失或梯度爆炸問題的解決:
我們發現很深的網路層,由於引數初始化一般更靠近0,這樣在訓練的過程中更新淺層網路的引數時,很容易隨著網路的深入而導致梯度消失,淺層的引數無法更新。

可以看到,假設現在需要更新b1,w2,w3,w4引數因為隨機初始化偏向於0,通過鏈式求導我們會發現,w1w2w3相乘會得到更加接近於0的數,那麼所求的這個b1的梯度就接近於0,也就產生了梯度消失的現象。
ResNet最終更新某一個節點的引數時,由於h(x)=F(x)+x,由於鏈式求導後的結果如下圖所示,不管括號內右邊部分的求導引數有多小,因為左邊的1的存在,並且將原來的鏈式求導中的連乘變成了連加狀態(正確?),都能保證該節點引數更新不會發生梯度消失或梯度爆炸現象。

這樣ResNet在解決了阻礙更深層次網路優化問題的兩個重要問題後,ResNet就能訓練更深層次幾百層乃至幾千層的網路並取得更高的精確度了。
ResNet使用的小技巧
這裡是應用了ResNet的網路圖,這裡如果遇到了h(x)=F(x)+x中x的維度與F(x)不同的維度時,我們需要對identity加入Ws來保持Ws*x的維度與F(x)的維度一致。
x與F(x)維度相同時:
x與F(x)維度不同時:
下邊是ResNet的網路結構圖:

使用1*1卷積減少引數和計算量:
如果用了更深層次的網路時,考慮到計算量,會先用1*1的卷積將輸入的256維降到64維,然後通過1*1恢復。這樣做的目的是減少引數量和計算量。
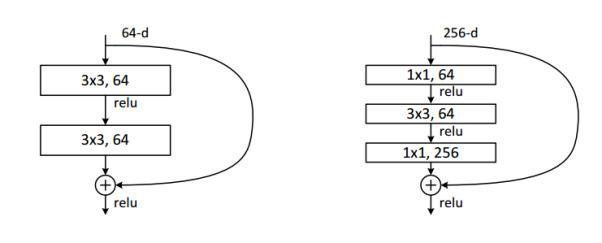
左圖是ResNet34,右圖是ResNet50/101/152。這一個模組稱作building block,右圖稱之為bottleneck design。在面對50,101,152層的深層次網路,意味著有很大的計算量,因此這裡使用1*1卷積先將輸入進行降維,然後再經過3*3卷積後再用1*1卷積進行升維。使用1*1卷積的好處是大大降低引數量計算量。
總結
通過上述的學習,你應該知道了,現如今大家普遍認為更好的網路是建立在更寬更深的網路基礎上,當你需要設計一個深度網路結構時,你永遠不知道最優的網路層次結構是多少層,一旦你設計的很深入了,那勢必會有很多冗餘層,這些冗餘層一旦沒有成功學習恆等變換h(x)=x,那就會影響網路的預測效能,不會比淺層的網路學習效果好從而產生退化問題。
ResNet的過人之處,是他很大程度上解決了當今深度網路頭疼的網路退化問題和梯度消失問題。使用殘差網路結構h(x)=F(x)+x代替原來的沒有shortcut連線的h(x)=x,這樣更新冗餘層的引數時需要學習F(x)=0比學習h(x)=x要容易得多。而shortcut連線的結構也保證了反向傳播更新引數時,很難有梯度為0的現象發生,不會導致梯度消失。
這樣,ResNet的構建,使我們更朝著符合我們的直覺走下去,即越深的網路對於高階抽象特徵的提取和網路效能更好,不用在擔心隨著網路的加深發生退化問題了。
參考連結:https://baijiahao.baidu.com/s?id=1609100487339160987&wfr=spider&for=pc