
python手記(五):requests寫爬蟲(三):實戰:翻譯器
人生不易且無趣,一起找點樂子吧。歡迎評論,和文章無關也可以。
有了前兩篇文章做基礎,我們來實戰,用爬蟲來實現翻譯器。
我的瀏覽器是360的,一般搜尋“翻譯”的時候,跳出來的都是360翻譯。like that:

寫程式碼前分析下,我們在輸入框輸入一些資訊,資訊被提交到伺服器,伺服器處理完後,將翻譯結果返回,解析後顯示到頁面。我們就看到了翻譯結果,我們要做的:
1、找到返回資訊的url。
2、提取需要資訊。
來看原始地址

當我們在輸入框輸入資訊的時候,看看變化:

這時的地址也就相應的變化:

再來測試:

地址變化:
![]()
有找到規律嗎?基本就是我們的輸出內容,這也就是傳給伺服器的引數,我們看到空格的url編碼程式設計了%20(這裡我不知道說的準不準確,就是對空格進行了可以傳輸的格式轉化。)
我們找到了url,然後提取所需資訊,也就是頁面上“我是一條魚”的中文翻譯。然而,當我們檢視原始碼的時候,在原始碼裡並沒有我們所需資訊,Why?
且聽,原始碼上展現出來的資訊是不可變得,比如<title>主頁</title>。它就只能顯示出來“主頁”,那如果我有許多網頁,且網頁大致的佈局都差不多,只是title不一樣,怎麼辦?多寫幾個網頁不就完了。是,的確可以。如果我有一萬個,即使可以ctrl c,ctrl v,不累嗎。
所以,一般佈局一樣,只是個別東西不同,我門就把那個位置設定成一個變數,讓後根據伺服器返回的引數值對變數賦值,從而在網頁上顯示文字。
所以現在我們的任務是找到那個傳遞引數的url,而不是原始碼的,記住,爬取動態資料,一般情況下原始碼中是找不到的。
Do it.
大部分的瀏覽器都提供了控制檯,一般情況下按F12鍵就會彈出,這裡可以檢視瀏覽器後臺的一些操作。

切換到network模組,按下F5重新整理,頁面重新重新整理,再輸入文字,就能看到一些請求。

So many.你需要做的就是從眾多返回中找到你想要的。
我們看到有個search?......的返回,而且後面的query顯然是我們的輸入結果。Get it. 滑鼠右鍵。“Open in new tab”,就可以看到返回內容。

返回內容是個json,python理解成dict,當然理解成一個字串也沒什麼問題,還是沒有我們要的東西怎麼辦?其實不然,fanyi的關鍵詞的value是"\u6211\u662f\u4e00\u6761\u9c7c\u3002",這麼個東西,敏感的小朋友就知道了,這是Unicode編碼,讓我們用python直接把他輸入來看看吧。
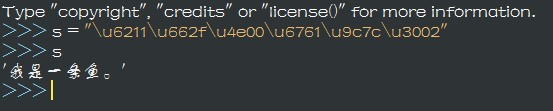
Suprise,這不就是我們想要的東西嗎,看url是什麼,再次進行分析。

沒太大區別,空格用“+”代替,末尾多了個引數eng=1。也就是說當我們請求這個地址的時候,我們就能得到那個json,然後將fanyi的內容拿出來,任務就完成了。
怎麼拿?是個問題,要知道,bs4是針對標記語言的,現在是json。沒辦法用,那就用字串,問題又來了,你輸入的資訊不一樣fanyi位置也不一樣,怎麼辦?
python標準庫json,直接匯入就好,load完生成的物件,可以當成字典來用,很方便吧。
動手吧:
import requests
import json
def english_to_chinese(search):
base = 'https://fanyi.so.com/index/search?query='
url = base + search.replace(' ','+') + '&eng=1'
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(json.loads(r.text)['data']['fanyi'])
except:
print('Fail')
if __name__ == '__main__':
english_to_chinese(input('Please:'))前面講的很詳細,現在看程式碼就很好懂了吧。
這是英譯漢的爬蟲,漢譯英的呢。

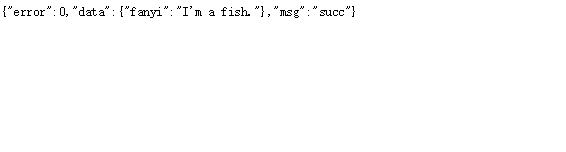
這個好,返回結果都不需要我們處理直接把fanyi內容拿出來就好。url呢?
![]()
哇塞!更簡單直接寫就好了。
問題來了,這是偽地址,滑鼠左鍵點選地址看看:

顯然,下面的才是我們能請求的,問題來了,文字轉換成了一堆不知道是什麼的東西,不用慌,為了資料的傳輸,要將漢子編寫成url編碼。
我們有庫可用,urllib。
在安裝requests的時候應該就已經同時安裝上了,可以通過在命令列輸入 pip list來檢視是否有urllib庫。urllib.parse.quote()方法可以將漢字轉為url編碼。還有一點注意,url中eng的引數值不是1了,而是0.
import urllib.parse
def english_to_chinese(search):
base = 'https://fanyi.so.com/index/search?query='
url = base + search.replace(' ','+') + '&eng=1'
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(json.loads(r.text)['data']['fanyi'])
except:
print('Fail')
def chinese_to_english(seatch):
base = 'https://fanyi.so.com/index/search?query='
url = base + urllib.parse.quote(seatch) + '&eng=0'
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(json.loads(r.text)['data']['fanyi'])
except:
print('Fail')
if __name__ == '__main__':
chose = input('1.English to chinese\n2.Chinese to english\n')
if chose == '1':
while 1:
english_to_chinese(input('Please:'))
elif chose == '2':
while 1:
chinese_to_english(input('請講:'))
這裡我把它們包裝了一下更好看些吧。
試試效果:


還不賴吧。雖然翻譯的有點糟。
基本已完,大家可以定向的去爬小說,圖片。圖片的儲存方式在上篇中的連結中有。最後在說一下歌曲的儲存,和圖片是一樣的。
你需要在程式碼中找到類似這樣的東西:

我們看得到末尾是.mp3。就是他了,請求他返回的就是歌曲資料,記得儲存的時候要以二進位制檔案去寫。
import requests
url = 'http://fs.w.kugou.com/201811151711/88bca4fa27262892e1e66b38725bc683/G117/M05/14/09/VZQEAFpfZSqAPP3BAEHun0d8rZw177.mp3'
r = requests.get(url)
with open('等你下課.mp3', 'wb') as f:
f.write(r.content)原理就這樣,程式碼超簡單。視訊是同樣的道理,只要你能找到url。

ok,結束了,Thanks for watching.