
萬用字元匹配_講解和python3實現
題目描述
給定一個字串 (s) 和一個字元模式 § ,實現一個支援 ‘?’ 和 ‘*’ 的萬用字元匹配。
‘?’ 可以匹配任何單個字元。
‘*’ 可以匹配任意字串(包括空字串)。
兩個字串完全匹配才算匹配成功。
說明:
s 可能為空,且只包含從 a-z 的小寫字母。
p 可能為空,且只包含從 a-z 的小寫字母,以及字元 ? 和 *。
示例 1:
輸入:
s = “aa”
p = “a”
輸出: false
解釋: “a” 無法匹配 “aa” 整個字串。
示例 2:
輸入:
s = “aa”
p = ""
輸出: true
解釋: '’ 可以匹配任意字串。
示例 3:
輸入:
s = “cb”
p = “?a”
輸出: false
解釋: ‘?’ 可以匹配 ‘c’, 但第二個 ‘a’ 無法匹配 ‘b’。
示例 4:
輸入:
s = “adceb”
p = “ab”
輸出: true
解釋: 第一個 ‘’ 可以匹配空字串, 第二個 '’ 可以匹配字串 “dce”.
示例 5:
輸入:
s = “acdcb”
p = “a*c?b”
輸入: false
解題思路
需要明確的是 用 “模式串” 去匹配 “字串” ,迴圈是 模式串在外層迴圈
for p:
for s:
暴力破解1
採用遞迴的思路 碰到 == *== 特殊考慮
solve(i_s,i_p+1) \ * 匹配0 個
or solve(i_s+1,i_p+1) \ *匹配結束
or solve(i_s+1,i_p)) * 繼續匹配下一個
程式碼
def isMatch_brude_force(s, p):
"""
:type s: str
:type p: str
:rtype: bool
"""
len_s=len(s)
len_p=len(p)
def solve(i_s, 動態規劃解答2
這位大佬寫的很好,有圖片解釋
既然用到動態規劃,最重要的是設定初值 和找到遞推式:
我們開始分析初值怎麼設;其實很簡單,把這個匹配問題可以想象成一個矩陣dp,縱軸代表含有萬用字元的匹配字串s2, 橫軸代表要匹配的字串s1。假設現在s2=”a*b”, s1=”abc” 如圖:
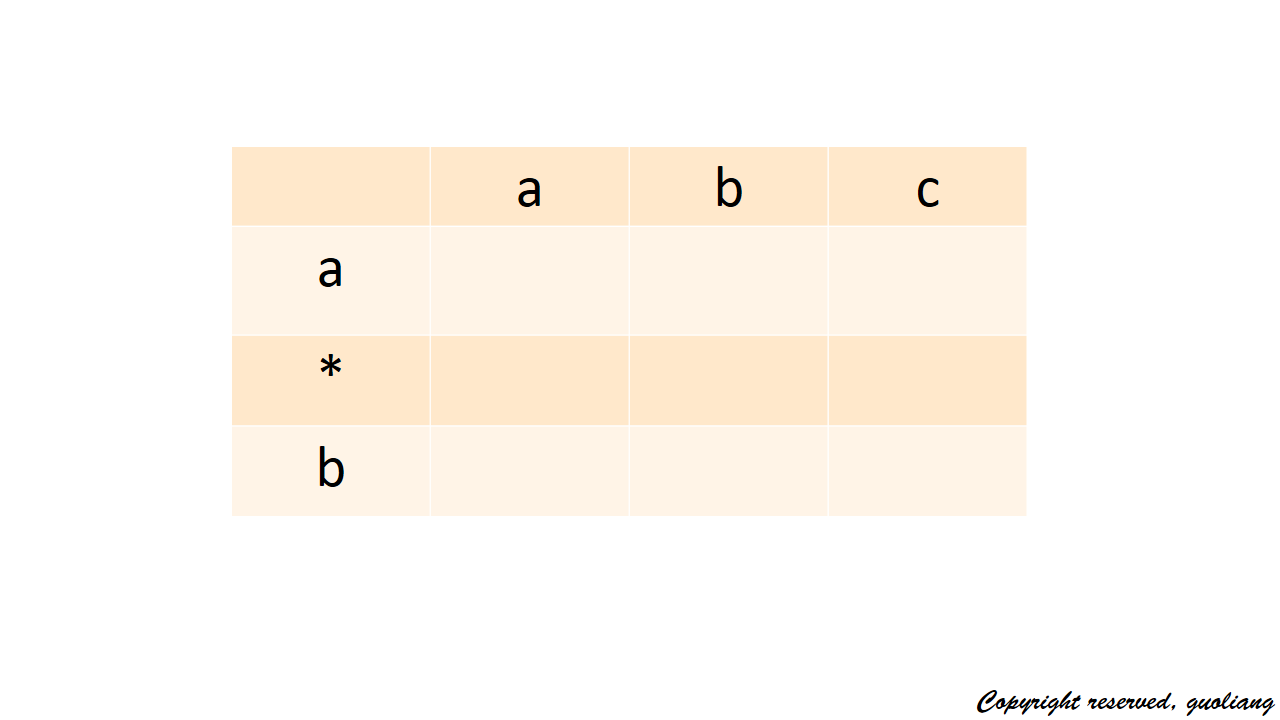
對應空位就是截止到當前的 (i,j) 位置,兩字串是否匹配。匹配為 T(true),不匹配為 F(false),最後返回最右下角的值,就是當前兩個字串是否匹配的最終值;
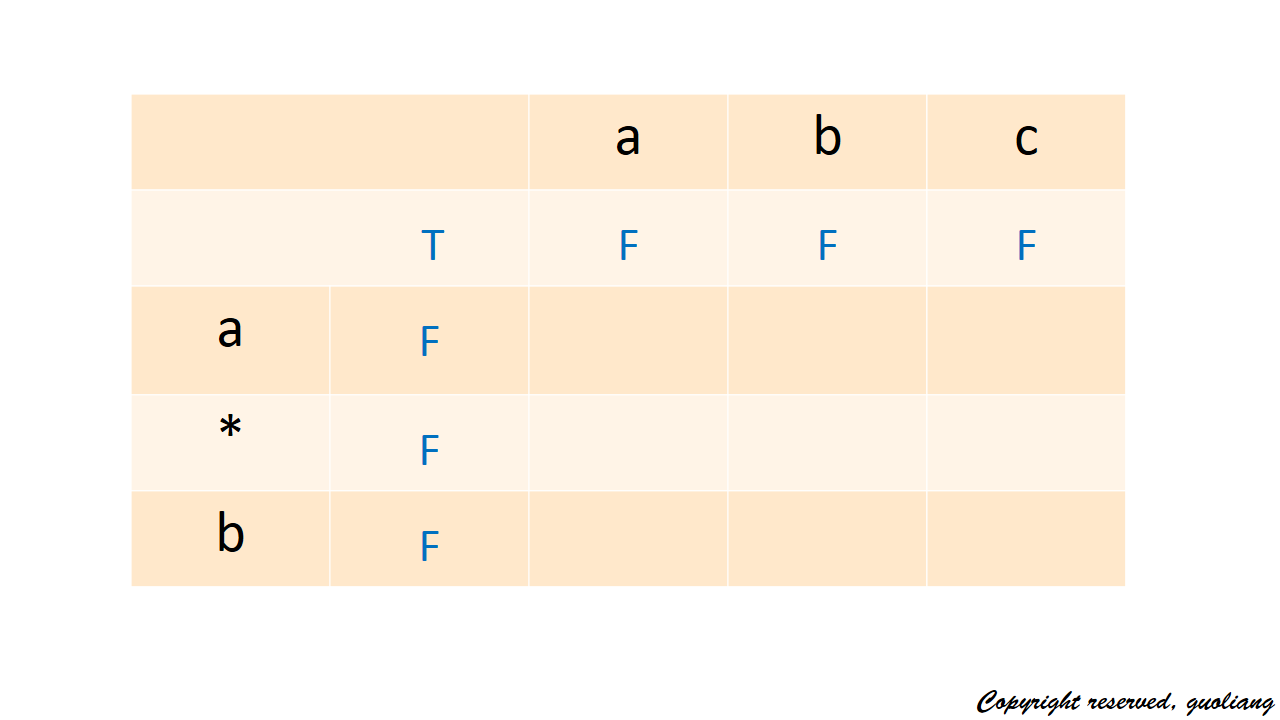
現在我們要做的設定初值,所以我們大可多加一行和一列,來填充初值;s1既然是要匹配的,我們都設為 F(即dp[0][1]=F,dp[0][2]=F,dp[0][3]=F),表示當前還未開始匹配。而s2的初值,我們發現如果星號和a調換位置,星號可以匹配任意字串,所以dp[i][0]的值取決於該位置是否為星號和上一個位置d[i-1][0]是否為T(其實就是上一個位置是否也是星號),所以我們設定dp[0][0]為 T。所以形成下圖:
此時初值已經設定完畢,我們要找到遞推式;經區域性推算,我們發現遞推式應該有兩種,一種是當s2的字元是星號,另一種是s2的字元是非星號。
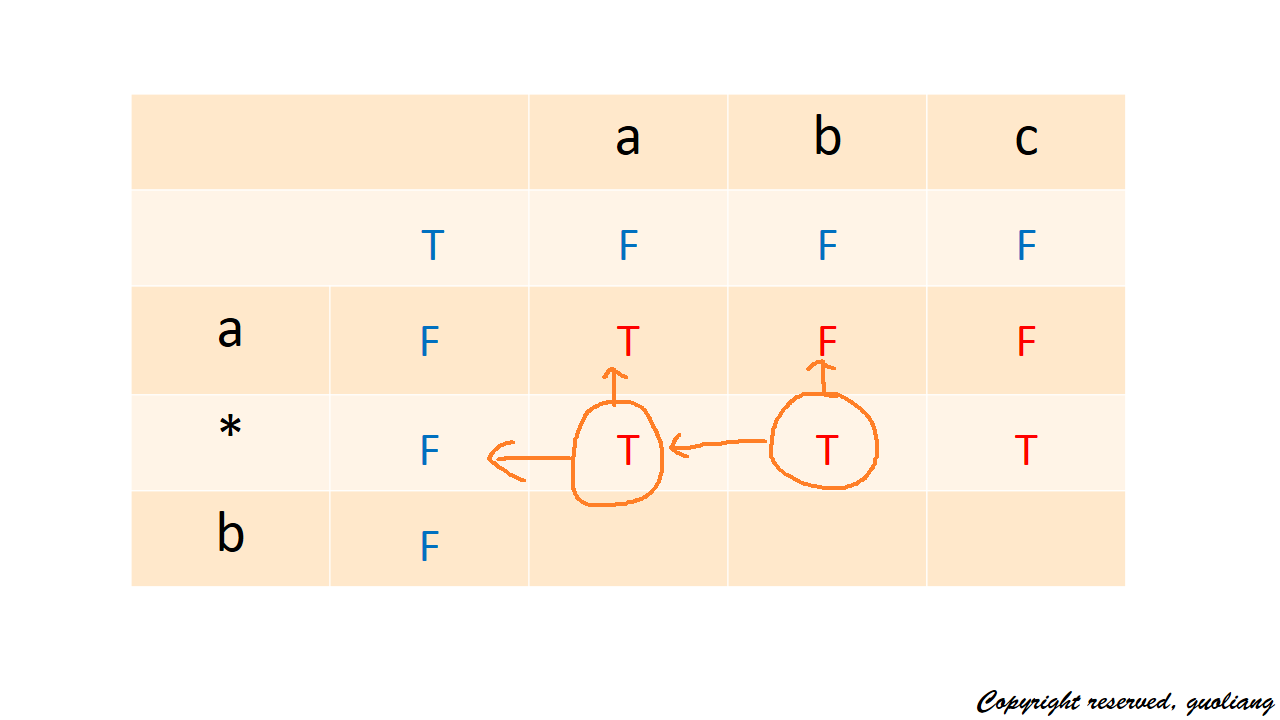
先看星號的情況:當要計算dp[2][1](即要匹配a和a時),我們發現是取決於dp[1][1](即a和a是否匹配),當要計算dp[2][2] (即要匹配a和ab時),是取決於dp[2][1] (即a*和a是否匹配)。抽象一下,星號和任意字元(0或多個)都匹配。所以字串截止到星號匹配的情況,取決於當前位置向上和向左的情況(即可以為0個字元,也可以為多個字元)。
所以此時遞推式為dp[i][j]=dp[i−1][j]||dp[i][j−1]dp[i][j]=dp[i−1][j]||dp[i][j−1] 如圖:
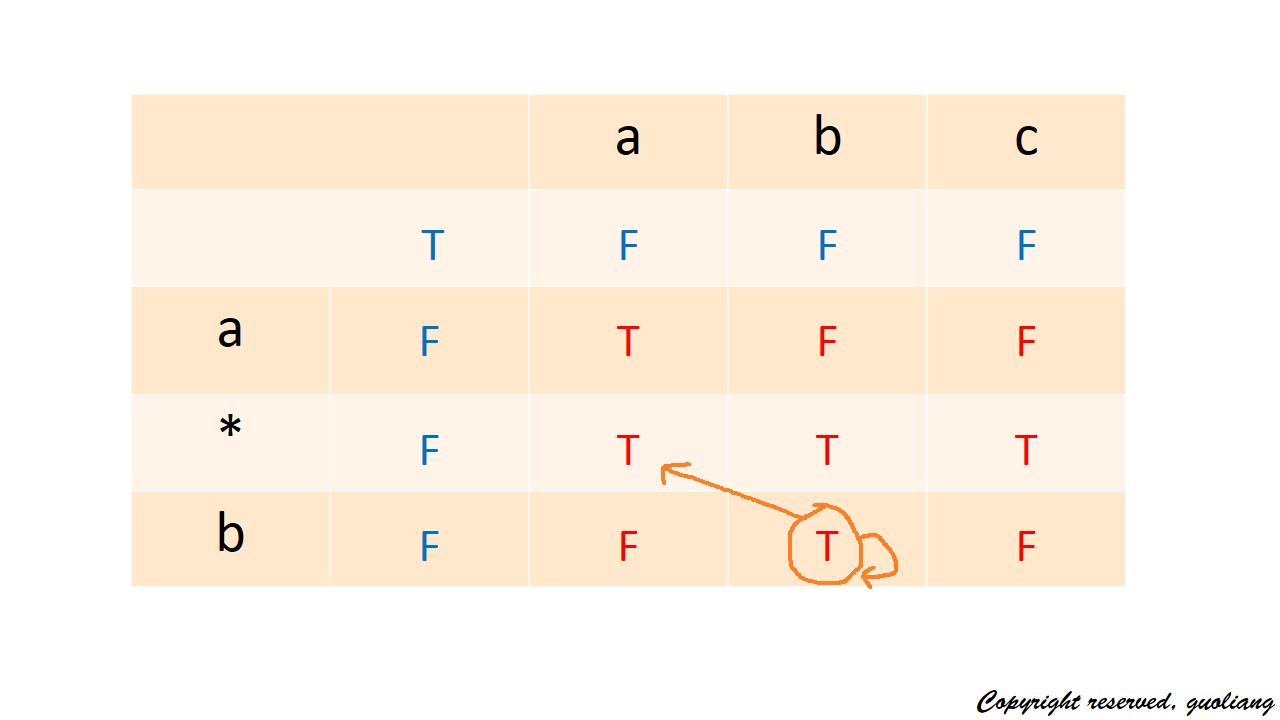
再看非星號的情況:當要計算dp[3][2] (即要匹配ab和ab時),則取決於dp[2][1]和a[3][2] (即a和a是否匹配,同時b和b是否匹配);所以可以得到遞推式 dp[i][j] = dp[i-1][j-1]&&a[i][j]dp[i][j] = dp[i-1][j-1]&&a[i][j]。如圖:
python3 程式碼實現
def isMatch_dp(s,p):
len_s=len(s)
len_p=len(p)
dp=[[False]*(len_s+1) for _ in range(len_p+1)]
dp[0][0]=True
for i in range(1,len_p+1):
char_p = p[i-1]
dp[i][0] = (dp[i-1][0] and char_p == "*")
for j in range(1,len_s+1):
char_s=s[j-1]
if char_p=="*":
dp[i][j]=(dp[i-1][j] or dp[i][j-1])
else:
dp[i][j]=(dp[i-1][j-1] and (char_p=="?" or char_p == char_s))
return dp[len_p][len_s]
下面這一種方法 trick (我沒看,不過程式碼是正確的,我從其他地方複製過來的)
主要是星號的匹配處理。遇到星號就跳過去,優先用星號後面的來匹配。如果星號後面的匹配不上,則用星號匹配一個字元,再看星號後面的能否匹配上
def isMatch_most_difficult(s, p):
scur, pcur, sstar, pstar = 0, 0, None, None
while scur < len(s):
if pcur < len(p) and p[pcur] in [s[scur], '?']:
scur, pcur = scur+1, pcur+1
elif pcur < len(p) and p[pcur] == '*':
pstar, pcur = pcur, pcur+1
sstar = scur
elif pstar != None:
pcur = pstar + 1
sstar += 1
scur = sstar
else:
return False
while pcur < len(p) and p[pcur] == '*':
pcur += 1
return pcur >= len(p)