
Flink程式設計練習(二)
Map
班級學生成績的隨機生成
- 輸入:本班同學的學號
- 輸出:<學號,成績>
資料準備
-
首先需要一個
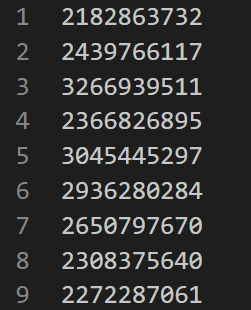
stuID.csv檔案,每一列為一個學號: -
然後將檔案放入
HDFS中:hdfs dfs put stuID.csv input
編寫程式
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache. 注意點
- Flink提供了一個
ParameterTool用於簡化命令列引數的工具 - 使用匿名函式新建運算元是一種很常見的操作
執行
首先確保已經打開了Flink,並在JAR包下執行
flink run -c StuScore StuScore.jar --input /home/hadoop/Documents/distribution/Flink/StuScore/stuID.csv
這裡可以用--output指定輸出路徑,預設為標準輸出
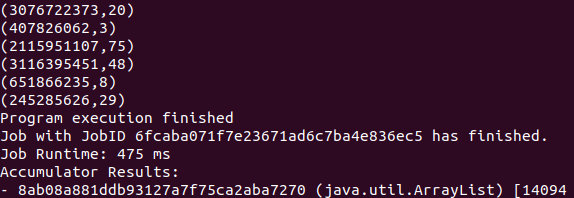
檢視結果
reduceByKey
問題
求平均成績:將全班同學每隔5號分為一組,求每組的平均成績
輸入: <學號,成績>
輸出:<組號,平均分>
資料準備
-
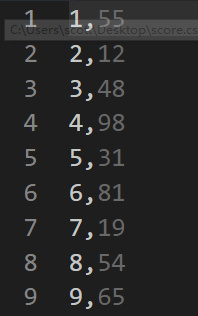
首先需要一個
score.csv檔案,每一列為學號和學生成績:
編寫程式
import org.apache.commons.compress.archivers.dump.DumpArchiveEntry;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
public class AVGscore {
private static Integer groupSize = 5;
public static void main(String[] args) throws Exception {
ParameterTool params = ParameterTool.fromArgs(args);
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(params);
DataSet<Tuple2<Integer, Double>> fileDataSet;
if (params.has("input")) {
fileDataSet = env.readCsvFile(params.get("input"))
.types(Integer.class, Double.class);
} else {
System.out.println("Please confirm input keywords!");
return;
}
/**
* map string to (id, score) and convert to (group_id, (score,1))
* GroupBy and reduce == reduceByKey
* and then map to avg score
*/
DataSet<Tuple2<Integer, Double>> stuAVGscore = fileDataSet
.map(line -> Tuple2.of(
(line.f0-1)/ 5, Tuple2.of(line.f1, 1)))
.returns(Types.TUPLE(Types.INT, Types.TUPLE(Types.DOUBLE, Types.INT)))
.groupBy(0)
.reduce(
(kv1, kv2) -> Tuple2.of(kv1.f0, Tuple2.of(kv1.f1.f0 + kv2.f1.f0, kv1.f1.f1 + kv2.f1.f1)))
.returns(Types.TUPLE(Types.INT, Types.TUPLE(Types.DOUBLE, Types.INT)))
.map(
line -> Tuple2.of(line.f0, line.f1.f0 / line.f1.f1)
).returns(Types.TUPLE(Types.INT, Types.DOUBLE));
//如果沒有指定輸出,則預設列印到控制檯
if (params.has("output")) {
stuAVGscore.writeAsCsv(params.get("output"), "\n", ",");
env.execute();
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
stuAVGscore.print();
}
}
}
注意點
- Flink與Spark不同,沒有reduceByKey等運算元,都是使用group field進行計算,還沒找到更好的方法,具體參考這裡
- 在Flink中,使用Lambda表示式不一定是更好的選擇,因為對於每個Lambda表示式,Flink都要求顯示的指定返回值(returns)
執行
執行程式
flink run -c AVGscore AVGscore.jar --input /home/hadoop/Documents/distribution/Flink/AVGscore/score.csv
檢視結果:
Natural join
資料準備
有兩個檔案
-
person.txt
1 Aaron 210000
2 Abbott 214000
3 Abel 221000
4 Abner 215000
5 Abraham 226000
6 Adair 225300
7 Adam 223800
8 Addison 224000
9 Adolph 223001 -
address.txt
210000 Nanjing
214000 Wuxi
221000 Xuzhou
213000 Changzhou
要求以code為連線屬性,匹配出person中每個人所在的位置資訊;每條記錄各個欄位之間以空格為分隔符。
編寫程式
import org.apache.flink.api.common.functions.FlatJoinFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.util.Collector;
import scala.Int;
import java.lang.reflect.Type;
public class NaturalJoin {
public static void main(String args[]) throws Exception{
ParameterTool params = ParameterTool.fromArgs(args);
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(params);
// code, city
DataSet<Tuple2<Integer, String>> addDataSet;
// id ,name, code
DataSet<Tuple3<Integer, String, Integer>> personDataSet;
if (params.has("addinput")) {
addDataSet = env.readCsvFile(params.get("addinput"))
.fieldDelimiter(" ")
.ignoreInvalidLines()
.types(Integer.class, String.class);
} else {
System.out.println("Please confirm input keywords!");
return;
}
if (params.has("personinput")) {
personDataSet = env.readCsvFile(params.get("personinput"))
.fieldDelimiter(" ")
.ignoreInvalidLines()
.types(Integer.class, String.class, Integer.class);
} else {
System.out.println("Please confirm input keywords!");
return;
}
DataSet<Tuple4<Integer, String, Integer, String>> result = personDataSet.join(addDataSet)
.where(2)
.equalTo(0)
.with(
(x, y) -> Tuple4.of(x.f0, x.f1, x.f2, y.f1)
).returns(Types.TUPLE(Types.INT,Types.STRING,Types.INT,Types.STRING));
personDataSet.print();
//如果沒有指定輸出,則預設列印到控制檯
if (params.has("output")) {
result.writeAsCsv(params.get("output"), "\n", ",");
env.execute();
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
result.print();
}
}
}
注意點
- 這裡需要格外注意的是,本檔案存在缺失值,這樣會導致readCsvFile失效,因此需要忽略有缺失值的列
- flink關於DataSet join 的介紹
執行
本地執行
執行程式並檢視結果
flink run -c NaturalJoin NaturalJoin.jar --addinput /home/hadoop/Documents/distribution/Flink/NaturalJoin/address.txt --personinput /home/hadoop/Documents/distribution/Flink/NaturalJoin/person.txt
Kmeans
資料準備
輸入資料(k-means.dat):
4,400
96,826
606,776
474,866
400,768
2,920
356,766
36,687
-26,824
- 第一行標明K的值和資料個數N, 均為整形, 由","隔開 (如 3,10 表示K=3, N=10)。
- 之後N行中每行代表一個二維向量, 向量元素均為整形, 由","隔開 (如 1,2 表示向量(1, 2))。
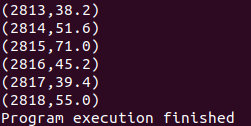
輸出: K行, 每行是一個聚類圖心的二維向量, 向量元素均為浮點型 (如 1.1,2.3)。
編寫程式
point.java
用於自定義point類(POJO物件)
import java.io.Serializable;
public class Point implements Serializable {
public double x,y;
public Point() {
}
public Point(double x, double y) {
this.x = x;
this.y = y;
}
public Point add(Point other) {
x += other.x;
y += other.y;
return this;
}
public Point div(long val) {
x /= val;
y /= val;
return this;
}
public double euclideanDistance(Point other) {
return Math.sqrt((x - other.x) * (x - other.x) + (y - other.y) * (y - other.y));
}
public String toString() {
return x + " " + y;
}
}
kmeansRun.java
import org.apache.flink.api.common.functions.*;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.functions.FunctionAnnotation;
import org.apache.flink.api.java.operators.IterativeDataSet;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.Collection;
public class Kmeans {
public static void main(String[] args) throws Exception {
// Checking input parameters
final ParameterTool params = ParameterTool.fromArgs(args);
// set up execution environment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(params); // make parameters available in the web interface
// get input data:
DataSet<Point> points = getPoint(params, env);
if (points == null)
return;
DataSet<Centroid> centroids = getCentroid(params, env);
// set number of bulk iterations for KMeans algorithm
IterativeDataSet<Centroid> loop = centroids.iterate(params.getInt("iterations", 100));
DataSet<Centroid> newCentroids = points
// compute closest centroid for each point
.map(new SelectNearestCenter()).withBroadcastSet(loop, "centroids")
// count and sum point coordinates for each centroid
.map(new CountAppender())
.groupBy(0).reduce(new CentroidAccumulator())
// compute new centroids from point counts and coordinate sums
.map(new CentroidAverager());
// feed new centroids back into next iteration
DataSet<Centroid> finalCentroids = loop.closeWith(newCentroids, newCentroids.filter(new thresholdFilter()).withBroadcastSet(loop,"centroids"));
// DataSet<Tuple2<Integer, Point>> clusteredPoints = points
// // assign points to final clusters
// .map(new SelectNearestCenter()).withBroadcastSet(finalCentroids, "centroids");
// emit result
if (params.has("output")) {
finalCentroids.writeAsCsv(params.get("output"), "\n", " ");
env.execute();
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
finalCentroids.print();
}
}
private static DataSet<Point> getPoint(ParameterTool params, ExecutionEnvironment env) {
DataSet<Point> points;
if (params.has("input")) {
// read points from CSV file
points = env.readCsvFile(params.get("input"))
相關推薦
Flink程式設計練習(二)
Map
班級學生成績的隨機生成
輸入:本班同學的學號
輸出:<學號,成績>
資料準備
首先需要一個stuID.csv檔案,每一列為一個學號:
然後將檔案放入HDFS中: hdfs d
Flink程式設計練習(一)
Flink程式設計練習,NYC計程車資料
環境配置
本專案參考這裡,setup。
首先確保已經下載好flink依賴,並從Github下載程式碼。
下載依賴資料,這裡依賴的是紐約出租車資料,可以使用命令列下載:
wget http
Java 由淺入深GUI程式設計實戰練習(二)
一,專案簡介
1.利用Java GUI 繪製圖像介面,設定整體佈局
2.編寫一個隨機數生成1~100的隨機數
3.編寫一個驗證類,用於驗證使用者輸入值與生成隨機數是否相等並記錄使用者猜測次數,當用戶猜測成功或者超過5次結束遊戲
二,執行介面
三,程式碼實現
import java.awt
Shell指令碼程式設計之(二)簡單的Shell指令碼練習
練習題1:互動式指令碼(使用者決定變數內容)
程式碼
[[email protected] bin]$ vim showname.sh
#!/bin/bash
# Program:
# User inputs his first name and last
Shell練習(二)
odi tool 一次 pan debug load default subject class 習題1:統計內存使用要求:寫一個腳本計算一下linux系統所有進程占用內存大小的和。(提示:使用ps或者top命令)參考答案:#!/bin/bash
# date:2018年2
Leetcode代碼練習(二)
sts compare bre 那種 character span 一次 給定 spa 首先,沒有第二題,沒有第二題的原因是,JavaScript中根本就沒有那種數據結構,盡管我在playground裏面調試出了正確的結果,但是也許是因為數據結構問題,最終沒能讓我通過。
所
SQL作業:綜合練習(二)的返評
庫文件 spl val 查找 括號 冰箱 HR 題目 tar 一:作業題目:綜合練習(二)
二:題目要求:
1、創建數據庫CPXS,保存於E盤根目錄下以自己學號+姓第一個字母(阿拉伯數字+大寫字母)方式創建的文件夾中,初始大小5MB,最大20MB,以10%方式增長,日誌文件
PL/SQL 上機練習(二)
tinc ace end from func fun gin spa PE 函數:1.
函數查看字符串中共包含幾個某特殊字符,如‘A**B*CEDF‘中包含幾個‘*’
2.函數把員工表中不同的工作連接成一個字符串
3.函數計算個人所得稅,工資,薪金所得減3500, 含稅
ProtoBuf練習(二)
.proto fstream using 讀寫 get run pro 長度 返回對象 重復數據類型
protobuf語言的重復字段類型相當於C++的std::list數據類型
工程目錄結構
$ ls proto/
TServer.proto TSession.proto
Python基礎練習(二)筆趣看《伏天氏》全文章節爬取
平臺 空行 ges 會有 好的 clas 追加 ref 版本 大家如果覺得有幫助的話,可以關註我的知乎https://www.zhihu.com/people/hdmi-blog/posts,裏面有寫了一些我學習爬蟲的練習~
今天我們想要爬取的是筆趣看小說網上的網絡小說,並
Java練習(二)
ins == rime lse new ring 素數 如果能 main 題目:判斷101-200之間有多少個素數,並輸出所有素數。
判斷素數的方法:用一個數分別去除2到sqrt(這個數),如果能被整除,則表明此數不是素數,反之是素數。
public class Test
Linux學習之shell 程式設計基礎(二)
一、bash環境變數
HOME、MAIL、SHELL、PATH 等,環境變數大都用大寫字母組成
[[email protected] dalianmao]# echo $SHELL
/bin/bash
[[email protected] dalianmao]# echo
Redtiger SQL注入練習(二)
第六關:
點選 click me,構造url:user=1',返回user not found。user=1'',同樣。
猜測是數字型注入,構造order by , user=1 order by X#,得出有5個欄位。
然後,user=0 union select 1,2,3,4,5#,說
某演算法的板子練習(二)
題目:P3379
樹上LCA,本蒟蒻罕見的一遍A掉的板子
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<algor
hadoop程式設計實踐(二)
叢集上使用
jar包
首先將之前FileExist檔案進行打包,得到.jar檔案:
將其拷貝到叢集中,並使用hadoop jar命令執行:
WordCount
新增依賴
Linux命令列與shell指令碼程式設計大全(二)
十一、處理使用者輸入
命令列引數
讀取引數: $0是程式名,$1是第一個引數,$2是第二個引數,以此類推,直到第9個引數$9。當引數個數超過10以後,需要在變數數字周圍加上花括號,如${10},如果輸入到命令列的引數是字串且含有空格,需要使用引號。
#! /bin/bash
echo
程式設計練習(1)
題目:
1 有這樣一個數字,ABCD * E ==DCBA ,其中各個數字不相等,編寫一個程式,計算出ABCD各代表什麼數字。
#include <stdio.h>
int fun(int i,i
專案練習(二)—微博資料結構化
1.ETL概念 ETL,是英文 Extract-Transform-Load 的縮寫,用來描述將資料從來源端經過抽取(extract)、互動轉換(transform)、載入(load)至目的端的過程。
2.專案目標:
本次專案側重於資料的整合(即將檔案中
MySql必知必會實戰練習(三)資料過濾 MySql必知必會實戰練習(二)資料檢索
在之前的部落格MySql必知必會實戰練習(一)表建立和資料新增中完成了各表的建立和資料新增,MySql必知必會實戰練習(二)資料檢索中介紹了所有的資料檢索操作,下面對資料過濾操作進行總結。
1. where子句操作符
等於: =
不等於: != 或 <>
小於:
javaScript面向物件程式設計-繼承(二)
原型繼承
原型繼承是對類式繼承的一種封裝,其中的過渡物件就相當於類式繼承中的子類,只是在原型式中作為一個過渡物件出現,目的是建立要返回的新的例項化物件。和類式繼承一樣,父類物件book中指型別的屬性被複制,引用型別的屬性被共有。
//原型是繼承
function i