
大資料場景-使用者行為日誌分析
阿新 • • 發佈:2018-12-24
使用者日誌:
訪問的系統屬性:作業系統、瀏覽器型別
訪問特徵:點選的URL、來源(referer)url [推廣]、頁面停留時間
訪問資訊:session_id,訪問IP
價值:分析每個使用者的使用場景頻率高的業務點,分析每個使用者的IP 【解析到城市資訊】,根據使用者瀏覽商品打瀏覽標籤精準推薦商品 等等…
- 資料處理
有資料者有未來,有資料意味著每一份使用者行為資料都是寶貴的資源。經過資料清洗,再用演算法提取分析,商業價值,商業決策、線上推廣 等等….當然一切建立在有大量使用者有流量的情況下的。
資料處理流程
資料採集:
Flume:將記錄的使用者行為日誌提取至HDFS
資料清洗:
髒資料
Spark、Hive、MapReduce 或者是其他的分散式計算框架
清洗完的資料可以放到HDFS(HDFS,Spark SQL)
資料處理:
按照我們的需要進行相應的業務統計與分析
Spark、Hive、MapReduce 或者是其他的分散式計算框架
處理結果入庫:
分析處理結果資料儲存至:NoSQL、RDBMS
資料視覺化
通過圖形化展示出計算出來的資料結果
Echarts、HUE 等…
- 大資料處理架構
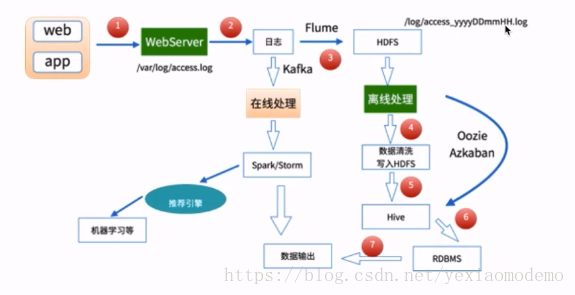
一個典型的簡單版本的使用者行為大資料處理架構。離線資料處理