
SpringBoot整合Spring Data Elasticsearch基本使用
Elasticsearch是基於Lucene的全文檢索庫,本質也是儲存資料,很多概念與MySQL類似的。
對比關係:
索引庫(indices)--------------------------------Databases 資料庫
型別(type)-----------------------------Table 資料表
文件(Document)----------------Row 行
欄位(Field)-------------------Column 列
詳細說明:
| 概念 | 說明 |
|---|---|
| 索引庫(indices) | indices是index的複數,代表許多的索引, |
| 型別(type) | 型別是模擬mysql中的table概念,一個索引庫下可以有不同型別的索引,比如商品索引,訂單索引,其資料格式不同。不過這會導致索引庫混亂,因此未來版本中會移除這個概念 |
| 文件(document) | 存入索引庫原始的資料。比如每一條商品資訊,就是一個文件 |
| 欄位(field) | 文件中的屬性 |
| 對映配置(mappings) | 欄位的資料型別、屬性、是否索引、是否儲存等特性 |
是不是與Lucene中的概念類似。
另外,在Elasticsearch有一些叢集相關的概念:
- 索引集(Indices,index的複數):邏輯上的完整索引
- 分片(shard):資料拆分後的各個部分
- 副本(replica):每個分片的複製
要注意的是:Elasticsearch本身就是分散式的,因此即便你只有一個節點,Elasticsearch預設也會對你的資料進行分片和副本操作,當你向叢集新增新資料時,資料也會在新加入的節點中進行平衡(負載均衡)。
原生java整合elasticsearch的API地址:(類似JDBC)
https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.2/java-docs.html
Elasticsearch提供的Java客戶端有一些不太方便的地方:
- 很多地方需要拼接Json字串,在java中拼接字串有多恐怖你應該懂的
- 需要自己把物件序列化為json儲存
- 查詢到結果也需要自己反序列化為物件
因此,為了方便,用Spring提供的套件:Spring Data Elasticsearch
1.簡介
Spring Data Elasticsearch是Spring Data專案下的一個子模組。
檢視 Spring Data的官網:http://projects.spring.io/spring-data/

Spring Data 是的使命是給各種資料訪問提供統一的程式設計介面,不管是關係型資料庫(如MySQL),還是非關係資料庫(如Redis),或者類似Elasticsearch這樣的索引資料庫。從而簡化開發人員的程式碼,提高開發效率。
包含很多不同資料操作的模組:

Spring Data Elasticsearch的頁面:https://projects.spring.io/spring-data-elasticsearch/

特徵:
- 支援Spring的基於
@Configuration的java配置方式,或者XML配置方式 - 提供了用於操作ES的便捷工具類**
ElasticsearchTemplate**。包括實現文件到POJO之間的自動智慧對映。 - 利用Spring的資料轉換服務實現的功能豐富的物件對映
- 基於註解的元資料對映方式,而且可擴充套件以支援更多不同的資料格式
- 根據持久層介面自動生成對應實現方法,無需人工編寫基本操作程式碼(類似mybatis,根據介面自動得到實現)。當然,也支援人工定製查詢
1.2.建立Demo工程
我用指令碼建立的
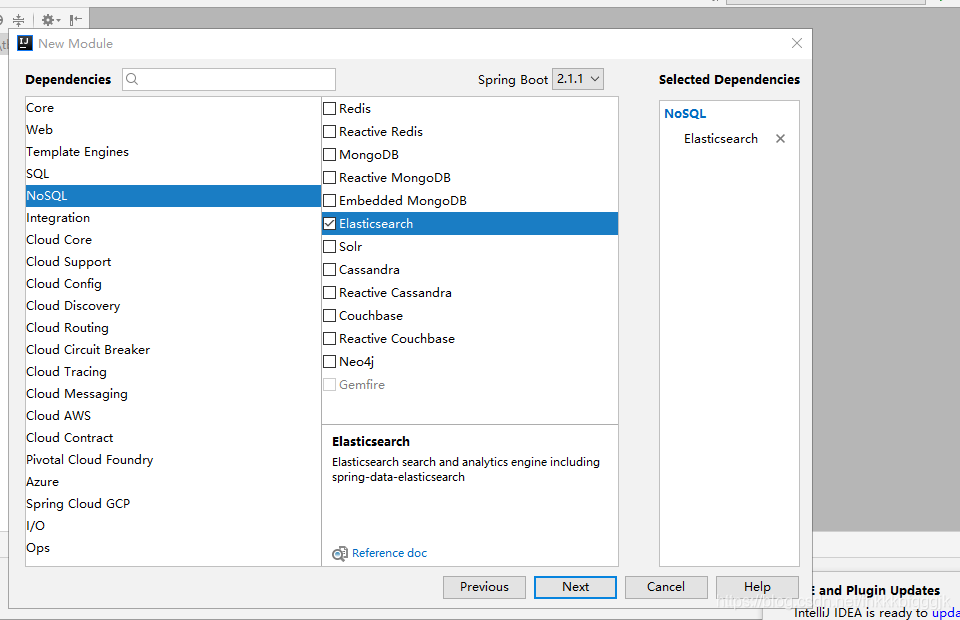
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
application.yml檔案配置:
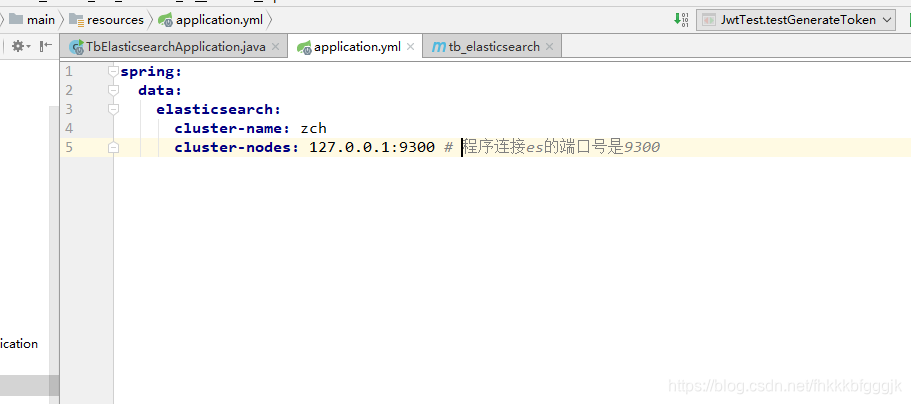
1.3.索引操作
1.3.1.建立索引和對映
SpringBoot-data-elasticsearch提供了面向物件的方式操作elasticsearch
業務:將商品的資訊存入elasticsearch,並且執行搜尋操作
對映—註解
建立一個商品物件,有這些屬性:
答:id 編號,title 標題,category 分類,brand 品牌,price 價格, 圖片地址
在SpringDataElasticSearch中,只需要操作物件,就可以操作elasticsearch中的資料
Spring Data通過註解來宣告欄位的對映屬性,有下面的三個註解:
@Document作用在類,標記實體類為文件物件,一般有兩個屬性- indexName:對應索引庫名稱
- type:對應在索引庫中的型別
- shards:分片數量,預設5
- replicas:副本數量,預設1
@Id作用在成員變數,標記一個欄位作為id主鍵@Field作用在成員變數,標記為文件的欄位,並指定欄位對映屬性:- type:欄位型別,是列舉:FieldType,可以是text、long、short、date、integer、object等
- text:儲存資料時候,會自動分詞,並生成索引
- keyword:儲存資料時候,不會分詞建立索引
- Numerical:數值型別,分兩類
- 基本資料型別:long、interger、short、byte、double、float、half_float
- 浮點數的高精度型別:scaled_float
- 需要指定一個精度因子,比如10或100。elasticsearch會把真實值乘以這個因子後儲存,取出時再還原。
- Date:日期型別
- elasticsearch可以對日期格式化為字串儲存,但是建議我們儲存為毫秒值,儲存為long,節省空間。
- index:是否索引,布林型別,預設是true
- store:是否儲存,布林型別,預設是false
- analyzer:分詞器名稱,這裡的
ik_max_word即使用ik分詞器
- type:欄位型別,是列舉:FieldType,可以是text、long、short、date、integer、object等
實體類
首先我們準備好實體類:
/**
* indexName="索引庫的名字"
* type:表名
* shards:分片的數量,elasticsearch自動叢集,預設一個數據放6個地方
* replicas:隱藏的一個分片
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "zch",type = "zch", shards = 1, replicas = 0)
public class zch {
@Id
private Long id;
@Field(type = FieldType.text, analyzer = "ik_max_word")
private String title; //標題
@Field(type = FieldType.keyword)
private String category;// 分類
@Field(type = FieldType.keyword)
private String brand; // 品牌
@Field(type = FieldType.Double)
private Double price; // 價格
@Field(index = false, type = FieldType.keyword)
private String images; // 圖片地址
}
建立索引
ElasticsearchTemplate中提供了建立索引的API:
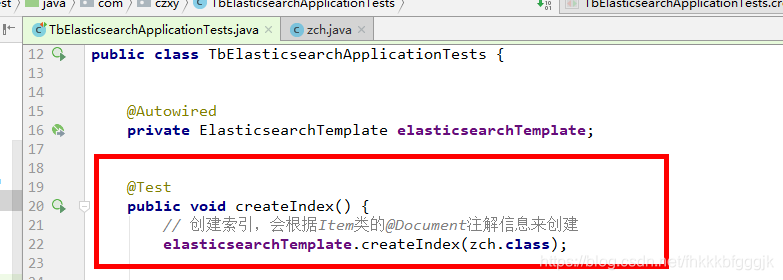
- 可以根據類的資訊自動生成,也可以手動指定indexName和Settings
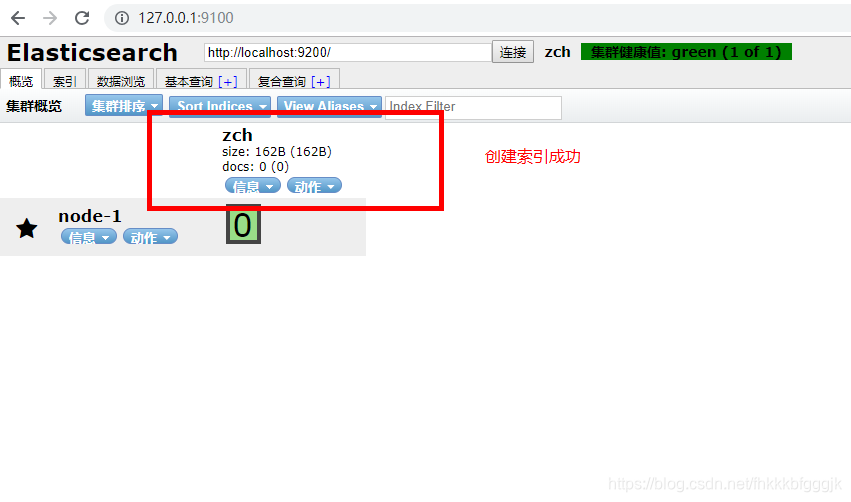
對映相關的API:
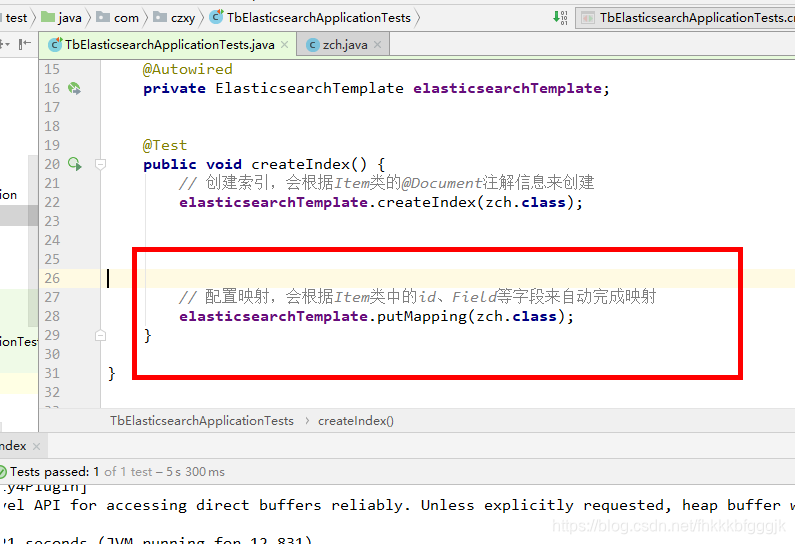
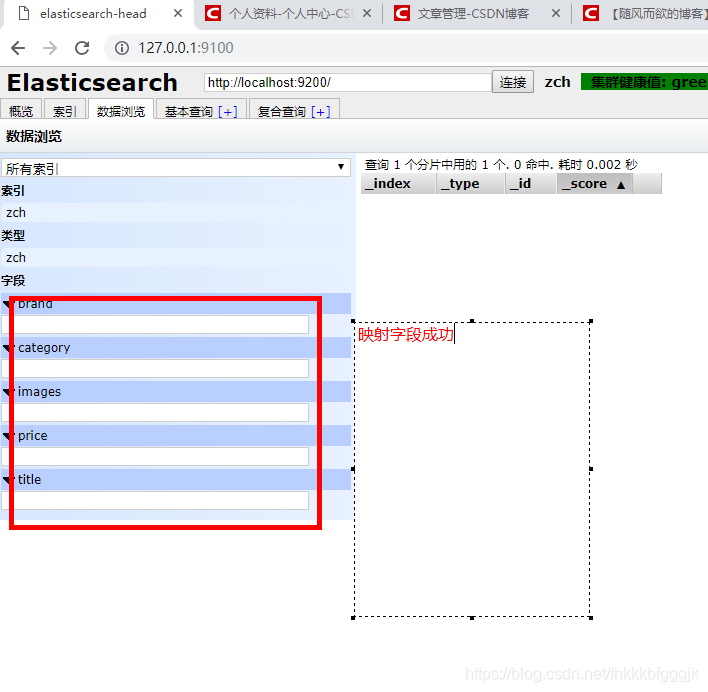
索引資訊:
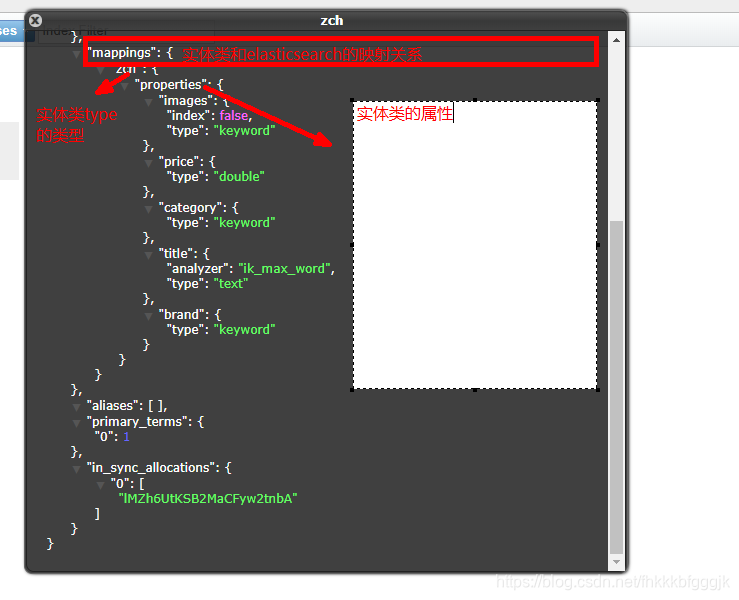
1.3.2.刪除索引
刪除索引的API:
可以根據類名或索引名刪除。

1.4.新增文件資料
1.4.1.Repository介面
Spring Data 的強大之處,就在於你不用寫任何DAO處理,自動根據方法名或類的資訊進行CRUD操作。只要你定義一個介面,然後繼承Repository提供的一些子介面,就能具備各種基本的CRUD功能。
來看下Repository的繼承關係:
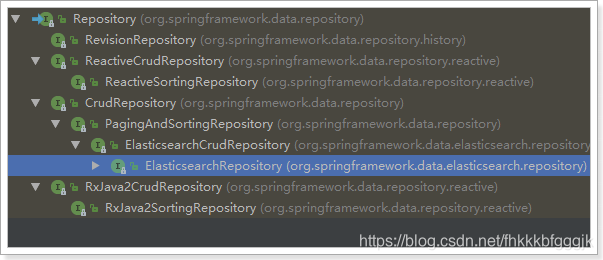
我們看到有一個ElasticsearchCrudRepository介面:
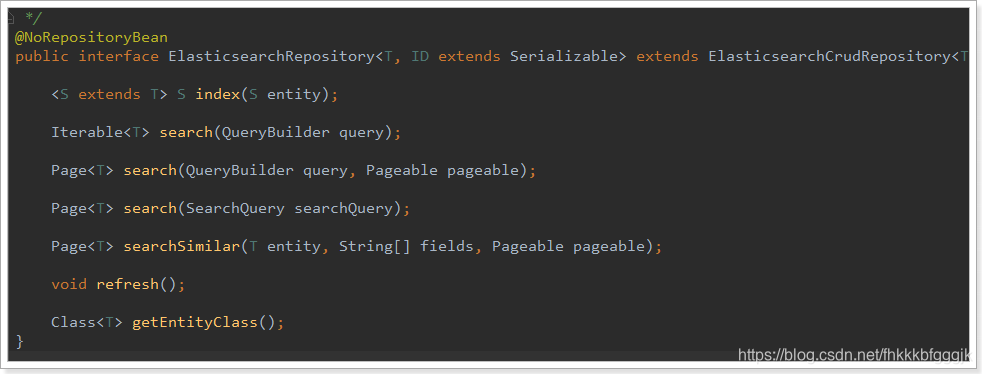
所以,我們只需要定義介面,然後繼承它就OK了。
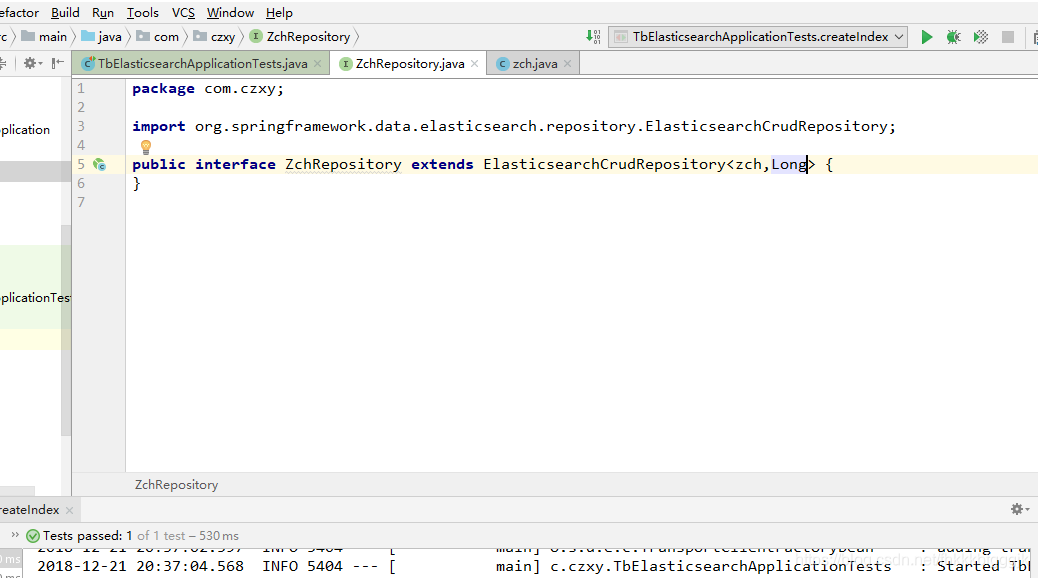
接下來,我們測試新增資料:
1.4.2.新增一個物件
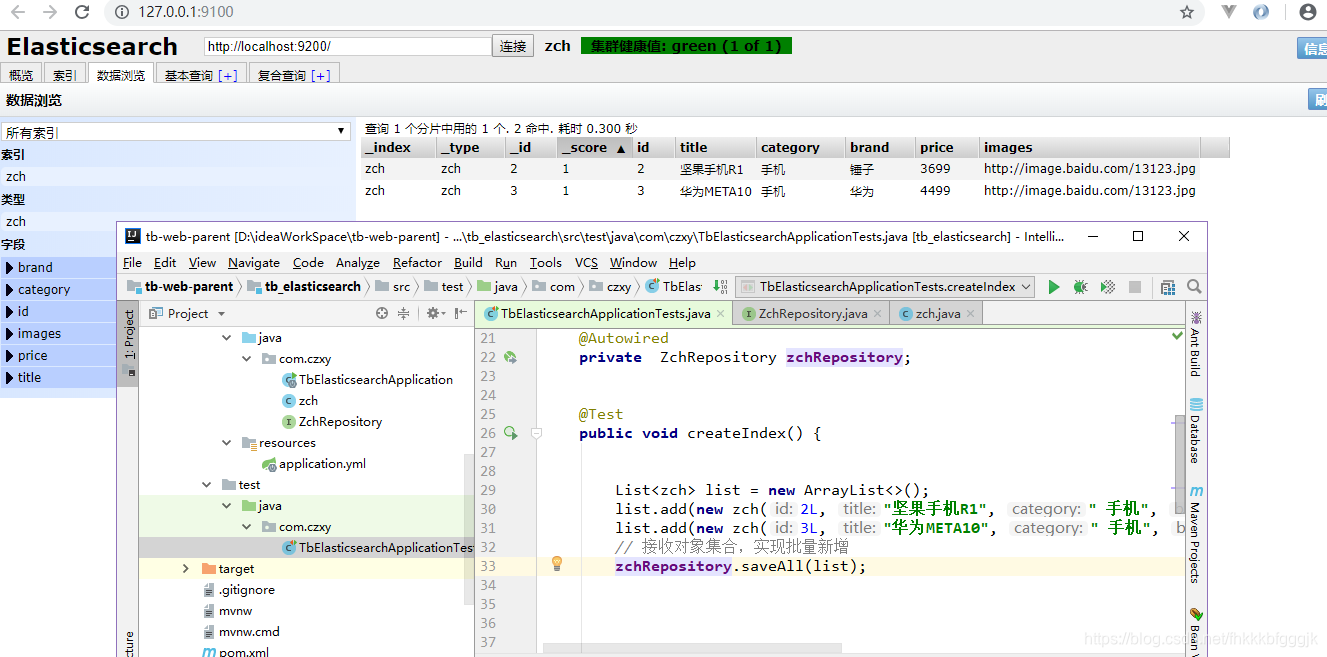
1.4.4.修改
elasticsearch中本沒有修改,它是先刪除再新增
修改和新增是同一個介面,區分的依據就是id。