tensorflow之並行讀入資料
最近研究了一下並行讀入資料的方式,現在將自己的理解整理如下,理解比較淺,僅供參考。
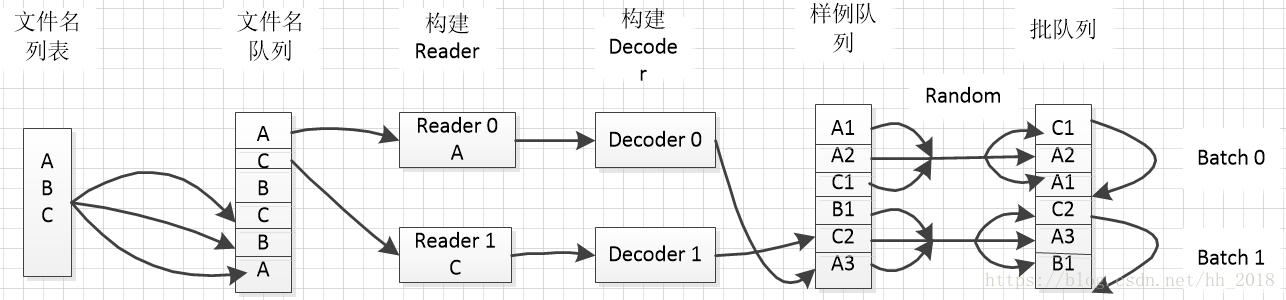
並行讀入資料主要分
1. 建立檔名列表
2. 建立檔名佇列
3. 建立Reader和Decoder
4. 建立樣例列表
5. 建立批列表(讀取時可要可不要,一般情況下樣例列表可以執行讀取資料操作,但是在實際訓練的時候往往需要批列表來分批進行資料的組織,提取)
其具體流程如下:
一、 檔名列表:
檔名列表是一個list型別的資料,裡面的內容是需要用的資料檔名。可以使用常規的python語法入:[file1, file2]。也可以使用tf.train.match_filename_once方法通過匹配輸入。
二、檔名佇列
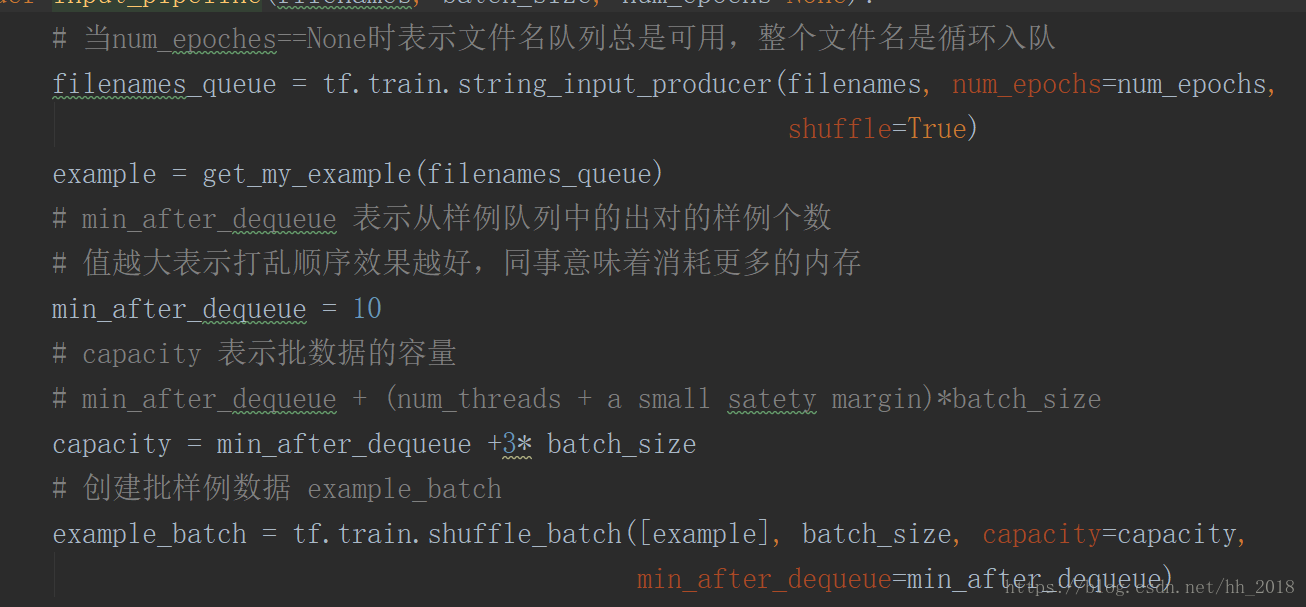
一般使用tf.train.string_input_producer的方法建立檔名佇列。該方法傳入的是一個檔名列表,輸出的是一個先進先出佇列。在該方法中存在兩個重要引數,num_epochs和shuffle。num_epochs表示列表遍歷的次數,主要是由於有時候訓練模型需要反覆的遍歷資料集便於更新模型引數,預設情況下是None(迴圈遍歷)。shuffle表示是否隨機遍歷,預設情況下是true,表示資料會隨機輸入佇列,當想順序讀入資料時shuffle設定為false。至於其他的capacity表示列表的容量,shared_name表示共享時的名字。
三、Reader和Decoder
Reader的功能是讀取資料記錄,Decoder的功能是將資料的記錄轉化為張量格式。在使用時需要先建立輸入資料檔案對應的Reader,然後從檔名佇列中取出檔名,在呼叫Reader.read的方法返回一個類似於(輸入檔名,資料記錄)的元組。最後使用Decoder方法將每一列資料都轉化為張量的形式。
四、批佇列
批佇列可以在構建圖之前事先構建好,樣例佇列需要在圖中直接產生不用直接預定義。所以先介紹批佇列的構建方式。批佇列主要是樣例打包聚整合批資料,能供模型訓練使用。一般是使用tf.train.shuffle_batch和tf.train.batch的方法構建。可以控制批的大小(一次性讀入的 資料大小),執行緒個數,然後在圖中直接呼叫。
五、樣例佇列
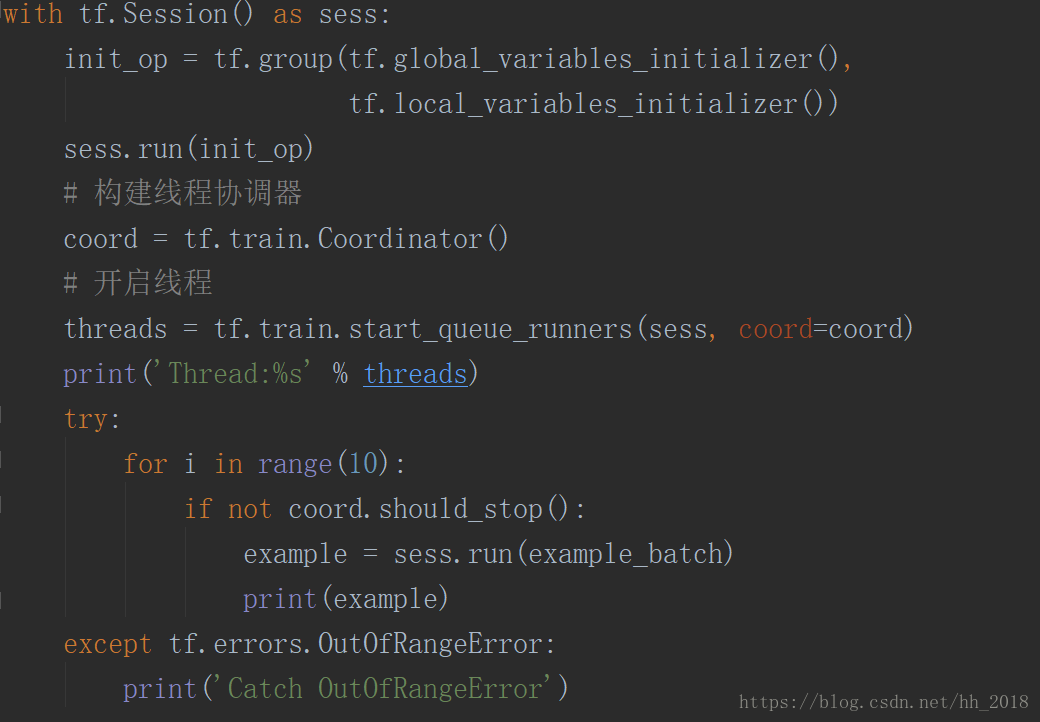
樣例佇列的建立方式是隱式的,一般在圖中為了計算任務順利的輸入資料,我們一般使用tf.train.start_queue_runners方法啟動所有的入隊操作所需的執行緒,此時會自動執行所有的檔名入隊操作和檔名佇列的操作,執行樣例佇列入隊和樣例佇列的操作。這些都是在後臺產生的。
六、執行緒協調器
並行讀取資料離不開多執行緒操作,多執行緒操作離不開執行緒調節器。tensorflow使用tf.train.Coordinatior方法建立管理多執行緒生命週期的調節器。調節器的工作原理比較簡單,它監控Tensoflow後臺的所有執行緒,當某一個執行緒出現異常時,它的should_stop方法返回true,最後呼叫request_stop終止所有的執行緒。但是要注意我們在使用執行緒調節器之前一定要呼叫tf.local_variables_initializer方法進行初始化。
七、讀入資料型別
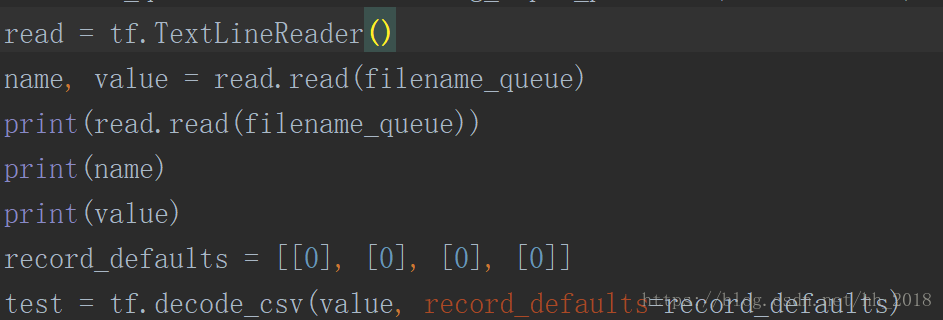
tensorflow讀入的資料型別可以使csv,TFRecord和自由格式檔案。CSV的讀取直接呼叫tf.TextLineReader構建Reader,再呼叫tf.decoder_csv的方法對檔案進行解碼變為張量。
TFRecoder是tensorflow標準的輸入格式,它是通過protocolBuffer構建的儲存資料記錄的結構。該資料結構分明,一個樣例中包含一組特徵Features,一個Features又包含多個特徵向量feature。其在讀取的時候主要使用tf.TFRecoderReader的方法構建Reader,在使用read的方法讀出元組。接著對元組中的value採用tf.parse_single_example()方法進行解析。再解析的時候需要傳入features引數,該引數要和構造該檔案時輸入的字典型變數保持一致(key,value)。key和輸入的key一致,value是一個表示該key對應的維度和型別的定西,用tf.FixedLenFeature函式構造,該函式傳入引數表示特徵形狀和特徵值的型別。具體如下:
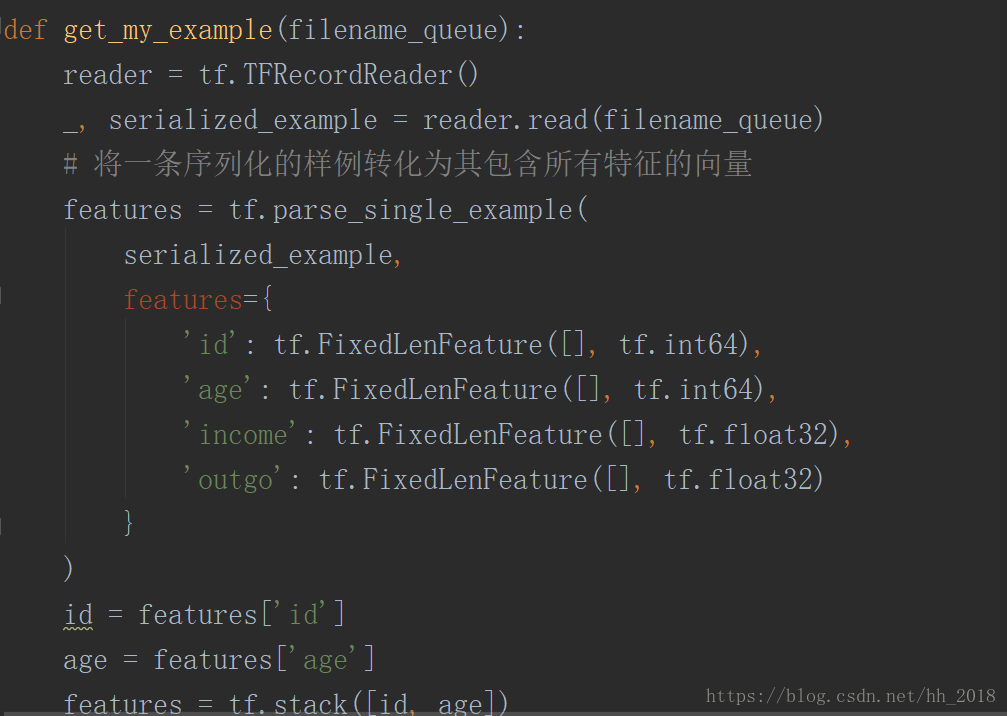
自由格式是指使用者自定義的二進位制檔案,他儲存的物件是字串,每條記錄都是一個固定長度的位元組塊。再讀入的時候首先要使用tf.FixedLengthRecoderReader的方法讀取對應的二進位制檔案,然後使用tf.decode_raw的方法將字串轉化為uint8型別的張量。
八、整體程式碼
具體的相關碼如下: