
MongoDB千萬級資料的分析
轉載自:http://my.oschina.net/tianyongke/blog/171172
所有試驗都是隻針對所有資料進行統計分析,不針對某條資料的分析。
一、匯入
清單1:
讀取CSV檔案,儲存到資料庫中
#-*- coding:UTF-8 -*- ''' Created on 2013-10-20 @author: tyk ''' from pymongo.connection import Connection from time import time import codecs import csv import os rootdir = "2000W/" # 指明被遍歷的資料夾 ''' ''' def process_data(): conn = Connection('localhost', 27017) #獲取一個連線 ##conn.drop_database('guestHouse') db = conn.TYK guest = db.guestHouse guest_info = [] for parent, dirnames, filenames in os.walk(rootdir): #三個引數:分別返回1.父目錄 2.所有資料夾名字(不含路徑) 3.所有檔名字 for filename in filenames: ErrorLine = [] key_length = 0 fullname = os.path.join(parent,filename) try: #with codecs.open(fullname, encoding='utf_8') as file: with codecs.open(fullname, encoding='utf_8_sig') as file:#忽略UTF-8檔案前面的BOM keys = file.readline().split(',')#先讀掉第一行的註釋 key_length = len(keys) spamreader = csv.reader(file)#以CSV格式讀取,返回的不再是str,而是list for line in spamreader: if key_length != len(line):#部分資料不完整,記錄下來 ErrorLine.append(line) else: each_info = {} for i in range(1, len(keys)):#過濾第一個欄位Name,姓名將不再存到資料庫中 each_info[keys[i]] = line[i] guest_info.append(each_info) if len(guest_info) == 10000:#每10000條進行一次儲存操作 guest.insert(guest_info) guest_info = [] except Exception, e: print filename + "\t" + str(e) #統一處理錯誤資訊 with open('ERR/' + os.path.splitext(filename)[0] + '-ERR.csv', 'w') as log_file: spamwriter = csv.writer(log_file) for line in ErrorLine: spamwriter.writerow(line) #最後一批 guest.insert(guest_info) if __name__ == '__main__': start = time() process_data() stop = time() print(str(stop-start) + "秒")
總結:
1.檔案編碼為UTF-8,不能直接open()開啟讀取。
2.檔案已CSV格式進行儲存,讀取時用CSV模組處理來讀取。這是讀出來的資料每行為一個list。注意,不能簡單的以","拆分後進行讀取。對於這種形狀"a,b,c", d的資料是無法正確解析的。
3.對於UTF-8檔案,如果有BOM的形式去讀是要以'utf_8_sig'編碼讀取,這樣會跳過開頭的BOM。如果不處理掉BOM,BOM會隨資料一同存到資料庫中,造成類似" XXX"的現象(有一個空格的假象)。
如果真的已經存到庫中了,那只有改key了
另外,網上還有一種方法(嘗試失敗了,具體原因應該是把字串轉換成位元組碼然後再去比較。怎麼轉這個我還不會...)db.guestHouse.update({}, {"$rename" : {" Name" : "Name"}}, false, true)
#with codecs.open(fullname, encoding='utf-8') as file:
with codecs.open(fullname, encoding='utf_8_sig') as file:
keys = file.readline().split(',')
if keys[0][:3] == codecs.BOM_UTF8:#將keys[0]轉化為位元組碼再去比較
keys[0] = keys[0][3:]擴充套件:
今天發現MongoDB本身就帶有匯入功能mongoimport,可以直接匯入CSV檔案...
小試一把
1.不做錯誤資料過濾,直接匯入。用專利引用資料做一下實驗(《Hadoop權威指南》一書中的實驗資料)
實驗資料:
"PATENT","GYEAR","GDATE","APPYEAR","COUNTRY","POSTATE","ASSIGNEE","ASSCODE","CLAIMS","NCLASS","CAT","SUBCAT","CMADE","CRECEIVE","RATIOCIT","GENERAL","ORIGINAL","FWDAPLAG","BCKGTLAG","SELFCTUB","SELFCTLB","SECDUPBD","SECDLWBD"
3070801,1963,1096,,"BE","",,1,,269,6,69,,1,,0,,,,,,,
3070802,1963,1096,,"US","TX",,1,,2,6,63,,0,,,,,,,,,
3070803,1963,1096,,"US",
"IL",,1,,2,6,63,,9,,0.3704,,,,,,,
3070804,1963,1096,,"US","OH",,1,,2,6,63,,3,,0.6667,,,,,,,
3070805,1963,1096,,"US","CA",,1,,2,6,63,,1,,0,,,,,,,
3070806,1963,1096,,"US","PA",,1,,2,6,63,,0,,,,,,,,,
3070807,1963,1096,,"US","OH",,1,,623,3,39,,3,,0.4444,,,,,,,
3070808,1963,1096,,"US","IA",,1,,623,3,39,,4,,0.375,,,,,,,
3070809,1963,1096,,,,1,,4,6,65,,0,,,,,,,,,結果:
> db.guest.find({}, {"PATENT" : 1, "_id" : 1})
{ "_id" : ObjectId("52692c2a0b082a1bbb727d86"), "PATENT" : 3070801 }
{ "_id" : ObjectId("52692c2a0b082a1bbb727d87"), "PATENT" : 3070802 }
{ "_id" : ObjectId("52692c2a0b082a1bbb727d88"), "PATENT" : 3070803 }
{ "_id" : ObjectId("52692c2a0b082a1bbb727d89"), "PATENT" : "IL" }
{ "_id" : ObjectId("52692c2a0b082a1bbb727d8a"), "PATENT" : 3070804 }
{ "_id" : ObjectId("52692c2a0b082a1bbb727d8b"), "PATENT" : 3070805 }
{ "_id" : ObjectId("52692c2a0b082a1bbb727d8c"), "PATENT" : 3070806 }
{ "_id" : ObjectId("52692c2a0b082a1bbb727d8d"), "PATENT" : 3070807 }
{ "_id" : ObjectId("52692c2a0b082a1bbb727d8e"), "PATENT" : 3070808 }
{ "_id" : ObjectId("52692c2a0b082a1bbb727d8f"), "PATENT" : 3070809 }
> db.guest.count()
10
>2.以UTF-8有BOM格式再試一次。實驗資料同上
> db.guest.find({}, {"PATENT" : 1, "_id" : 1})
{ "_id" : ObjectId("52692d730b082a1bbb727d90"), "PATENT" : 3070801 }
{ "_id" : ObjectId("52692d730b082a1bbb727d91"), "PATENT" : 3070802 }
{ "_id" : ObjectId("52692d730b082a1bbb727d92"), "PATENT" : 3070803 }
{ "_id" : ObjectId("52692d730b082a1bbb727d93"), "PATENT" : "IL" }
{ "_id" : ObjectId("52692d730b082a1bbb727d94"), "PATENT" : 3070804 }
{ "_id" : ObjectId("52692d730b082a1bbb727d95"), "PATENT" : 3070805 }
{ "_id" : ObjectId("52692d730b082a1bbb727d96"), "PATENT" : 3070806 }
{ "_id" : ObjectId("52692d730b082a1bbb727d97"), "PATENT" : 3070807 }
{ "_id" : ObjectId("52692d730b082a1bbb727d98"), "PATENT" : 3070808 }
{ "_id" : ObjectId("52692d730b082a1bbb727d99"), "PATENT" : 3070809 }
> db.guest.count()
103.mongoimport命令解釋
mongoimport -d TYK -c guest --type csv --file d:\text.csv --headerline
-d 資料庫
-c 集合
--type 資料格式
--file 檔案路徑
--headerline 貌似指定這個後以第一行為key,另 -f 可以指定key “-f Name, age”二、統計分析
1.根據性別統計
由於資料不規範,先查詢一下有多少種方式來表示性別的
db.runCommand({"distinct" : "guestHouse", "key" : "Gender"}){
"values" : [
"M",
"F",
"0",
" ",
"1",
"",
"19790522",
"#0449",
"#M",
"",
"N"
],
"stats" : {
"n" : 20048891,
"nscanned" : 20048891,
"nscannedObjects" : 20048891,
"timems" : 377764,
"cursor" : "BasicCursor"
},
"ok" : 1
}
#總資料
db.guestHouse.count()
20048891
#男 M
db.guestHouse.count({"Gender":"M"})
12773070
64%#女 F
db.guestHouse.count({"Gender":"F"})
6478745
32%
總結:
1.帶條件count時速度是非常慢的,猜測在count時可能先進行的查詢操作,如果是查詢加索引效果會好很多。對Gender加索引,效果明顯提高了,但仍然是N秒級別的。顯然在實時情況下還是不行的。另外隨意加索引也會遇其它方面的問題。在用索引時能達到一個平衡點很重要的啊。
2013-10-24
檢視count的js解釋
> db.guestHouse.count
function ( x ){
return this.find( x ).count();
}
>
果然是先find,後count2、根據身份證分析性別
從上面資料看,大約有4%的資料性別不詳。
15位身份證號碼:第7、8位為出生年份(兩位數),第9、10位為出生月份,第11、12位代表出生日期,第15位代表性別,奇數為男,偶數為女。 18位身份證號碼:第7、8、9、10位為出生年份(四位數),第11、第12位為出生月份,第13、14位代表出生日期,第17位代表性別,奇數為男,偶數為女。要根據身份證來分析的話,明顯不好直接處理分析了。那麼就嘗試一下編寫MapReduce算一下吧,但是單機MapReduce速度會更慢。
先了解一下資料,看看有多少證件型別
> db.runCommand({"distinct" : "guestHouse", "key" : "CtfTp"})
{
"values" : [
"OTH",
"GID",
"ID",
"TBZ",
"VSA",
"TXZ",
"JID",
"JZ",
"HXZ",
"JLZ",
"#ID",
"hvz",
"待定",
"11",
"",
"SBZ",
"JGZ",
"HKB",
"TSZ",
"JZ1",
" ",
"Id",
"#GID",
"1"
],
"stats" : {
"n" : 20048891,
"nscanned" : 20048891,
"nscannedObjects" : 20048891,
"timems" : 610036,
"cursor" : "BasicCursor"
},
"ok" : 1
}
>
>map = function() {
if (this.CtfTp == "ID") {
if (this.CtfId.length == 18){
emit(parseInt(this.CtfId.charAt(16)) % 2, {count : 1}) //1為男,0為女
}else if (this.CtfId.length == 15) {
emit(parseInt(this.CtfId.charAt(14)) % 2, {count : 1}) //無法解析時為NaN
}
} else {
emit(-1, {count : 1})
}
}
>reduce = function(key, emits) {
total = 0;
for (var i in emits) {
total += emits[i].count;
}
return {"count" : total};
}
>mr = db.runCommand(
{
mapReduce: "guestHouse",
map: map,
reduce: reduce,
out: "TYK.guestHouse.output",
verbose: true
}
)
>{
"result" : "guestHouse.output",
"timeMillis" : 999097,
"timing" : {
"mapTime" : 777955,
"emitLoop" : 995248,
"reduceTime" : 111217,
"mode" : "mixed",
"total" : 999097
},
"counts" : {
"input" : 20048891,
"emit" : 19928098,
"reduce" : 594610,
"output" : 4
},
"ok" : 1
}
> db.guestHouse.output.find()
{ "_id" : NaN, "value" : { "count" : 1360 } }
{ "_id" : -1, "value" : { "count" : 1161164 } }
{ "_id" : 0, "value" : { "count" : 6831007 } }
{ "_id" : 1, "value" : { "count" : 11934567 } }
>1.速度比直接count({"Gender" : "M"}),並且資源佔用不明顯。IO壓力不大,CPU壓力不大。
2.結果中資料加起來為“19928098”條,比總條數“20048891”少了“120793”條,少在哪了?
3、統計各省、地區的情況
清單1:
map = function() {
//var idCard_reg = /(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)/;
//var idCard_reg = /(^[1-6]\d{14}$)|(^[1-6]\d{17}$)|(^[1-6]\d{16}(\d|X|x)$)/;
//((1[1-5])|(2[1-3])|(3[1-7])|(4[1-6])|(5[1-4])|(6[1-5]))
var idCard_reg = /(^((1[1-5])|(2[1-3])|(3[1-7])|(4[1-6])|(5[1-4])|(6[1-5]))\d{13}$)|(^((1[1-5])|(2[1-3])|(3[1-7])|(4[1-6])|(5[1-4])|(6[1-5]))\d{16}$)|(^((1[1-5])|(2[1-3])|(3[1-7])|(4[1-6])|(5[1-4])|(6[1-5]))\d{15}(\d|X|x)$)/;
if (this.CtfTp == "ID" && idCard_reg.test(this.CtfId)) {
emit(this.CtfId.substr(0, 2), {count : 1}) //擷取前兩位 地區,省、直轄市、自治區
} else {
emit(-1, {count : 1})
}
}
reduce = function(key, emits) {
total = 0;
for (var i in emits) {
total += emits[i].count;
}
return {"count" : total};
}
mr = db.runCommand(
{
mapReduce: "guestHouse",
map: map,
reduce: reduce,
out: "guestHouse.provinceOutput",
verbose: true
}
)
{
"result" : "guestHouse.provinceOutput",
"timeMillis" : 1173216,
"timing" : {
"mapTime" : 900703,
"emitLoop" : 1169954,
"reduceTime" : 157916,
"mode" : "mixed",
"total" : 1173216
},
"counts" : {
"input" : 20048891,
"emit" : 20048891,
"reduce" : 1613854,
"output" : 31
},
"ok" : 1
}
結果資訊:
> db.guestHouse.provinceOutput.find().sort({"value.count" : -1})
{ "_id" : "32", "value" : { "count" : 2398111 } } //江蘇
{ "_id" : -1, "value" : { "count" : 1670289 } } //不詳
{ "_id" : "37", "value" : { "count" : 1523357 } } //山東
{ "_id" : "33", "value" : { "count" : 1341274 } } //浙江
{ "_id" : "41", "value" : { "count" : 1120455 } } //河南
{ "_id" : "34", "value" : { "count" : 981943 } } //安徽
{ "_id" : "42", "value" : { "count" : 974855 } } //湖北
{ "_id" : "31", "value" : { "count" : 921046 } } //上海
{ "_id" : "13", "value" : { "count" : 791432 } } //河北
{ "_id" : "21", "value" : { "count" : 754645 } } //遼寧
{ "_id" : "14", "value" : { "count" : 689738 } } //山西
{ "_id" : "51", "value" : { "count" : 664918 } } //四川(包含重慶)
{ "_id" : "36", "value" : { "count" : 594849 } } //江西
{ "_id" : "23", "value" : { "count" : 581882 } } //黑龍江
{ "_id" : "61", "value" : { "count" : 571792 } } //陝西
{ "_id" : "35", "value" : { "count" : 571107 } } //福建
{ "_id" : "43", "value" : { "count" : 562536 } } //湖南
{ "_id" : "44", "value" : { "count" : 558249 } } //廣東
{ "_id" : "11", "value" : { "count" : 495897 } } //北京
{ "_id" : "22", "value" : { "count" : 456159 } } //吉林
{ "_id" : "15", "value" : { "count" : 392787 } } //內蒙
{ "_id" : "12", "value" : { "count" : 320711 } } //天津
{ "_id" : "62", "value" : { "count" : 227366 } } //甘肅
{ "_id" : "45", "value" : { "count" : 192810 } } //廣西
{ "_id" : "52", "value" : { "count" : 187622 } } //貴州
{ "_id" : "65", "value" : { "count" : 145040 } } //新疆
{ "_id" : "53", "value" : { "count" : 141652 } } //雲南
{ "_id" : "63", "value" : { "count" : 75509 } } //青海
{ "_id" : "64", "value" : { "count" : 75105 } } //寧夏
{ "_id" : "46", "value" : { "count" : 48279 } } //海南
{ "_id" : "54", "value" : { "count" : 17476 } } //西藏
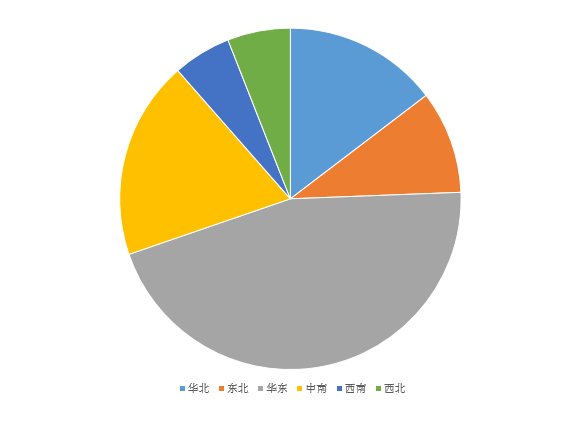
對結果在此進行分析,根據地區處理。
db.guestHouse.provinceOutput.group({
keyf:function(doc){return {"key" : doc._id.substr(0,1)}},//<span>以省標識的第一位再次分組統計 </span> initial : {total : 0},
reduce :function(curr, result){
result.total += curr.value.count;
},
cond : {"_id" : {"$ne" : -1}},
finalize: function(result) {
var areas= [ "華北", "東北", "華東",
"中南", "西南",
"西北" ];
result.area = areas[result.key - 1];
}
})
[
{
"key" : "1",
"total" : 2690565,
"area" : "華北"
},
{
"key" : "2",
"total" : 1792686,
"area" : "東北"
},
{
"key" : "3",
"total" : 8331687,
"area" : "華東"
},
{
"key" : "4",
"total" : 3457184,
"area" : "中南"
},
{
"key" : "5",
"total" : 1011668,
"area" : "西南"
},
{
"key" : "6",
"total" : 1094812,
"area" : "西北"
}
]group 函式參考:
疑問與總結:
a.前面說的MapReduce沒有count佔用資源是錯誤的,今天發現工作管理員不會實時更新了⊙﹏⊙b汗
b.group的'keyf'這個配置有時間很有用處(key、 keyf只能二選一)
c.在map時加上query : {"CtfTp" : "ID"}一定會提高速度嗎?
2013-10-29 22:57:00詳見測試:http://my.oschina.net/tianyongke/blog/172794
d.部分日誌
22:10:47.001 [conn62] M/R: (1/3) Emit Progress: 19874400/20048891 99%
22:10:50.000 [conn62] M/R: (1/3) Emit Progress: 19923500/20048891 99%
22:10:53.005 [conn62] M/R: (1/3) Emit Progress: 19974700/20048891 99%
22:10:56.603 [conn62] M/R: (1/3) Emit Progress: 20016000/20048891 99%
22:10:59.001 [conn62] M/R: (1/3) Emit Progress: 20047200/20048891 99%
22:11:02.052 [conn62] M/R: (3/3) Final Reduce Progress: 84500/112318 75%
22:11:02.393 [conn62] CMD: drop TYK.guestHouse.provinceOutput
22:11:02.531 [conn62] command admin.$cmd command: { renameCollection: "TYK.tmp.mr.guestHouse_9", to: "TYK.guestHouse.provinceOutput", stayTemp: false } ntoreturn:1 keyUpdates:0 reslen:37 136ms
22:11:02.561 [conn62] CMD: drop TYK.tmp.mr.guestHouse_9
22:11:02.587 [conn62] CMD: drop TYK.tmp.mr.guestHouse_9
22:11:02.587 [conn62] CMD: drop TYK.tmp.mr.guestHouse_9_inc
22:11:02.674 [conn62] CMD: drop TYK.tmp.mr.guestHouse_9
22:11:02.690 [conn62] CMD: drop TYK.tmp.mr.guestHouse_9_inc
22:11:02.894 [conn62] command TYK.$cmd command: { mapReduce: "guestHouse", map: function () {
//var idCard_reg = /(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|..., reduce: function (key, emits) {
total = 0;
for (var i in emits) {
total += emi..., out: "guestHouse.provinceOutput", verbose: true } ntoreturn:1 keyUpdates:0 numYields: 471197 locks(micros) W:233131 r:1922774271 w:20768395 reslen:232 1173522ms
22:56:54.820 [conn62] command TYK.$cmd command: { group: { ns: "TYK.guestHouse.provinceOutput", $keyf: function (doc){return {temp_key : doc._id.subStr(0,1)}}, initial: { total: 0.0 }, $reduce: function (doc, prev){
prev.total += doc.value.count;
} } } ntoreturn:1 keyUpdates:0 locks(micros) r:542599 reslen:75 542ms1)map
2)reduce
3)drop 指定定集合(以前反覆執行時先手動做了這一步,現在看來不用了)
4)變更臨時集合為指定集合
5)刪除臨時集合(反覆刪除,還有一個'_inc'的集合。不知道為什麼)
6)最後處理,執行finalize指定函式
表象的是先map後reduce,實際情況是怎麼樣的呢?是不是並行?並且reduce執行有1613854次之多,而以日誌顯示時間推算也就1秒左右。這個1613854是怎麼來的,與什麼有關?