
知識圖譜和Neo4j圖資料庫
一、知識圖譜

網際網路、大資料的背景下,谷歌、百度、搜狗等搜尋引擎紛紛基於該背景,建立自己的知識圖譜Knowledge Graph(谷歌)、知心(百度)和知立方(搜狗),主要用於改進搜尋質量。
1、什麼是知識圖譜
一種基於圖的資料結構,由節點(Point)和邊(Edge)組成。其中節點即實體,由一個全域性唯一的ID標示,關係(也稱屬性))用於連線兩個節點。通俗地講,知識圖譜就是把所有不同種類的資訊(Heterogeneous Information)連線在一起而得到的一個關係網路。知識圖譜提供了從“關係”的角度去分析問題的能力。
2、知識卡片
知識卡片旨在為使用者提供更多與搜尋內容相關的資訊,例如,當在搜尋引擎中輸入“姚明”作為關鍵詞時,我們發現搜尋結果頁面的右側原先用於置放廣告的地方被知識卡片所取代。下側即使與關鍵詞匹配的文件列表。
3、知識圖譜的作用
知識圖譜最早由谷歌提出,主要用於優化現有的搜尋引擎,例如搜尋姚明,除了姚明本身的資訊,還可關聯出姚明的女兒、姚明的妻子等與搜尋關鍵字相關的資訊。也就是說搜尋引擎的知識圖譜越龐大,與某關鍵字相關的資訊越多,再通過分析搜尋者的特指,計算出最可能想要看到的資訊,通過知識圖譜可大大提高搜尋的質量和廣度。
所以這也可理解為何谷歌百度等搜尋引擎大頭都為之傾心,建立自己符合自己使用者搜尋習慣的知識圖譜。據不完全統計,Google知識圖譜到目前為止包含了5億個實體和35億條事實(形如實體-屬性-值,和實體-關係-實體)
4、知識圖譜上的挖掘
通過大資料抽取和整合已經可以建立知識圖譜,為進一步增加知識圖譜的知識覆蓋率,還需要進一步對知識圖譜進行挖掘。常見的挖掘技術:
推理:通過規則引擎,針對實體屬性或關係進行挖掘,用於發現未知的隱含關係
實體重要性排序:當查詢多個關鍵字時,搜尋引擎將選擇與查詢更相關的實體來展示。常見的pageRank演算法計算知識圖譜中實體的重要性。
二、Neo4j圖資料庫
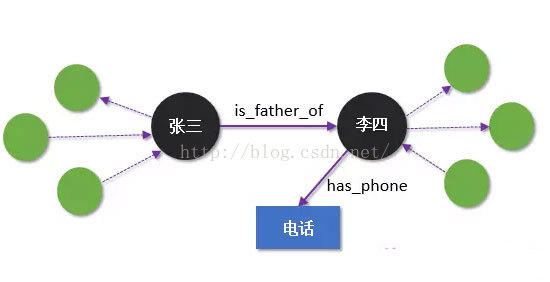
以上就是一個neo4j圖資料庫,由頂點-邊組成,常用於微博好友關係分析、城市規劃、社交、推薦等應用。
1、特性
支援ACID事務
企業版neo4j支援叢集搭建,保證HA
輕易擴充套件上億節點和關係
擁有自己的高階查詢語言cypher高效檢索
CSV資料匯入,java語言編寫均可
2、Cypher語言:
Match where return Create delete set foreach with 關鍵字同等與sql語句的select 等關鍵字操作,例如
Sql Statement
SELECT name FROM Person
LEFT JOIN Person_Department
ON Person.Id = Person_Department.PersonId
LEFT JOIN Department
ON Department.Id = Person_Department.DepartmentId
WHERE Department.name = "ITDepartment"MATCH(p:Person)<-[:EMPLOYEE]-(d:Department)WHEREd.name = "IT Department"RETURNp.nameJava Program Conn
Connectioncon = DriverManager.getConnection("jdbc:neo4j://localhost:7474/");
Stringquery ="MATCH (:Person {name:{1}})-[:EMPLOYEE]-(d:Department) RETURN d.name as dept";
try (PreparedStatementstmt = con.prepareStatement(QUERY)) {
stmt.setString(1,"John");
ResultSetrs = stmt.executeQuery();
while(rs.next()) {
Stringdepartment = rs.getString("dept");
....
}反欺詐:通過查詢不同賬戶,如銀行、信用卡等,找到該賬戶其他正常是否正常、相關使用者的交易資訊是否正常判斷使用者的信用度。
推薦:通過圖資料庫,查詢某節點的消費情況、好友資訊可為其推薦關聯度高的好友或可能消費的商品。
因為neo4j的儲存原理使得它的查詢速度是在O(l)級別的複雜度,查詢高效。