
MySQL語句執行優化及分頁查詢優化,分庫分表(一)
下面是關於在使用SQL時,我們儘量應該遵守的規則,這樣可以避免寫出執行效率低的SQL
1、當只需要一條資料時,使用limit 1
在我們執行查詢時,如果添加了 Limit 1,那麼在查詢的時候,在篩選到一條資料時就會停止繼續查詢,但是如果沒有新增limit 1即使只有一條資料,也會嘗試去查詢下一條滿足條件的資料。
2、對於搜尋的欄位建立索引
如果當前資料量很大的情況下,需要根據一定的條件進行篩選,對篩選列新增索引,但是一個表當中的索引不建議過多,對於索引的建立規則以及哪些情況下索引失效,可以參照 MySQL索引相關內容彙總
3、是進行join時,儘量使用索引列進行join
如果兩張表或者多張表進行關聯,確保進行join關聯的列型別相同,並且分別是索引列。
4、儘量為每張表都新增一個ID
資料庫當中儘量設定主鍵或者說是一個ID,主鍵的話,其型別最好是int型別。
5、對於區分度比較低的列,可以使用Enum來代替Varchar
如果這個列只有幾種情況的,比如性別,比如文章型別等,這些區分度很低,我們儘量使用列舉型別來代替Varchar, 列舉型別儲存的是tinyint,但是對外顯示的字串。
6、垂直分割
對於一些儲存比較大的列,並且不需要直接訪問的,可以進行垂直分割,比如對於文章或者新聞的資訊儲存,我們只需要把文章的基本資訊,比如標題,作者,建立日期,型別等基礎資訊存放在一張表中,文章內容存放在另外一張表中,這樣查詢時,在用到的時候再查詢。
7、對於limit分頁的優化
比如我們直接寫分頁查詢select * from tbl limit 100000,10 這個查詢時間很長,如果我們設定id為主鍵,然後在查詢時只查詢主鍵 select id from tbl limit 100000 , 10 ,這條語句就比上條節省了大量的時間,但是我們需要的是整張表的資料,
接著優化改為:select * from tbl where id >= (select id from tbl limit 100000,1) limit 20
這個時候如果我們需要新增一個篩選條件,比如type=1, 在原有的基礎上面,
select id, title from tbl where type = 1 order by id limit 1000000,10 對這條語句,發現在資料量上百萬的時候,執行速度很慢,原因在於where條件當中使用了非索引的列,導致進行了全表掃描
這個時候我們可以考慮建立組合索引(type,id)將where條件中的列放在第一位,limit當中的主鍵放在第二位,進行查詢,同時只查詢id,速度會非常快。
分庫分表
分庫其實就是將原來一個數據庫當中的資料,分到多個數據庫當中,分表就是將原來一個表當中的資料拆分成兩個表儲存。
垂直切分
將資料庫當中的不同模組的資料表放在不同的資料庫上,比如人員管理模組(member , role, user等),商品管理模組(product, number, baseInfo等),將不同模組的表放在不同的資料庫上面,這樣其中一個模組式資料庫出問題了,也不會影響其他模組的使用。
水平切分
比如當我們使用者註冊數量已經達到千萬時,這個時候,就需要把User表進行一個水平切分,分別建立user1和user2,這兩張表的結構完全相同,同時建立一個儲存引擎為Merge的allUser表,使用者在查詢時,通過allUser表來查詢,具體的資料分別儲存在user1和user2表當中。
MySQL水平分片
將不同每個模組的資料分配在不同的資料庫上面,同時每個模組的資料進行水平切分,也儲存在不同的資料庫上
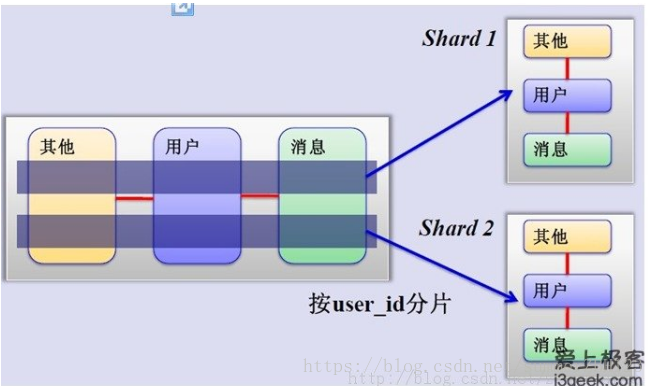
這樣做的好處就是當在有新的資料進來時,只需要配置一臺伺服器即可。