
微服務架構下的資料一致性:可靠事件模式
在《微服務架構下的資料一致性:概念及相關模式》中介紹了在微服務中實現資料一致性的三種方式,包括可靠事件模式、業務補償模式、TCC模式。本文重點說一下可靠事件投遞。
1. 可靠事件模式
可靠事件模式屬於事件驅動架構,微服務完成操作後向訊息代理髮布事件,關聯的微服務從訊息代理訂閱到該事件從而完成相應的業務操作,關鍵在於可靠事件投遞和避免事件重複消費。
可靠事件投遞有兩個特性:1)每個服務原子性的完成業務操作和釋出事件;2)訊息代理確保事件投遞至少一次(at least once)。
避免重複消費要求消費事件的服務實現冪等性。
現下流行的訊息佇列都已經實現了事件的持久化和at least once的投遞模式,所以可靠事件投遞的第二條特性已經滿足,這裡就不展開。需要著重說的就是可靠時間投遞的第一條特性和避免事件重複消費,即服務的原子性和消費者的冪等性。
2. 可靠事件投遞
2.1 潛在風險
先來看一段簡單的程式碼:
public void trans() {
try {
// 1. 操作資料庫
bool result = dao.update(mode1);// 操作資料庫失敗,會丟擲異常
// 2. 如果第一步成功,則操作訊息佇列(投遞訊息)
if(result){
mq.append(mode1);// 如果mq.append方法執行失敗,會丟擲異常
}
} catch (Exception e) {
roolback();// 如果發生異常,就回滾
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

根據上面程式碼和時序圖,理想化的情況會出現3中情況:
- 操作資料庫成功,向訊息代理投遞事件也成功
- 操作資料庫失敗,不會向訊息代理中投遞事件了
- 操作資料庫成功,但是向訊息代理中投遞事件時失敗,向外丟擲了異常,剛剛執行的更新資料庫的操作將被回滾
之所以說是理想化,是因為上面的思路還是傳統的本地事務,但是在微服務架構中,可能出錯的情況更為複雜,其中最容易出現的錯誤就是網路IO和伺服器宕機:
- 微服務A投遞事件時,訊息代理已經接收到訊息,並進行持久化成功,即訊息傳送至訊息代理,需要向微服務A返回響應的時候,網路發生異常,即4出現錯誤,程式碼中的
mq.append()方法丟擲異常,最終結果是事件投遞成功,但是資料庫被回滾。

- 微服務A在投遞成功後,向資料庫提交commit請求之前發生宕機,資料庫因為連線異常關閉而回滾。最終結果還是事件被投遞,資料庫卻被回滾。
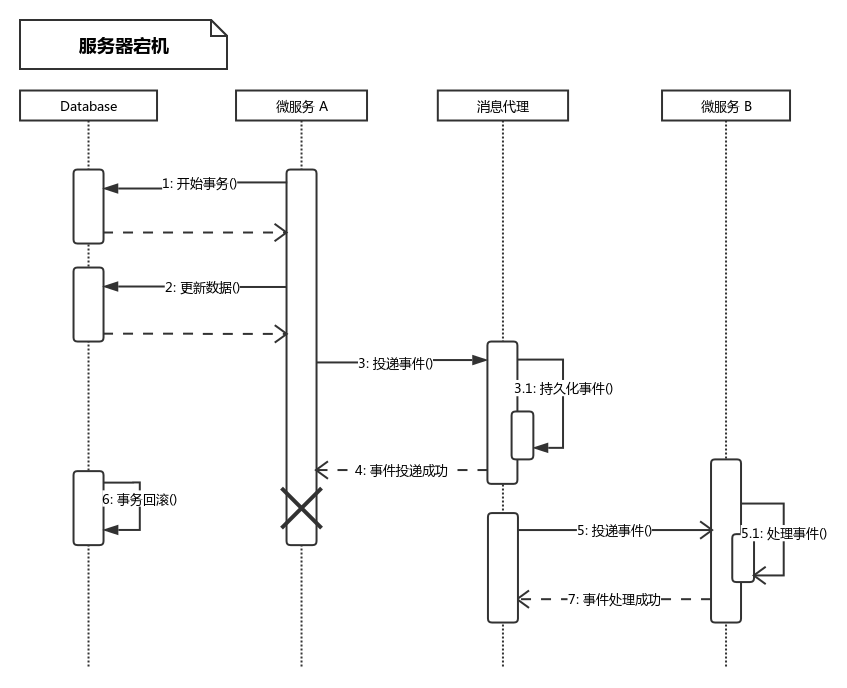
在單伺服器情況下,上面提到的兩種異常發生概覽不大,但是在當前多伺服器、網路情況複雜的環境中,發生的概率被大大放大,由於是非同步處理,一旦問題發生,拍錯將變得更加困難。
2.2. 可靠事件投遞的兩種實現
2.2.1 本地事件表
本地事件表方法將事件和業務資料儲存在同一個資料庫中,使用一個額外的“事件恢復”服務來恢復事件,由本地事務保證更新業務和釋出事件的原子性。考慮到事件恢復可能會有一定的延時,服務在完成本地事務後可立即向訊息代理髮佈一個事件。

- 微服務在同一個本地事務中記錄業務資料和事件資料
- 微服務實時釋出一個事件關聯業務服務中,如果事件釋出成功立即刪除記錄的事件,這樣能夠保證事件投遞的實時性。
- 事件恢復服務定時從事件表中恢復未釋出成功的事件,重新發布,重新發布成功後刪除記錄的事件,這樣能夠保證事件一定能夠被投遞。
這樣能夠很好的解決上面提到的網路IO異常和伺服器宕機的問題,但是業務系統和事件耦合在一起,額外的事件資料操作給資料庫帶來壓力,也成為非同步事件機制的一個瓶頸。
2.2.2 外部事件表
針對本地事件表出現的問題,提出外部事件表方法,將事件持久化到外部的事件系統,事件系統需提供實時事件服務以接收微服務釋出的事件,同時事件系統還需要提供事件恢復服務來確認和恢復事件。

- 業務服務在事務提交前,通過實時事件服務向事件系統請求傳送事件,事件系統只記錄事件並不真正傳送
- 業務服務在提交後,通過實時事件服務向事件系統確認傳送,事件得到確認後事件系統才真正釋出事件到訊息代理
- 業務服務在業務回滾時,通過實時事件向事件系統取消事件
- 事件系統的事件恢復服務會定期找到未確認傳送的事件向業務服務查詢狀態,根據業務服務返回的狀態決定事件是要釋出還是取消
該方式將業務系統和事件系統獨立解耦,都可以獨立伸縮。但是這種方式需要一次額外的傳送操作,並且需要釋出者提供額外的查詢介面,這樣就增加了系統實現的複雜性。
3. 冪等性
3.1 事件本身具備冪等性
本身具備冪等性的事件,需要考慮執行順序。如果事件本身描述的是某個時間點的狀態,而不是變化,那麼就說這個事件具備冪等性。比如,某個時間點賬戶餘額為100,這個事件就具備冪等性;某個時間點賬戶餘額增加10,這個事件就不具備冪等性。
那麼,這種具備冪等性的事件需要考慮執行順序,比如,事件1是2016-07-16 15:07:31賬戶餘額是100,事件2是2016-07-16 25:07:31賬戶餘額是120。
- 如果事件1執行完成後執行事件2,將獲得我們期望的結果。
- 如果事件2先執行,然後又執行了事件1,那結果就不是我們期望的了。
- 如果事件1執行完成後執行事件2,此時結果是我們需要的,但由於事件重複傳送,又執行了一遍事件1,此時結果也不是我們期望的了。
簡單的說,我們需要保證事件2一旦處理,事件1就不能再處理。
為了保證事件的順序,最簡單的做法就是在事件中新增時間戳。微服務記錄每個事件最後處理的時間戳,如果收到的事件的時間戳早於我們記錄的,丟棄該事件。當然,在高併發的情況下,同一時間內可能出現多個事件;事件由不同伺服器發出,時間可能不同步。這兩種情況下,可以選擇使用全域性遞增序列號替換時間戳。
3.2 事件本身不具備冪等性
對於本身不具有冪等性的事件,主要思想是儲存每條事件執行結果。當收到一個事件時,我們需要根據事件的標識ID查詢該事件是否已經執行過,如果執行過直接返回上一次的執行結果,否則排程執行事件。
這裡唯一需要考慮的就是資源開銷:重複執行一次的開銷,查詢執行結果的開銷。
- 如果重複執行一次的開銷非常小,或者只有很少的事件會被重複接收,可以選擇重複執行一次事件,在將事件持久化到的過程中,由於唯一鍵(標識ID)重複,持久化過程失敗。
- 如果重複執行開銷較大,則直接使用一個過濾服務,過濾重複事件。即使用標識ID過濾事件是否重複。如果是,直接返回上一次執行結果。
對於重複執行開銷比較大的情況,可能服務執行時間較長。就會出現這麼一種情況:接收到一個新的事件,服務開始執行,執行過程中,又接收到重複事件,這個時候上個事件還沒有執行完成,即過濾服務還沒有收到上次執行的結果,但是重複執行開銷又大。解決辦法就是對處理過程分段:接收、開始處理、處理完畢等,可以根據不同業務進行不同的分段。這樣過濾服務就能夠及時發現重複事件,並能夠根據事件處理狀態做出不同處理。
另一個需要注意的地方就是,微服務實現資料一致性最好的方式是最終一致性。有些需要考慮的極端情況下,是需要人工接入的,這裡就不展開了。