
GeoHash原理和視覺化顯示
最近在做附近定位功能的產品,geohash是一個非常不錯的實現方式。查詢資料,發現阿里的這篇文章講解的很好。但文中並沒有給出geohash顯示的工具。無奈,也沒有查到類似的。只好自己簡單顯示一下,方便自己理解。
專案地址: https://github.com/Ryan-Miao/geohash-visualization
geohash視覺化顯示
經緯度獲取9宮格覆蓋: https://ryan-miao.github.io/geohash-visualization/index.html

geohash座標定位:
演示了中心點以及周圍其他下一級的點的關係

收藏原文如下:
基於快速GeoHash,如何實現海量商品與商圈的高效匹配
阿里妹導讀:閒魚是一款閒置物品的交易平臺APP。通過這個平臺,全國各地“無處安放”的物品能夠輕鬆實現流動。這種分享經濟業務形態被越來越多的人所接受,也進一步實現了低碳生活的目標。
今天,閒魚團隊就商品與商圈的匹配演算法為我們展開詳細解讀。
摘要
閒魚app根據交通條件、商場分佈情況、住宅區分佈情況綜合考慮,將城市劃分為一個個商圈。杭州部分割槽域商圈劃分如下圖所示。
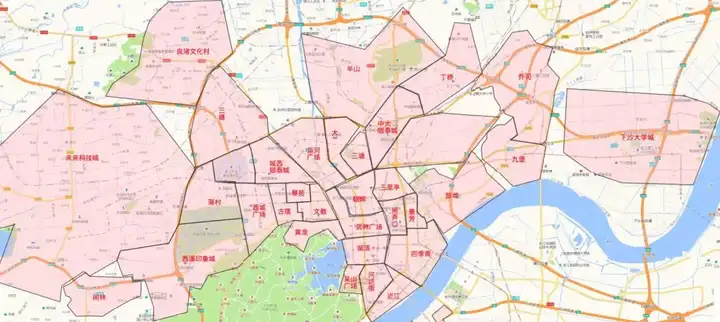
閒魚的商品是由使用者釋出的GPS隨機分佈在地圖上的點資料。當用戶處於某個商圈範圍內時,app會向用戶推薦GPS位於此商圈中的商品。要實現精準推薦服務,就需要計算出哪些商品是歸屬於你所處的商圈。
在資料庫中,商圈是由多個點圍成的面數據,這些面數據形狀、大小各異,且互不重疊。商品是以GPS標記的點資料,如何能夠快速高效地確定海量商品與商圈的歸屬關係呢?傳統而直接的方法是,利用幾何學的空間關係計算公式對海量資料實施直接的“點—面”關係計算,來確定每一個商品是否位於每一個商圈內部。
閒魚目前有10億商品資料,且每天還在快速增加。全國所有城市的商圈數量總和大約為1萬,每個商圈的大小不一,邊數從10到80不等。如果直接使用幾何學點面關係運算,需要的計算量級約為2億億次基本運算。按照這個思路,我們嘗試過使用阿里巴巴集團內部的離線計算叢集來執行計算,結果叢集在運行了超過2天之後也未能給出結果。
經過演算法改進,我們採用了一種基於GeoHash精確匹配,結合GeoHash非精確匹配並配合小範圍幾何學關係運算精匹配的演算法,大大降低了計算量,高效地實現了離線環境下海量點-面數據的包含關係計算。同樣是對10億條商品和1萬條商圈資料做匹配,可以在1天內得到結果。
點資料GeoHash原理與演算法
GeoHash是一種對地理座標進行編碼的方法,它將二維座標對映為一個字串。每個字串代表一個特定的矩形,在該矩形範圍內的所有座標都共用這個字串。字串越長精度越高,對應的矩形範圍越小。
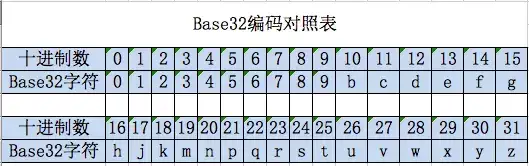
對一個地理座標編碼時,按照初始區間範圍緯度[-90,90]和經度[-180,180],計算目標經度和緯度分別落在左區間還是右區間。落在左區間則取0,右區間則取1。然後,對上一步得到的區間繼續按照此方法對半查詢,得到下一位二進位制編碼。當編碼長度達到業務的進度需求後,根據“偶數位放經度,奇數位放緯度”的規則,將得到的二進位制編碼穿插組合,得到一個新的二進位制串。最後,根據base32的對照表,將二進位制串翻譯成字串,即得到地理座標對應的目標GeoHash字串。
以座標“30.280245, 120.027162”為例,計算其GeoHash字串。首先對緯度做二進位制編碼:
- 將[-90,90]平分為2部分,“30.280245”落在右區間(0,90],則第一位取1。
- 將(0,90]平分為2分,“30.280245”落在左區間(0,45],則第二位取0。
- 不斷重複以上步驟,得到的目標區間會越來越小,區間的兩個端點也越來越逼近“30.280245”。
下圖的流程詳細地描述了前幾次迭代的過程:
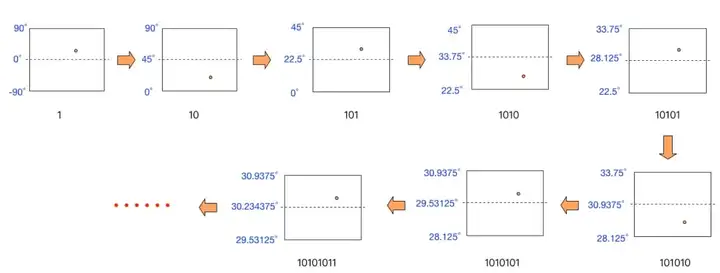
按照上面的流程,繼續往下迭代,直到編碼位數達到我們業務對精度的需求為止。完整的15位二進位制編碼迭代表格如下:
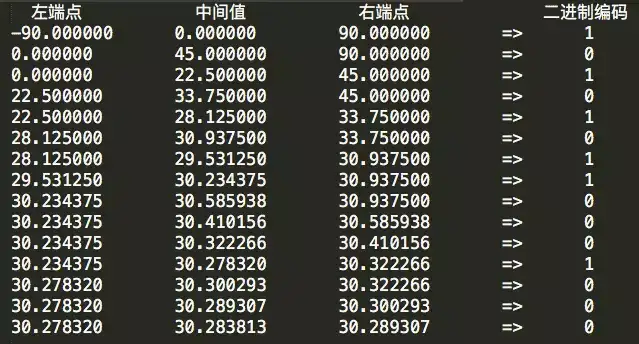
得到的緯度二進位制編碼為10101 01100 01000。
按照同樣的流程,對經度做二進位制編碼,具體迭代詳情如下:
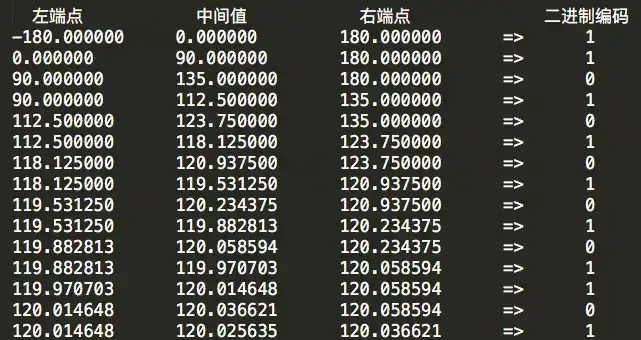
得到的經度二進位制編碼為11010 10101 01101。
按照“偶數位放經度,奇數位放緯度”的規則,將經緯度的二進位制編碼穿插,得到完成的二進位制編碼為:11100 11001 10011 10010 00111 00010。由於後續要使用的是base32編碼,每5個二進位制數對應一個32進位制數,所以這裡將每5個二進位制位轉換成十進位制位,得到28,25,19,18,7,2。 對照base32編碼表,得到對應的編碼為:wtmk72。
可以在http://geohash.org/網站對上述結果進行驗證,驗證結果如下:
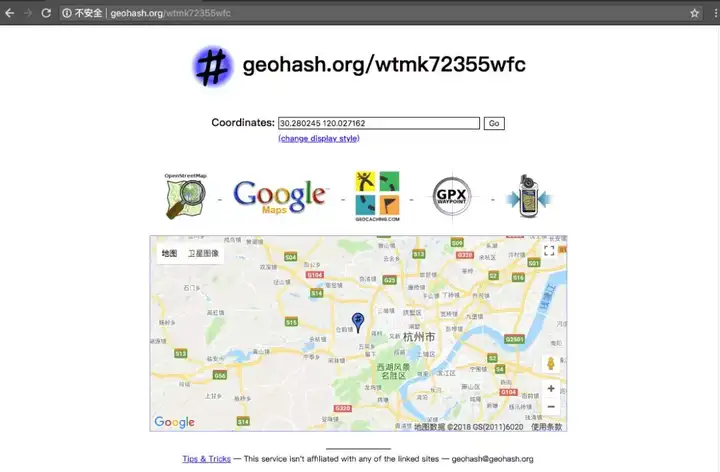
驗證結果的前幾位與我們的計算結果一致。如果我們利用二分法獲取二進位制編碼時迭代更多次,就會得到驗證網站中這樣的位數更多的更精確結果。
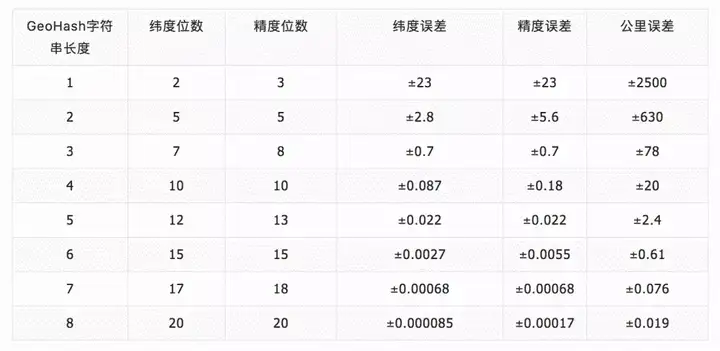
GeoHash字串的長度與精度的對應關係如下:
面數據GeoHash編碼實現
上一節介紹的標準GeoHash演算法只能用來計算二維點座標對應的GeoHash編碼,我們的場景中還需要計算面數據(即GIS中的POLYGON多邊形物件)對應的GeoHash編碼,需要擴充套件演算法來實現。
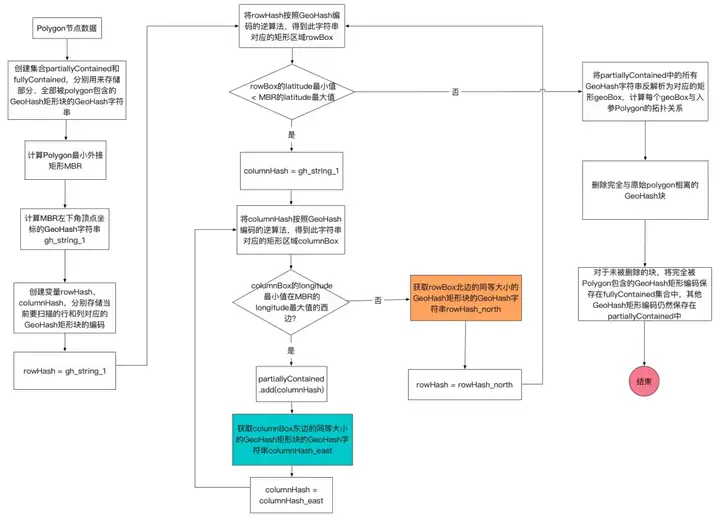
演算法思路是,先找到目標Polygon的最小外接矩形MBR,計算此MBR西南角座標對應的GeoHash編碼。然後用GeoHash編碼的逆演算法,反解出此編碼對應的矩形GeoHash塊。以此GeoHash塊為起點,迴圈往東、往北找相鄰的同等大小的GeoHash塊,直到找到的GeoHash塊完全超出MBR的範圍才停止。如此找到的多個GeoHash塊,邊緣上的部分可能與目標Polygon完全不相交,這部分塊需要通過計算剔除掉,如此一來可以減少後續不必要的計算量。
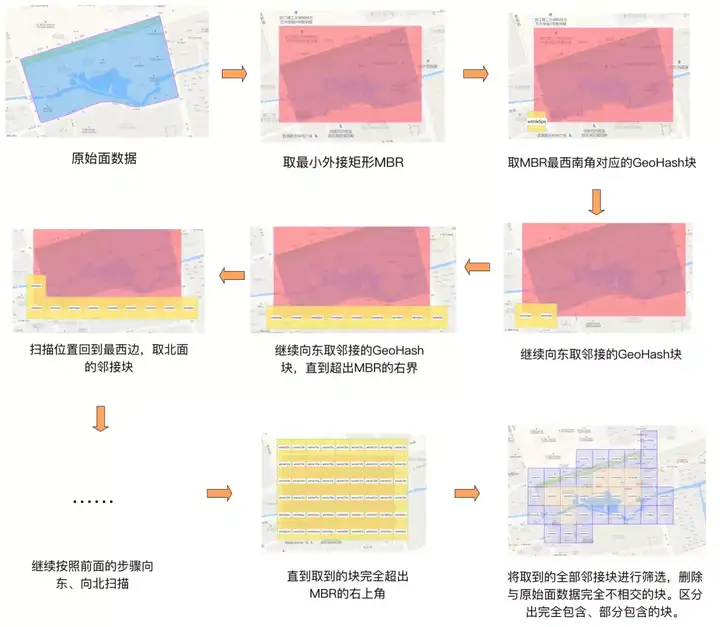
上面的例子中最終得到的結果高清大圖如下,其中藍色的GeoHash塊是與原始Polygon部分相交的,橘黃色的GeoHash塊是完全被包含在原始Polygon內部的。
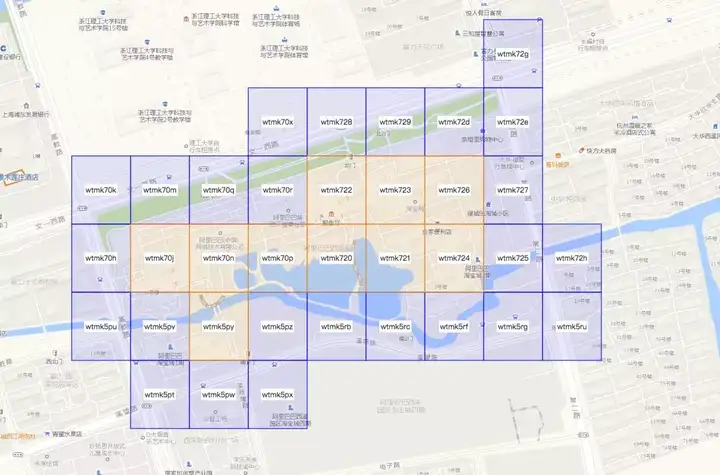
上述演算法總結成流程圖如下:
求臨近GeoHash塊的快速演算法
上一節對面資料進行GeoHash編碼的流程圖中標記為綠色和橘黃色的兩步,分別是要尋找相鄰的東邊或北邊的GeoHash字串。
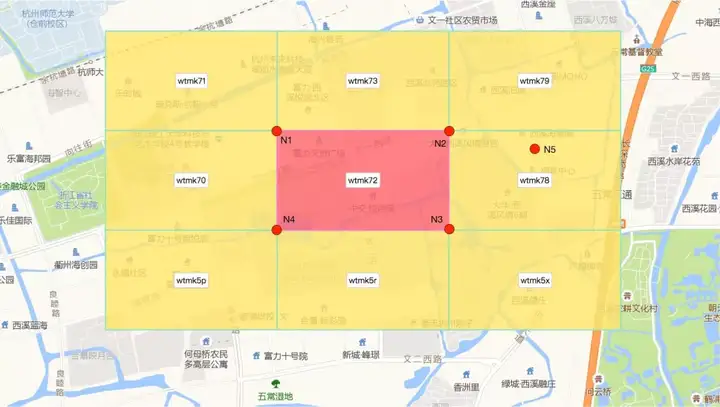
傳統的做法是,根據當前GeoHash塊的反解資訊,求出相鄰塊內部的一點,在對這個點做GeoHash編碼,即為相鄰塊的GeoHash編碼。如下圖,我們要計算"wtmk72"周圍的8個相鄰塊的編碼,就要先利用GeoHash逆演算法將"wtmk72"反解出4個頂點的座標N1、N2、N3、N4,然後由這4個座標計算出右側鄰接塊內部的任意一點座標N5,再對N5做GeoHash編碼,得到的“wtmk78”就是我們要求的右邊鄰接塊的編碼。按照同樣的方法,求可以求出"wtmk72"周圍總共8個鄰接塊的編碼。
這種方法需要先解碼一次再編碼一次,比較耗時,尤其是在指定的GeoHash字串長度較長需要迴圈較多次的情況下。
通過觀察GeoHash編碼表的規律,結合GeoHash編碼使用的Z階曲線的特性,驗證了一種通過查表來快速求相鄰GeoHash字串的方法。
還是以“wtmk72”這個GeoHash字串為例,對應的10進位制數是“28,25,19,18,7,2”,轉換成二進位制就是11100 11001 10011 10010 00111 00010。其中,w對應11100,這5個二進位制位分別代表“經 緯 經 緯 經”;t對應11001,這5個二進位制位分別代表“緯 經 緯 經 緯”。由此推廣開來可知,GeoHash中的奇數位字元(本例中的'w'、'm'、'7')代表的二進位制位分別對應“經 緯 經 緯 經”,偶數位字元(本例中的't'、'k'、'2')代表的二進位制位分別對應“緯 經 緯 經 緯”。
'w'的二進位制11100,轉換成方位含義就是“右 上 右 下 左”。't'的二進位制11001,轉換成方位含義就是“上 右 下 左 上”。
根據這個字元與方位的轉換關係,我們可以知道,奇數位上的字元與位置對照表如下:

偶數位上的字元與位置對照表如下:
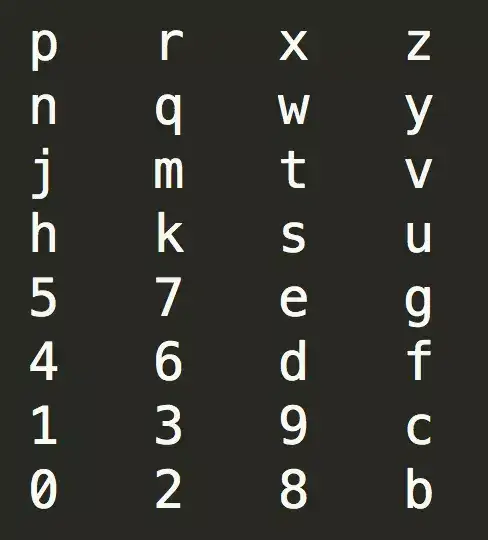
這裡可以看到一個很有意思的現象,奇數位的對照表和偶數位對照表存在一種轉置和翻轉的關係。
有了以上兩份字元與位置對照表,就可以快速得出每個字元周圍的8個字元分別是什麼。而要計算一個給定GeoHash字串周圍8個GeoHash值,如果字串最後一位字元在該方向上未超出邊界,則前面幾位保持不變,最後一位取此方向上的相鄰字元即可;如果最後一位在此方向上超出了對照表邊界,則先求倒數第二個字元在此方向上的相鄰字元,再求最後一個字元在此方向上相鄰字元(對照表環狀相鄰字元);如果倒數第二位在此方向上的相鄰字元也超出了對照表邊界,則先求倒數第三位在此方向上的相鄰字元。以此類推。
以上面的“wtmk72”舉例,要求這個GeoHash字串的8個相鄰字串,實際就是求尾部字元‘2’的相鄰字元。‘2’適用偶數對照表,它的8個相鄰字元分別是‘1’、‘3’、‘9’、‘0’、‘8’、‘p’、‘r’、‘x’,其中‘p’、‘r’、‘x’已經超出了對照表的下邊界,是將偶數位對照表上下相接組成環狀得到的相鄰關係。所以,對於這3個超出邊界的“下方”相鄰字元,需要求倒數第二位的下方相鄰字元,即‘7’的下方相鄰字元。‘7’是奇數位,適用奇數位對照表,‘7’在對照表中的“下方”相鄰字元是‘5’,所以“wtmk72”的8個相鄰GeoHash字串分別是“wtmk71”、“wtmk73”、“wtmk79”、“wtmk70”、“wtmk78”、“wtmk5p”、“wtmk5r”、“wtmk5x”。利用此相鄰字串快速演算法,可以大大提高上一節流程圖中面數據GeoHash編碼演算法的效率。
高效建立海量點資料與面數據的關係
建立海量點資料與面數據的關係的思路是,先將需要匹配的商品GPS資料(點資料)、商圈AOI資料(面數據)按照前面所述的演算法,分別計算同等長度的GeoHash編碼。每個點資料都對應唯一一個GeoHash字串;每個面數據都對應一個或多個GeoHash編碼,這些編碼要麼是“完全包含字串”,要麼是“部分包含字串”。
a)將每個商品的GeoHash字串與商圈的“完全包含字串”進行join操作。join得到的結果中出現的<商品,商圈>資料就是能夠確定的“某個商品屬於某個商圈”的關係。
b)對於剩下的還未被確定關係的商品,將這些商品的GeoHash字串與商圈的“部分包含字串”進行join操作。join得到的結果中出現的<商品,商圈>資料是有可能存在的“商品屬於某個商圈”的關係,接下來對這批資料中的商品gps和商圈AOI資料進行幾何學關係運算,進而從中篩選出確定的“商品屬於某個商圈”的關係。
如圖,商品1的點資料GeoHash編碼為"wtmk70j",與面數據的“完全包含字串wtmk70j”join成功,所以可以直接確定商品1屬於此面數據。
商品2的點資料GeoHash編碼為“wtmk70r”,與面數據的“部分包含字串wtmk70r”join成功,所以商品2疑似屬於面數據,具體是否存在包含關係,還需要後續的點面幾何學計算來確定。 商品3的點資料GeoHash編碼與面數據的任何GeoHash塊編碼都匹配不上,所以可以快速確定商品3不屬於此面數據。
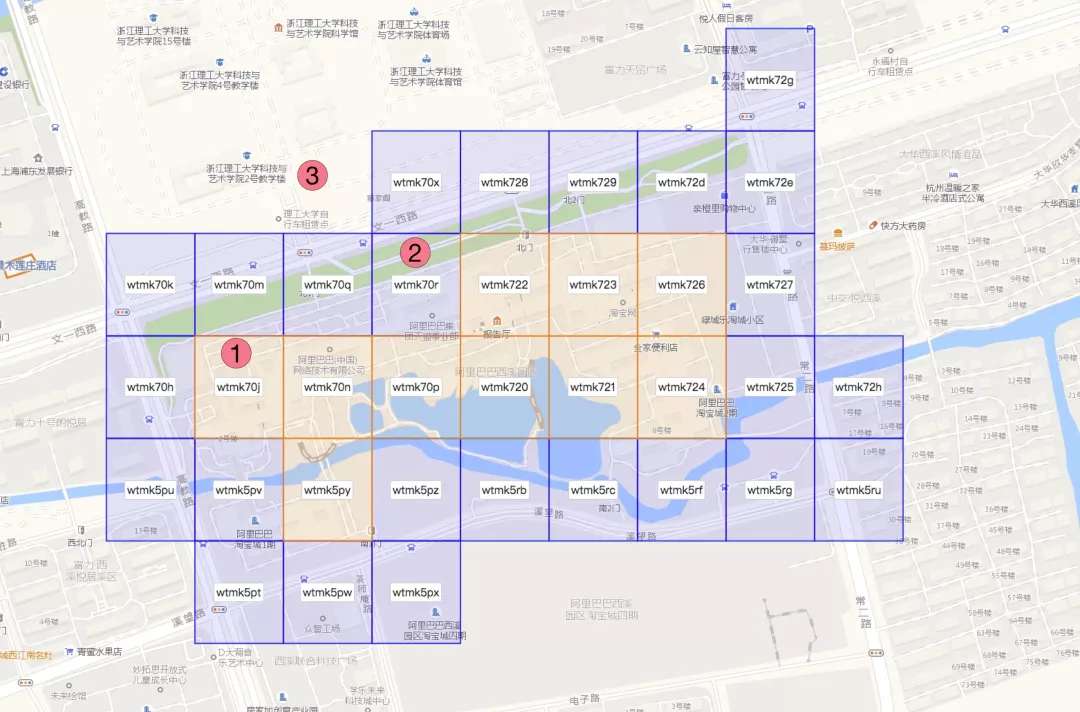
實際應用中,原始的海量商品GPS範圍散佈在全國各地,海量商圈資料也散佈在全國各個不同的城市。經過a)步驟的操作後,大部分的商品資料已經確定了與商圈的從屬關係。剩下的未能匹配上的商品資料,經過b)步驟的GeoHash匹配後,可以將後續“商品-商圈幾何學計算”的運算量從“1個商品 x 全國所有商圈”笛卡爾積的量級,降低為“1個商品 x 1個(或幾個)商圈”笛卡爾積的量級,減少了絕大部分不必要的幾何學運算,而這部分運算是非常耗時的。
在閒魚的實際應用中,10億商品和1萬商圈資料,使用本文的快速演算法,只需要 10億次GeoHash點編碼 + 1萬次GeoHash面編碼 + 500萬次“點是否在面內部”幾何學運算,粗略換算為基本運算需要的次數約為1800億次,運算量遠小於傳統方法的2億億次基本運算。使用阿里巴巴的離線計算平臺,本文的演算法在不到一天的時間內就完成了全部計算工作。
另外,對於給定的點和多邊形,通過幾何學計算包含關係的演算法不止一種,最常用的演算法是射線法。簡單來說,就是從這個點出發做一條射線,判斷該射線與多邊形的交點個數是奇數還是偶數。如果是奇數,說明點在多邊形內;否則,點在多邊形外。
延伸
面對海量點面數據的空間關係劃分,本文采用是的通過GeoHash來降低計算量的思路,本質上來說是利用了空間索引的思想。事實上,在GIS領域有多種實用的空間索引,常見的如R樹系列(R樹、R+樹、R*樹)、四叉樹、K-D樹、網格索引等,這些索引演算法各有特點。本文的思路不僅能用來處理點—面關係的相關問題,還可以用來快速處理點—點關係、面—面關係、點—線關係、線—線關係等問題,比如快速確定大範圍類的海量公交站臺與道路的從屬關係、多條道路或鐵路是否存在交點等問題。
歡迎大家和閒魚團隊交流討論相關的演算法優化,也歡迎各路高手加入阿里巴巴——閒魚團隊,和我們一起用技術改變世界。