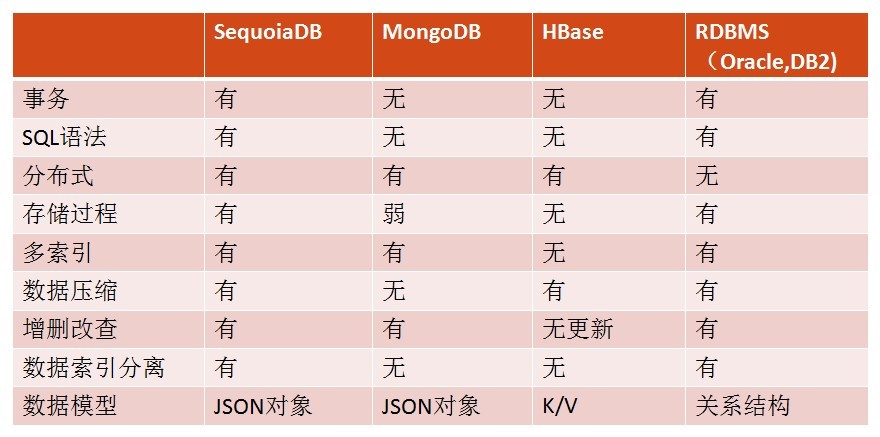
15個nosql資料庫
1、MongoDB
介紹
MongoDB是一個基於分散式檔案儲存的資料庫。由C++語言編寫。主要解決的是海量資料的訪問效率問題,為WEB應用提供可擴充套件的高效能資料儲存解決方案。當資料量達到50GB以上的時候,MongoDB的資料庫訪問速度是MySQL的10倍以上。MongoDB的併發讀寫效率不是特別出色,根據官方提供的效能測試表明,大約每秒可以處理0.5萬~1.5萬次讀寫請求。MongoDB還自帶了一個出色的分散式檔案系統GridFS,可以支援海量的資料儲存。
MongoDB也有一個Ruby的專案MongoMapper,是模仿Merb的DataMapper編寫的MongoDB介面,使用起來非常簡單,幾乎和DataMapper一模一樣,功能非常強大。
MongoDB是一個介於關係資料庫和非關係資料庫之間的產品,是非關係資料庫當中功能最豐富,最像關係資料庫的。他支援的資料結構非常鬆散,是類似json的bjson格式,因此可以儲存比較複雜的資料型別。Mongo最大的特點是他支援的查詢語言非常強大,其語法有點類似於面向物件的查詢語言,幾乎可以實現類似關係資料庫單表查詢的絕大部分功能,而且還支援對資料建立索引。
所謂“面向集合”(Collenction-Orented),意思是資料被分組儲存在資料集中,被稱為一個集合(Collenction)。每個 集合在資料庫中都有一個唯一的標識名,並且可以包含無限數目的文件。集合的概念類似關係型資料庫(RDBMS)裡的表(table),不同的是它不需要定 義任何模式(schema)。
模式自由(schema-free),意味著對於儲存在mongodb資料庫中的檔案,我們不需要知道它的任何結構定義。如果需要的話,你完全可以把不同結構的檔案儲存在同一個資料庫裡。
儲存在集合中的文件,被儲存為鍵-值對的形式。鍵用於唯一標識一個文件,為字串型別,而值則可以是各中複雜的檔案型別。我們稱這種儲存形式為BSON(Binary Serialized dOcument Format)。
MongoDB服務端可執行在Linux、Windows或OS X平臺,支援32位和64位應用,預設埠為27017。推薦執行在64位平臺,因為MongoDB在32位模式執行時支援的最大檔案尺寸為2GB。
MongoDB把資料儲存在檔案中(預設路徑為:/data/db),為提高效率使用記憶體對映檔案進行管理。
特性
它的特點是高效能、易部署、易使用,儲存資料非常方便。主要功能特性有:
面向集合儲存,易儲存物件型別的資料。 模式自由。 支援動態查詢。 支援完全索引,包含內部物件。 支援查詢。 支援複製和故障恢復。 使用高效的二進位制資料儲存,包括大型物件(如視訊等)。 自動處理碎片,以支援雲端計算層次的擴充套件性。 支援RUBY,PYTHON,JAVA,C++,PHP,C#等多種語言。 檔案儲存格式為BSON(一種JSON的擴充套件)。 可通過網路訪問。官方網站
2、CouchDB
介紹
Apache CouchDB 是一個面向文件的資料庫管理系統。它提供以 JSON 作為資料格式的 REST 介面來對其進行操作,並可以通過檢視來操縱文件的組織和呈現。 CouchDB 是 Apache 基金會的頂級開源專案。
CouchDB是用Erlang開發的面向文件的資料庫系統,其資料儲存方式類似Lucene的Index檔案格式。CouchDB最大的意義在於它是一個面向Web應用的新一代儲存系統,事實上,CouchDB的口號就是:下一代的Web應用儲存系統。
特性
主要功能特性有:
CouchDB是分散式的資料庫,他可以把儲存系統分佈到n臺物理的節點上面,並且很好的協調和同步節點之間的資料讀寫一致性。這當然也得以於Erlang無與倫比的併發特性才能做到。對於基於web的大規模應用文件應用,然的分散式可以讓它不必像傳統的關係資料庫那樣分庫拆表,在應用程式碼層進行大量的改動。 CouchDB是面向文件的資料庫,儲存半結構化的資料,比較類似lucene的index結構,特別適合儲存文件,因此很適合CMS,電話本,地址本等應用,在這些應用場合,文件資料庫要比關係資料庫更加方便,效能更好。 CouchDB支援REST API,可以讓使用者使用JavaScript來操作CouchDB資料庫,也可以用JavaScript編寫查詢語句,我們可以想像一下,用AJAX技術結合CouchDB開發出來的CMS系統會是多麼的簡單和方便。其實CouchDB只是Erlang應用的冰山一角,在最近幾年,基於Erlang的應用也得到的蓬勃的發展,特別是在基於web的大規模,分散式應用領域,幾乎都是Erlang的優勢專案。官方網站
3、Hbase
介紹
HBase是一個分散式的、面向列的開源資料庫,該技術來源於Chang et al所撰寫的Google論文“Bigtable:一個結構化資料的分散式儲存系統”。就像Bigtable利用了Google檔案系統(File System)所提供的分散式資料儲存一樣,HBase在Hadoop之上提供了類似於Bigtable的能力。HBase是Apache的Hadoop專案的子專案。HBase不同於一般的關係資料庫,它是一個適合於非結構化資料儲存的資料庫.另一個不同的是HBase基於列的而不是基於行的模式。
HBase – Hadoop Database,是一個高可靠性、高效能、面向列、可伸縮的分散式儲存系統,利用HBase技術可在廉價PC Server上搭建起大規模結構化儲存叢集。 HBase是Google Bigtable的開源實現,類似Google Bigtable利用GFS作為其檔案儲存系統,HBase利用Hadoop HDFS作為其檔案儲存系統;Google執行MapReduce來處理Bigtable中的海量資料,HBase同樣利用Hadoop MapReduce來處理HBase中的海量資料;Google Bigtable利用 Chubby作為協同服務,HBase利用Zookeeper作為對應。
HBase訪問介面
Native Java API,最常規和高效的訪問方式,適合Hadoop MapReduce Job並行批處理HBase表資料 HBase Shell,HBase的命令列工具,最簡單的介面,適合HBase管理使用 Thrift Gateway,利用Thrift序列化技術,支援C++,PHP,Python等多種語言,適合其他異構系統線上訪問HBase表資料 REST Gateway,支援REST 風格的Http API訪問HBase, 解除了語言限制 Pig,可以使用Pig Latin流式程式語言來操作HBase中的資料,和Hive類似,本質最終也是編譯成MapReduce Job來處理HBase表資料,適合做資料統計 Hive,當前Hive的Release版本尚沒有加入對HBase的支援,但在下一個版本Hive 0.7.0中將會支援HBase,可以使用類似SQL語言來訪問HBase特性
主要功能特性有:
支援數十億行X上百萬列
採用分散式架構 Map/reduce
對實時查詢進行優化
高效能 Thrift閘道器
通過在server端掃描及過濾實現對查詢操作預判
支援 XML, Protobuf, 和binary的HTTP
基於 Jruby( JIRB)的shell
對配置改變和較小的升級都會重新回滾
不會出現單點故障
堪比MySQL的隨機訪問效能
官方網站
4、cassandra
介紹
Cassandra是一個混合型的非關係的資料庫,類似於Google的BigTable。其主要功能比Dynomite(分散式的Key-Value儲存系統)更豐富,但支援度卻不如文件儲存MongoDB(介於關係資料庫和非關係資料庫之間的開源產品,是非關係資料庫當中功能最豐富,最像關係資料庫的。支援的資料結構非常鬆散,是類似json的bjson格式,因此可以儲存比較複雜的資料型別。)Cassandra最初由Facebook開發,後轉變成了開源專案。它是一個網路社交雲端計算方面理想的資料庫。以Amazon專有的完全分散式的Dynamo為基礎,結合了Google BigTable基於列族(Column Family)的資料模型。P2P去中心化的儲存。很多方面都可以稱之為Dynamo 2.0。
特性
和其他資料庫比較,有幾個突出特點:
模式靈活 :使用Cassandra,像文件儲存,你不必提前解決記錄中的欄位。你可以在系統執行時隨意的新增或移除欄位。這是一個驚人的效率提升,特別是在大型部 署上。
真正的可擴充套件性 :Cassandra是純粹意義上的水平擴充套件。為給叢集新增更多容量,可以指向另一臺電腦。你不必重啟任何程序,改變應用查詢,或手動遷移任何資料。
多資料中心識別 :你可以調整你的節點佈局來避免某一個數據中心起火,一個備用的資料中心將至少有每條記錄的完全複製。
一些使Cassandra提高競爭力的其他功能:
範圍查詢 :如果你不喜歡全部的鍵值查詢,則可以設定鍵的範圍來查詢。
列表資料結構 :在混合模式可以將超級列新增到5維。對於每個使用者的索引,這是非常方便的。
分散式寫操作 :有可以在任何地方任何時間集中讀或寫任何資料。並且不會有任何單點失敗。
官方網站
5、Hypertable
介紹
Hypertable是一個開源、高效能、可伸縮的資料庫,它採用與Google的Bigtable相似的模型。在過去數年中,Google為在 PC叢集 上執行的可伸縮計算基礎設施設計建造了三個關鍵部分。第一個關鍵的基礎設施是Google File System(GFS),這是一個高可用的檔案系統,提供了一個全域性的名稱空間。它通過跨機器(和跨機架)的檔案資料複製來達到高可用性,並因此免受傳統 檔案儲存系統無法避免的許多失敗的影響,比如電源、記憶體和網路埠等失敗。第二個基礎設施是名為Map-Reduce的計算框架,它與GFS緊密協作,幫 助處理收集到的海量資料。第三個基礎設施是Bigtable,它是傳統資料庫的替代。Bigtable讓你可以通過一些主鍵來組織海量資料,並實現高效的 查詢。Hypertable是Bigtable的一個開源實現,並且根據我們的想法進行了一些改進。
特性
主要功能特點:
負載均衡的處理
版本控制和一致性
可靠性
分佈為多個節點
官方網站
6、Redis
介紹
redis是一個key-value儲存系統。和Memcached類似,它支援儲存的value型別相對更多,包括string(字串)、list(連結串列)、set(集合)和zset(有序集合)。這些資料型別都支援push/pop、add/remove及取交集並集和差集及更豐富的操作,而且這些操作都是原子性的。在此基礎上,redis支援各種不同方式的排序。與memcached一樣,為了保證效率,資料都是快取在記憶體中。區別的是redis會週期性的把更新的資料寫入磁碟或者把修改操作寫入追加的記錄檔案,並且在此基礎上實現了master-slave(主從)同步。
效能測試結果:
SET操作每秒鐘 110000 次,GET操作每秒鐘 81000 次,伺服器配置如下:
Linux 2.6, Xeon X3320 2.5Ghz.
stackoverflow 網站使用 Redis 做為快取伺服器。
特點
主要功能特點:
安全性
主從複製
執行異常快
支援 sets(同時也支援 union/diff/inter)
支援列表(同時也支援佇列;阻塞式 pop操作)
支援雜湊表(帶有多個域的物件)
支援排序 sets(高得分表,適用於範圍查詢)
Redis支援事務
支援將資料設定成過期資料(類似快速緩衝區設計)
Pub/Sub允許使用者實現訊息機制
官方網站
7、Tokyo Cabinet/Tokyo Tyant
介紹
Tokyo Cabinet(TC)和Tokyo Tyrant(TT)的開發者是日本人Mikio Hirabayashi,主要用於日本最大的SNS網站mixi.jp。TC出現的時間最早,現在已經是一個非常成熟的專案,也是Key-Value資料庫領域最大的熱點,現在廣泛應用於網站。TC是一個高效能的儲存引擎,而TT提供了多執行緒高併發伺服器,效能也非常出色,每秒可以處理4萬~5萬次讀寫操作。
TC除了支援Key-Value儲存之外,還支援Hashtable資料型別,因此很像一個簡單的資料庫表,並且還支援基於Column的條件查詢、分頁查詢和排序功能,基本上相當於支援單表的基礎查詢功能,所以可以簡單地替代關係資料庫的很多操作,這也是TC受到大家歡迎的主要原因之一。有一個Ruby專案miyazakiresistance將TT的Hashtable的操作封裝成和ActiveRecord一樣的操作,用起來非常高效。
特性
TC/TT在Mixi的實際應用當中,儲存了2000萬條以上的資料,同時支撐了上萬個併發連線,是一個久經考驗的專案。TC在保證了極高的併發讀寫效能的同時,還具有可靠的資料持久化機制,同時還支援類似關係資料庫表結構的Hashtable以及簡單的條件、分頁和排序操作,是一個很優越的NoSQL資料庫。
TC的主要缺點是,在資料量達到上億級別以後,併發寫資料效能會大幅度下降,開發人員發現在TC裡面插入1.6億條2KB~20KB資料的時候,寫入效能開始急劇下降。即當資料量達到上億條的時候,TC效能便開始大幅度下降,從TC作者自己提供的Mixi資料來看,至少上千萬條資料量的時候還沒有遇到這麼明顯的寫入效能瓶頸。
官方網站
8、Flare
介紹
TC是日本第一大SNS網站mixi.jp開發的,而Flare是日本第二大SNS網站green.jp開發的。簡單地說,Flare就是給TC添加了scale(可擴充套件)功能。它替換了TT部分,自己另外給TC寫了網路伺服器。Flare的主要特點就是支援scale能力,它在網路服務端之前添加了一個Node Server,用來管理後端的多個伺服器節點,因此可以動態新增資料庫服務節點、刪除伺服器節點,也支援Failover。如果你的使用場景必須讓TC可以scale,那麼可以考慮Flare。
flare唯一的缺點就是他只支援memcached協議,因此當你使用flare的時候,就不能使用TC的table資料結構了,只能使用TC的key-value資料結構儲存。
特性
沒找到相關的介紹。
官方網站
9、Berkeley DB
介紹
Berkeley DB (DB)是一個高效能的,嵌入資料庫程式設計庫,和C語言,C++,Java,Perl,Python,PHP,Tcl以及其他很多語言都有繫結。Berkeley DB可以儲存任意型別的鍵/值對,而且可以為一個鍵儲存多個數據。Berkeley DB可以支援數千的併發執行緒同時操作資料庫,支援最大256TB的資料,廣泛 用於各種作業系統包括大多數Unix類作業系統和Windows作業系統以及實時作業系統。
Berkeley DB最初開發的目的是以新的HASH訪問演算法來代替舊的hsearch函式和大量的dbm實現(如AT&T的dbm,Berkeley的 ndbm,GNU專案的gdbm),Berkeley DB的第一個發行版在1991年出現,當時還包含了B+樹資料訪問演算法。在1992年,BSD UNIX第4.4發行版中包含了Berkeley DB1.85版。基本上認為這是Berkeley DB的第一個正式版。在1996年中期,Sleepycat軟體公司成立,提供對Berkeley DB的商業支援。在這以後,Berkeley DB得到了廣泛的應用,成為一款獨樹一幟的嵌入式資料庫系統。2006年Sleepycat公司被Oracle 公司收購,Berkeley DB成為Oracle資料庫家族的一員,Sleepycat原有開發者繼續在Oracle開發Berkeley DB,Oracle繼續原來的授權方式並且加大了對Berkeley DB的開發力度,繼續提升了Berkeley DB在軟體行業的聲譽。Berkeley DB的當前最新發行版本是4.7.25。
特性
主要特點:
訪問速度快
省硬碟空間
官方網站
10、memcachedb
介紹
MemcacheDB是一個分散式、key-value形式的持久儲存系統。它不是一個快取元件,而是一個基於物件存取的、可靠的、快速的持久儲存引擎。協議跟memcache一致(不完整),所以很多memcached客戶端都可以跟它連線。MemcacheDB採用Berkeley DB作為持久儲存元件,故很多Berkeley DB的特性的他都支援。
特性
MemcacheDB是一個分散式、key-value形式的持久儲存系統。它不是一個快取元件,而是一個基於物件存取的、可靠的、快速的持久儲存引擎。 協議跟memcache一致(不完整),所以很多memcached客戶端都可以跟它連線。MemcacheDB採用Berkeley DB作為持久儲存元件,故很多Berkeley DB的特性的他都支援。 我們是站在巨人的肩膀上的。MemcacheDB的前端快取是Memcached 前端:memcached的網路層 後端:BerkeleyDB儲存
寫速度:從本地伺服器通過memcache客戶端(libmemcache)set2億條16位元組長的key,10位元組長的Value的記錄,耗時 16572秒,平均速度12000條記錄/秒。
讀速度:從本地伺服器通過memcache客戶端(libmemcache)get100萬條16位元組長的key,10位元組長的Value的記錄,耗 時103秒,平均速度10000條記錄/秒。 ·支援的memcache命令
官方網站
11、Memlink
介紹
Memlink 是天涯社群開發的一個高效能、持久化、分散式的Key-list/queue資料引擎。正如名稱中的memlink所示,所有資料都建構在記憶體中,保證了 系統的高效能 (大約是redis幾倍),同時使用了redo-log技術保證資料的持久化。Memlink還支援主從複製、讀寫分離、List過濾操作等功能。
與Memcached不同的是,它的value是一個list/queue。並且提供了諸如持久化,分散式的功能。聽起來有點像Redis,但它號稱比Redis更好,在很多Redis做得還不好的地方進行了改進和完善。提供的客戶端開發包包括 c,python,php,java 四種語言。
特性
特點:
記憶體資料引擎,效能極為高效 List塊鏈結構,精簡記憶體,優化查詢效率 Node資料項可定義,支援多種過濾操作 支援redo-log,資料持久化,非Cache模式 分散式,主從同步官方網站
12、db4o
介紹
“利用表格儲存物件,就像是將汽車開回家,然後拆成零件放進車庫裡,早晨可以再把汽車裝配起來。但是人們不禁要問,這是不是泊車的最有效的方法呢。” – Esther Dyson db4o 是一個開源的純面向物件資料庫引擎,對於 Java 與 .NET 開發者來說都是一個簡單易用的物件持久化工具,使用簡單。同時,db4o 已經被第三方驗證為具有優秀效能的面向物件資料庫, 下面的基準測試圖對 db4o 和一些傳統的持久方案進行了比較。db4o 在這次比較中排名第二,僅僅落後於JDBC。通過圖 1 的基準測試結果,值得我們細細品味的是採用 Hibernate/HSQLDB 的方案和 JDBC/HSQLDB 的方案在效能方面有著顯著差距,這也證實了業界對 Hibernate 的擔憂。而 db4o 的優異效能,讓我們相信: 更 OO 並不一定會犧牲效能。
同時,db4o 的一個特點就是無需 DBA 的管理,佔用資源很小,這很適合嵌入式應用以及 Cache 應用, 所以自從 db4o 釋出以來,迅速吸引了大批使用者將 db4o 用於各種各樣的嵌入式系統,包括流動軟體、醫療裝置和實時控制系統。 db4o 由來自加州矽谷的開源資料庫公司 db4objects 開發並負責商業運營和支援。db4o 是基於 GPL 協議。db4objects 於 2004 年在 CEO Christof Wittig 的領導下組成,資金背景包括 Mark Leslie 、 Veritas 軟體公司 CEO 、 Vinod Khosla ( Sun 公司創始人之一)、 Sun 公司 CEO 在內的矽谷高層投資人組成。毫無疑問,今天 db4objects 公司是矽谷炙手可熱的技術創新者之一。
特性
db4o 的目標是提供一個功能強大的,適合嵌入的資料庫引擎,可以工作在裝置,移動產品,桌面以及伺服器等各種平臺。主要特性如下: 開源模式。與其他 ODBMS 不同,db4o 為開源軟體,通過開源社群的力量驅動開發 db4o 產品。 原生資料庫。db4o 是 100% 原生的面向物件資料庫,直接使用程式語言來操作資料庫。程式設計師無需進行 OR 對映來儲存物件,大大節省了程式設計師在儲存資料的開發時間。 高效能。 下圖為 db4o 官方公佈的基準測試資料,db4o 比採用 Hibernate/MySQL 方案在某些測試線路上速度高出 44 倍之多!並且安裝簡單,僅僅需要 400Kb 左右的 .jar 或 .dll 庫檔案。在接下來的系列文章中,我們將只關注在 Java 平臺的應用,但是實際上 db4o 毫無疑問會很好地在 .NET平臺工作。
圖:官方測試資料
易嵌入。使用 db4o 僅需引入 400 多 k 的 jar 檔案或是 dll 檔案,記憶體消耗極小。 零管理。使用 db4o 無需 DBA,實現零管理。 支援多種平臺。db4o 支援從 Java 1.1 到 Java 5.0,此外還支援 .NET 、 CompactFramework 、 Mono 等 .NET 平臺,也可以執行在 CDC 、 PersonalProfile 、 Symbian 、 Savaje 以及 Zaurus 這種支援反射的 J2ME 方言環境中,還可以執行在 CLDC 、 MIDP 、 RIM/Blackberry 、 Palm OS 這種不支援反射的 J2ME 環境中。 或許開發者會問,如果現有的應用環境已經有了關係型資料庫怎麼辦?沒關係,db4o 的 dRS(db4o Replication System)可實現 db4o 與關係型資料庫的雙向同步(複製),如圖 3 。 dRS 是基於 Hibernate 開發,目前的版本是 1.0 ,並執行在 Java 1.2 或更高版本平臺上,基於 dRS 可實現 db4o 到 Hibernate/RDBMS 、 db4o 到 db4o 以及 Hibernate/RDBMS 到 Hibernate/RDBMS 的雙向複製。dRS 模型如圖
圖:DRS模型
官方網站
13、Versant
介紹
Versant Object Database (V/OD) 提供強大的資料管理,面向 C++, Java or .NET 的物件模型,支援大併發和大規模資料集合。
Versant物件資料庫是一個物件資料庫管理系統(ODBMS:Object Database Management System)。它主要被用在複雜的、分散式的和異構的環境中,用來減少開發量和提高效能。尤其當程式是使用Java和(或)C++語言編寫的時候,尤其有用。
它是一個完整的,電子基礎設施軟體,簡化了事務的構建和部署的分散式應用程式。
作為一個卓越的資料庫產品,Versant ODBMS在設計時的目標就是為了滿足客戶在異類處理平臺和企業級資訊系統中對於高效能、可量測性、可靠性和相容性方面的需求。
Versant物件資料庫已經在為企業業務應用提供可靠性、完整性和高效能方面獲得了建樹,Versant ODBMS所表現出的高效的多執行緒架構、internal parallelism 、平穩的Client-Server結構和高效的查詢優化,都體現了其非常卓越的效能和可擴充套件性。
Versant物件資料庫包括Versant ODBMS,C++和Java語言介面,XML工具包和非同步複製框架。
特性
一、強有力的優勢
Versant Object Database8.0,適用於應用環境中包含複雜物件模型的資料庫,其設計目標是能夠處理這些應用經常需要的導航式訪問,無縫的資料分發,和企業級的規模。
對於很多應用程式而言,最具挑戰性的方面是控制業務模型本身的內在複雜性。 電信基礎設施,交通運輸網路,模擬,金融工具以及其它領域的複雜性必須得到支援, 而且這種支援複雜性的方式還要能夠隨著環境和需求變化而不斷地改進應用程式。 這些應用程式的重點是領域和這些領域的邏輯。 複雜的設計應當以物件模型為基礎。將技術需求例如永續性(和SQL)與領域模型混合在一起的架構會帶來災難性的後果。
Versant物件資料庫使您可以使用那些只含有域行為資訊的物件,而不用考慮永續性。同時,Versant物件資料庫還能提供跨多個數據庫的無縫的資料分發,高併發性,細粒度鎖,頂級效能, 以及通過複製和其它技術提供的高可用性。現代Java中的物件關係對映工具已經簡化了很多對映的問題, 但是它們還不能提供Versant所能提供的無縫資料分發的功能和高效能。
二、主要特性
C++、Java及.NET 的透明物件持久
支援物件持久標準,如JDO
跨多資料庫的無縫資料分發
企業級的高可用性選項
動態模式更新
管理工作量少(或不需要)
端到端的物件支援架構
細粒度併發控制
多執行緒,多會話
支援國際字符集
高速資料採集
三、優勢
物件層次結構的快速儲存、檢索和瀏覽
效能高於關係型資料庫10 倍以上
減少開發時間
四、8.0的新特性
增強的多核線性擴充套件能力
增強的資料庫管理工具(監控、資料庫檢查、資料重組)
支援基於LINQ的.NET繫結機制
支援.NET和JDO應用的FTS基於“Black Box”工具的資料庫活動記錄與分析
五、Versant物件資料庫特性
動態模式更新
Versant支援緩慢模式更新,這意味著當被使用時,物件才會從舊的模式轉為新的模式,就不需要映射了。所有這些都支援資料庫模式的更新與敏捷開發。
跨多資料庫的無縫資料分發
客戶端與一個或多個數據庫進行無縫互動。單個的資料庫無縫地聯合在一起,使您能夠給資料分割槽,提高讀寫能力,增大總體的資料庫的大小。這些資料庫上的資料分發是透明的。它們被結合在一起形成一個
無縫的資料庫,提供巨大的可擴充套件性。
併發控制
物件級鎖確保只有在兩個應用程式試圖更新同一物件時才會有衝突的發生,這與基於頁的鎖機制不同。基於頁的鎖機制可能會導致併發熱點的假象。
透明的C++物件永續性
C++物件,STL類,標準C++集合如字典,對映,對映的對映,諸如此類,以原樣儲存在資料庫中。狀態變化在後臺被自動追蹤。當相關的事務提交後,所有的變化將會被自動傳送到資料庫。因此就能形成一種非常自然的,低干擾的程式設計風格,這樣,就能實現應用程式的快速開發,同時當需求發生變化時,應用程式就能夠靈活地修改。
透明的Java物件永續性
V/OD的JVI & JDO 2.0 API 提供了透明的簡單物件(POJO)的永續性,包括 Java 2 持久類,介面,以及任何使用者定義的類。狀態變化
在後臺被自動追蹤。事務提交後,自動把所有變化寫入資料庫。因此,對於託管和非託管部署,您都能獲得輕量級的程式設計風格。
可完全嵌入Versant 可以被嵌入到應用程式中,資料庫規模可以達到TB 級別。
並且可以自主執行,不需要任何管理。
六、企業級的特性
物件端到端
物件端到端意味著你的應用物件存在於客戶端,網路上,以及資料庫中。與關係型資料庫不同的是,物件在記憶體中和資料庫中的表示之間不需要任何對映或轉換。
應用的客戶端快取透明地快取物件以提高速度。資料庫支援物件,它能執行查詢,建立索引,使應用能夠平衡它和資料庫間的程序執行。XA的支援使與其它事務資料來源協調成為可能。
七、V/OD 8資料庫體系架構
高可用性
通過線上進行資料庫管理實現資料庫的高可用性。
容錯伺服器
容錯伺服器選項可以在Versant資料庫的硬體或是軟體出現故障的時候,自動進行失效轉移和資料恢復。容錯伺服器使用的是在兩個資料庫例項之間進行同步複製,一旦出現故障,容錯伺服器也會支援透明重同步。
非同步資料複製
非同步資料複製選項支援多個物件伺服器之間的主從非同步複製和點對點非同步複製。可以使用非同步資料複製將資料複製到一個分散式恢復站點或者將資料在多個本地的物件資料庫之間進行復制,以提高效能和可靠性。
高可用性備份
高可用性資料備份選項使Versant可以使用EMC Symmetrix或其它企業級儲存系統的磁碟映象的特性,來對很大的資料捲進行線上備份,同時又不會影響到可用性。
線上再組織
Versant 資料庫再組織選項為了會刪除大量物件的應用而設計的。它使使用者能夠收回資料庫中未使用的空間,同時使資料庫保持正常運作,增加可用空間,改善資料庫的效能。
八、為什麼要使用Versant面向物件資料庫?
通過縮短研發時間來加速上市
物件關係對映程式碼可能佔用了你的應用的40%或更多。有了Versant面向物件資料庫,對映程式碼就不再需要了。
極大地提高了效能和資料吞吐能力
當應用中涉及到複雜的記憶體物件模式,尤其是關聯訪問時,物件資料庫要比對映到關係資料庫表現得更好。例如,當應用程式需要從物件資料庫裡檢索一個物件時,只要執行單條查詢即可找到該物件。當對映到一個關係資料庫時,如果物件包含多對多關聯,那麼就必須通過一個或多個連線才能檢索到關聯表中的資料。使用了物件資料庫,對於一般複雜性的物件的檢索,速度則提高了三倍,對於複雜性很高的物件的檢索,例如多對多關聯,搜尋的速度則提高了三十倍。而對於集合的集合和遞迴聯絡,檢索的速度有可能提高五十倍。
根據需求的變化,快速改進應用
今天,商業程序、結構和應用要求的變化的速度使得適應變化的能力變得極為重要。物件關係對映和其它適用於剛性儲存結構的方法,讓變化變得困難。而Versant物件資料庫極大的提升了你的應用滿足當前和未來的商業需求的能力。
投資回報率
當用戶遇到了複雜的物件模型和大的資料集,物件資料庫就是首選的解決方案。物件資料庫主要的優點在於,它能夠縮小程式碼的規模,降低研發成本,縮短上市的時間,減少或根本沒有管理的要求以及降低購置硬體和伺服器軟體許可證的成本。效能上的優勢還可以大大降低高負載動作應用所消耗的成本。大型的關係資料庫成本高非常昂貴,還需要昂貴的硬體支援
官方網站
14、Neo4j
介紹
Neo4j是一個嵌入式,基於磁碟的,支援完整事務的Java持久化引擎,它在影象中而不是表中儲存資料。Neo4j提供了大規模可擴充套件性,在一臺機器上可以處理數十億節點/關係/屬性的影象,可以擴充套件到多臺機器並行執行。相對於關係資料庫來說,圖形資料庫善於處理大量複雜、互連線、低結構化的資料,這些資料變化迅速,需要頻繁的查詢——在關係資料庫中,這些查詢會導致大量的表連線,因此會產生效能上的問題。Neo4j重點解決了擁有大量連線的傳統RDBMS在查詢時出現的效能衰退問題。通過圍繞圖形進行資料建模,Neo4j會以相同的速度遍歷節點與邊,其遍歷速度與構成圖形的資料量沒有任何關係。此外,Neo4j還提供了非常快的圖形演算法、推薦系統和OLAP風格的分析,而這一切在目前的RDBMS系統中都是無法實現的。
Neo是一個網路——面向網路的資料庫——也就是說,它是一個嵌入式的、基於磁碟的、具備完全的事務特性的Java持久化引擎,但是它將結構化資料儲存在網路上而不是表中。網路(從數學角度叫做圖)是一個靈活的資料結構,可以應用更加敏捷和快速的開發模式。
你可以把Neo看作是一個高效能的圖引擎,該引擎具有成熟和健壯的資料庫的所有特性。程式設計師工作在一個面向物件的、靈活的網路結構下而不是嚴格、靜態的表中——但是他們可以享受到具備完全的事務特性、企業級的資料庫的所有好處。
由於使用了“面向網路的資料庫”,人們對Neo充滿了好奇。在該模型中,以“節點空間”來表達領域資料——相對於傳統的模型表、行和列來說,節點空間是很多節點、關係和屬性(鍵值對)構成的網路。關係是第一級物件,可以由屬性來註解,而屬性則表明了節點互動的上下文。網路模型完美的匹配了本質上就是繼承關係的問題域,例如語義Web應用。Neo的建立者發現繼承和結構化資料並不適合傳統的關係資料庫模型:
1.物件關係的不匹配使得把面向物件的“圓的物件”擠到面向關係的“方的表”中是那麼的困難和費勁,而這一切是可以避免的。
2.關係模型靜態、剛性、不靈活的本質使得改變schemas以滿足不斷變化的業務需求是非常困難的。由於同樣的原因,當開發小組想應用敏捷軟體開發時,資料庫經常拖後腿。
3.關係模型很不適合表達半結構化的資料——而業界的分析家和研究者都認為半結構化資料是資訊管理中的下一個重頭戲。
4.網路是一種非常高效的資料儲存結構。人腦是一個巨大的網路,全球資訊網也同樣構造成網狀,這些都不是巧合。關係模型可以表達面向網路的資料,但是在遍歷網路並抽取資訊的能力上關係模型是非常弱的。
雖然Neo是一個比較新的開源專案,但它已經在具有1億多個節點、關係和屬性的產品中得到了應用,並且能滿足企業的健壯性和效能的需求:
完全支援JTA和JTS、2PC分散式ACID事務、可配置的隔離級別和大規模、可測試的事務恢復。這些不僅僅是口頭上的承諾:Neo已經應用在高請求的24/7環境下超過3年了。它是成熟、健壯的,完全達到了部署的門檻。
特性
Neo4j是一個用Java實現、完全相容ACID的圖形資料庫。資料以一種針對圖形網路進行過優化的格式儲存在磁碟上。Neo4j的核心是一種極快的圖形引擎,具有資料庫產品期望的所有特性,如恢復、兩階段提交、符合XA等。
Neo4j既可作為無需任何管理開銷的內嵌資料庫使用;也可以作為單獨的伺服器使用,在這種使用場景下,它提供了廣泛使用的REST介面,能夠方便地整合到基於PHP、.NET和JavaScript的環境裡。但本文的重點主要在於討論Neo4j的直接使用。
Neo4j的典型資料特徵:
•資料結構不是必須的,甚至可以完全沒有,這可以簡化模式變更和延遲資料遷移。
•可以方便建模常見的複雜領域資料集,如CMS裡的訪問控制可被建模成細粒度的訪問控制表,類物件資料庫的用例、TripleStores以及其他例子。
•典型使用的領域如語義網和RDF、LinkedData、GIS、基因分析、社交網路資料建模、深度推薦演算法以及其他領域。
圍繞核心,Neo4j提供了一組可選的元件。其中有支援通過元模型構造圖形結構、SAIL - 一種SparQL相容的RDF TripleStore實現或一組公共圖形演算法的實現。
高效能?
要給出確切的效能基準資料很難,因為它們跟底層的硬體、使用的資料集和其他因素關聯很大。自適應規模的Neo4j無需任何額外的工作便可以處理包含數十億節點、關係和屬性的圖。它的讀效能可以很輕鬆地實現每毫秒(大約每秒1-2百萬遍歷步驟)遍歷2000關係,這完全是事務性的,每個執行緒都有熱快取。使用最短路徑計算,Neo4j在處理包含數千個節點的小型圖時,甚至比MySQL快1000倍,隨著圖規模的增加,差距也越來越大。
這其中的原因在於,在Neo4j裡,圖遍歷執行的速度是常數,跟圖的規模大小無關。不象在RDBMS裡常見的聯結操作那樣,這裡不涉及降低效能的集合操作。Neo4j以一種延遲風格遍歷圖 - 節點和關係只有在結果迭代器需要訪問它們的時候才會被遍歷並返回,對於大規模深度遍歷而言,這極大地提高了效能。
寫速度跟檔案系統的查詢時間和硬體有很大關係。Ext3檔案系統和SSD磁碟是不錯的組合,這會導致每秒大約100,000寫事務操作。
官方網站
15、BaseX
介紹
BaseX 是一個XML資料庫,用來儲存緊縮的XML資料,提供了高效的 XPath 和 XQuery 的實現,還包括一個前端操作介面。
特性
BaseX一個比較顯著地優點是有了GUI,介面中有查詢視窗,可採用XQuery查詢相關資料庫中的XML檔案;也有能夠動態展示xml檔案層次和節點關係的圖。但我感覺也就這點好處了,程式設計時和GUI無關了。
和Xindice相比,BaseX更能支援大型XML文件的儲存,而Xindice對大型xml沒有很好的支援,為管理中小型文件的集合而設計。
BaseX 是一個XML資料庫,用來儲存緊縮的XML資料,提供了高效的 XPath 和 XQuery 的實現,還包括一個前端操作介面。
官方網站
|
memcached是一套分散式的快取系統,當初是Danga Interactive為了LiveJournal所發展的,但目前被許多軟體(如MediaWiki)所使用。這是一套開放原始碼軟體,以BSD license授權釋出。 memcached缺乏認證以及安全管制,這代表應該將memcached伺服器放置在防火牆...更多memcached資訊
|