基於zookeeper的Spark高可用叢集配置
首先我們這裡配置的三臺機器的叢集 名稱分別為hadoop、hadoop1、hadoop2
首先是安裝Zookeeper:

(4)配置:進到conf目錄下,把zoo_sample.cfg修改成zoo.cfg(這一步是必須的,否則zookeeper不認識zoo_sample.cfg),並新增如下內容:
下面進行spark的配置dataDir=/usr/local/ZooKeeper/zookeeper/data
clientPort=2181
server.0=hadoop:2888:3888
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
(5)在Zookeeper/data目錄下建立myid檔案,並在裡面寫0
(6)把/usr/local/zookeeper/整個目錄複製到其他節點cd /usr/local/Zookeeper/zookeeper/dataecho 0>myid
(7)登入到hadoop1,hadoop2節點,修改myid檔案裡的值,分別將其修改為1,2
(8)在hadoop,hadoop1,hadoop2三個節點上分別啟動zookeepercd /usr/local/Zookeeper/zookeeper/data echo 1>myidcd /usr/local/Zookeeper/zookeeper/dataecho 2>myid
cd /usr/local/Zookeeper/zookeeper/ bin/zkServer.sh start(9)檢視程序進否啟動
通過程序檢視可以看出我們的zookeeper已經啟動 QuorumPeerMain就是zookeeper的程序

很多網上的教程是將這個spark-env.sh檔案分別複製到hadoop1,hadoop2機器上就直接去啟動spark了,但是後來發現這樣是不行的,這樣就不能在後面將備用的spark master註冊成功,還需要額外的一步修改.如果說以後準備將hadoop1註冊一個備用的master那麼在hadoop1中的spark-env.sh中應該將其中的(1)在名為hadoop的第一臺機器上進入spark的conf目錄配置spark-env.sh檔案,配置如下:
export JAVA_HOME=/usr/java/jdk1.8.0_66
export HADOOP_HOME=/usr/local/hadoop/hadoop
export SPARK_HOME=/usr/local/spark
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_JAR=/usr/local/spark/lib/spark-assembly-1.6.1-hadoop2.6.0.jar
export PATH=$SPARK_HOME/bin:$PATH
#export SPARK_MASTER_IP=hadoop
#export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop/etc/hadoop
export SPARK_LOG_DIR=/usr/local/spark/logs
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=192.168.*.*:2181,192.168.*.*:2181,192.168.*.*:2181 -Dspark.deploy.zookeeper.dir=/spark"spark-env.sh中的192.168.*.*:2181分別為名字為hadoop,hadoop1.hadoop2的地址,具體的地址根據自己的修改
#export SPARK_MASTER_IP=hadoop
修改為:
export SPARK_MASTER_IP=hadoop1
如果是想將hadoop2設定為備用master,同理講hadoop2中的spark-env.sh中的
#export SPARK_MASTER_IP=hadoop
修改為:
export SPARK_MASTER_IP=hadoop2
現在配置已經完成,那麼我們來啟動spark,在hadoop機器上進入spark的sbin目錄下:
spark叢集已經啟動,那麼我們進入web頁面去檢視一下:
接著在hadoop1上啟動一個備用的master:
在hadoop1機器上進入spark下的sbin目錄:
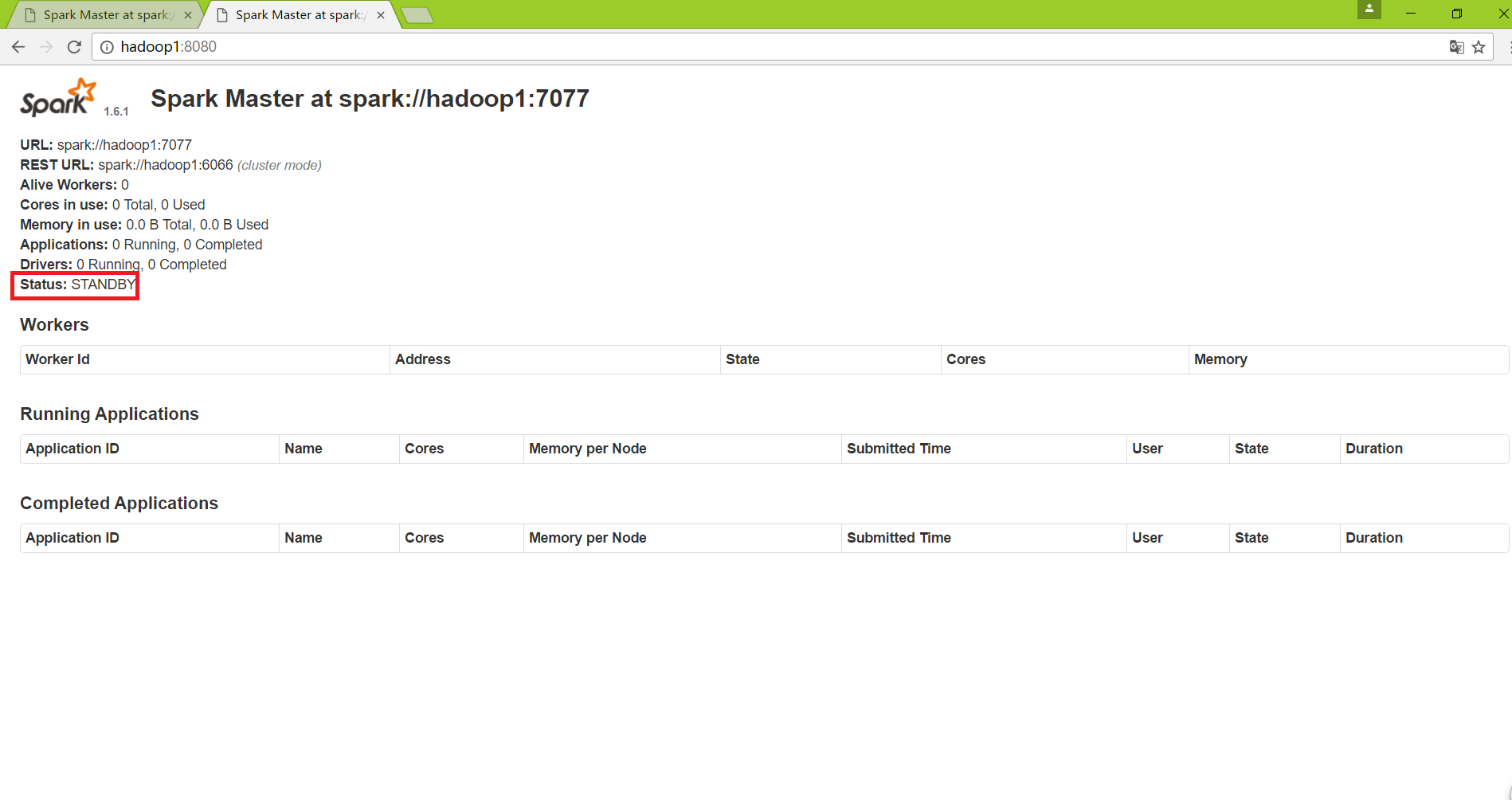
這樣備用的master已經啟動成功,進入web頁面檢視:
那麼整個的配置就已經完成了,下面通過停掉hadoop中的master,可以實現master的主備切換,在hadoop中去關閉master:
下面通過web埠檢視情況:
從上圖可以看出此時的hadoop上的master已經不能用了,接著來看看hadoop1的之前的備用master的web情況:
hadoop1中master從standby狀態變為了alive ,zookeeper已經實現了spark叢集的主備切換。
至此,整個spark叢集基於zookeeper的可自動實現主備切換的系統已經搭建完成!