
Windows下用Eclipse建立一個spark程式三步曲(Java版)
作者:翁鬆秀
用Eclipse建立一個spark程式三步曲(Java版)
在動手寫第一個spark程式之前,得具備以下條件
前提條件:
1. 已經安裝有Maven外掛的Eclipse,最新版的Eclipse Photon自帶Maven外掛。
2. 已經安裝Maven專案管理工具,要安裝的猛戳
3. 已經搭建spark的開發環境,要搭建的猛戳【Windows搭建spark開發環境】
Step1:建立Maven工程
【File】→【new】→【project…】,找到Maven節點,選擇Maven Project
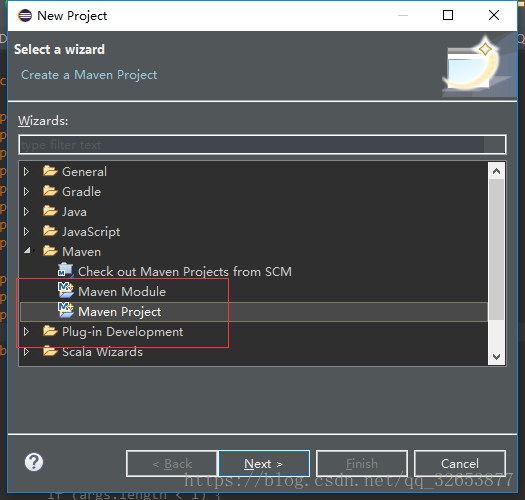
Next之後把”Create a simple project(skip archetype selection)“勾上,先建立一個簡單的工程,不用管那些花裡胡哨的,跑起來再說。
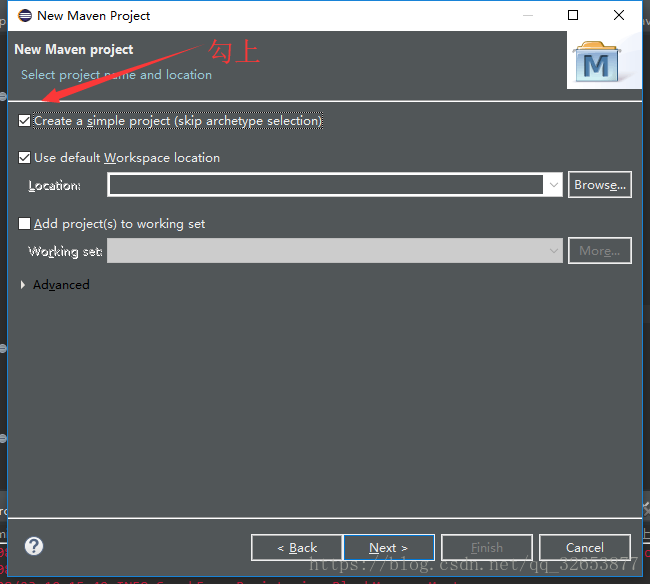
勾上之後Next,這裡需要填兩個Id,Group Id和Artifact Id,Group Id就是(域+公司),比如說Apache的Spark,Group Id是org.apache,Artifact Id是spark,這個是為了在maven中唯一標識一個Artifact採用的命名,不過你大可隨便填,我這裡Group Id就填org.apache,Artifact Id填spark。
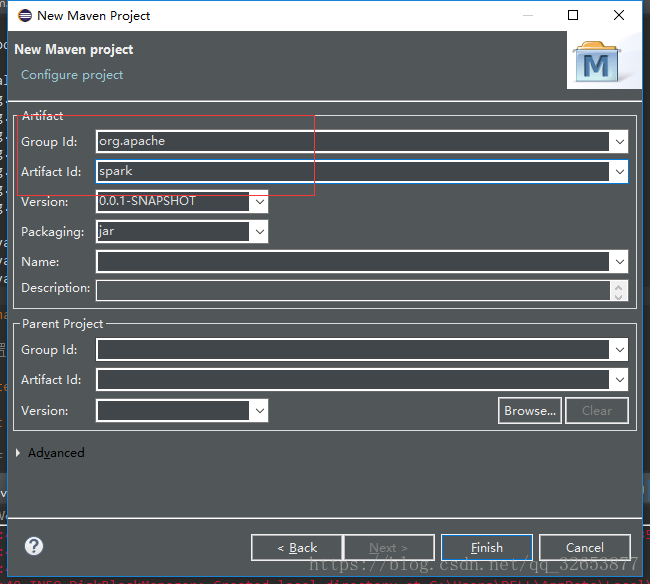
Step2:新增maven依賴
Finish之後我們的Maven工程就建好了,開啟工程目錄下的pom.xml配置檔案,載入spark程式所需要的一些依賴。
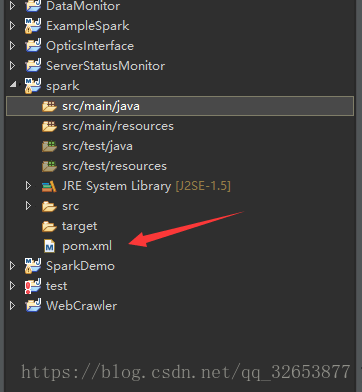
你的pom.xml檔案應該是這樣的,可能版本和Group Id和Artifact Id不同。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" 從下面的配置檔案中複製< version > < /version >以下的部分放到你的pom.xml< version > < /version >下面,或者複製整個檔案,到時候自己改一下
< modelVersion >,< groupId >,< artifactId >,< version >
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.apache</groupId>
<artifactId>spark</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- <localRepository>E:/mavenRepo</localRepository> -->
<repositories>
<repository>
<id>central</id>
<name>Central Repository</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
<layout>default</layout>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.2</version>
<configuration>
<archive>
<manifest>
<!-- 我執行這個jar所執行的主類 -->
<mainClass>code.demo.spark.JavaWordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>
<!-- 必須是這樣寫 -->
jar-with-dependencies
</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>1.6.0</spark.version>
<scala.version>2.10</scala.version>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.6.6</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.6</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>jaxen</groupId>
<artifactId>jaxen</artifactId>
<version>1.1.6</version>
</dependency>
<dependency>
<groupId>args4j</groupId>
<artifactId>args4j</artifactId>
<version>2.33</version>
</dependency>
<dependency>
<groupId>jline</groupId>
<artifactId>jline</artifactId>
<version>2.14.5</version>
</dependency>
</dependencies>
<artifactId>ExampleSpark</artifactId>
</project>編輯完成之後儲存,eclipse會自動載入所需要的依賴,時間可能有點久,取決於你的網速和maven的映象,如果maven是國內的阿里雲可能會比較快,maven搭建阿里雲映象猛戳【Maven搭建阿里雲映象】
Step3:編寫程式
載入完之後會在工程目錄下看到一個依賴Maven Dependencies
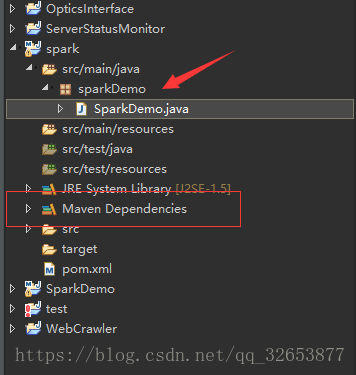
在src/main/java下建立sparkDemo包和SparkDemo.java,複製貼上下面的程式碼,這是官網計算π的example,為了簡單起見我把迭代引數去掉了,預設迭代10次。程式裡也設定執行的master為local,所以直接在本地的eclipse上執行即可。
package sparkDemo;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import java.util.ArrayList;
import java.util.List;
public final class SparkDemo {
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setAppName("JavaSparkPi").setMaster("local");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
long start = System.currentTimeMillis();
int slices = 10;
int n = 100000 * slices;
List<Integer> l = new ArrayList<Integer>(n);
for (int i = 0; i < n; i++) {
l.add(i);
}
/*
JavaSparkContext的parallelize:將一個集合變成一個RDD
- 第一個引數一是一個 Seq集合
- 第二個引數是分割槽數
- 返回的是RDD[T]
*/
JavaRDD<Integer> dataSet = jsc.parallelize(l, slices);
int count = dataSet.map(new Function<Integer, Integer>() {
private static final long serialVersionUID = 1L;
public Integer call(Integer integer) {
double x = Math.random() * 2 - 1;
double y = Math.random() * 2 - 1;
return (x * x + y * y < 1) ? 1 : 0;
}
}).reduce(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
public Integer call(Integer integer, Integer integer2) {
return integer + integer2;
}
});
long end = System.currentTimeMillis();
System.out.println("Pi is roughly " + 4.0 * count / n+",use : "+(end-start)+"ms");
jsc.stop();
jsc.close();
}
}
執行結果:
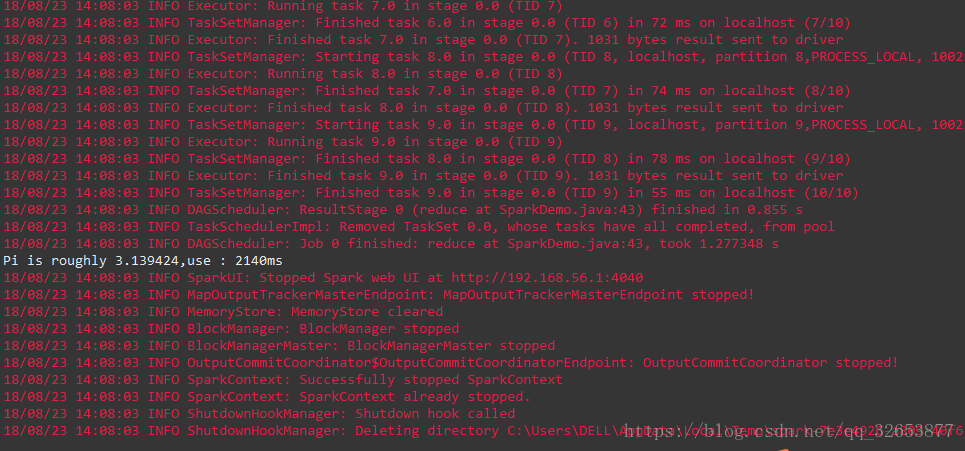
Welcome to Spark!