
Scala:Array(集合、序列)
Scala開篇(目錄)
陣列是一種可變的、可索引的資料集合。在Scala中用Array[T]的形式來表示Java中的陣列形式 T[]。
val numbers = Array(1, 2, 3, 4) //宣告一個數組物件
val first = numbers(0) // 讀取第一個元素
numbers(3) = 100 // 替換第四個元素為100
val biggerNumbers = numbers.map(_ * 2) // 所有元素乘2Scala提供了大量的集合操作:
- def ++[B](that: GenTraversableOnce[B]): Array[B]
合併集合,並返回一個新的陣列,新陣列包含左右兩個集合物件的內容。
val a = Array(1,2)
val b = Array(3,4)
val c = a ++ b
//c中的內容是(1,2,3,4)- def ++:[B >: A, That](that: collection.Traversable[B])(implicit bf: CanBuildFrom[Array[T], B, That]): That
這個方法同上一個方法類似,兩個加號後面多了一個冒號,但是不同的是右邊操縱數的型別決定著返回結果的型別。下面程式碼中List和LinkedList結合,返回結果是LinkedList型別
val a = List(1 - def +:(elem: A): Array[A]
在陣列前面新增一個元素,並返回新的物件,下面新增一個元素 0
val a = List(1,2)
val c = 0 +: a // c中的內容是 (0,1,2)def :+(elem: A): Array[A]
同上面的方法想法,在陣列末尾新增一個元素,並返回新物件def /:[B](z: B)(op: (B, T) ⇒ B): B
對陣列中所有的元素進行相同的操作 ,foldLeft的簡寫
val a = List(1,2,3,4)
val c = (10 /: a)(_+_) // 1+2+3+4+10
val d = (10 /: a)(_*_) // 1*2*3*4*10
println("c:"+c) // c:20
println("d:"+d) // d:240def :\[B](z: B)(op: (T, B) ⇒ B): B
foldRight的簡寫def addString(b: StringBuilder): StringBuilder
將陣列中的元素逐個新增到b中
val a = List(1,2,3,4)
val b = new StringBuilder()
val c = a.addString(b) // c中的內容是 1234- def addString(b: StringBuilder, sep: String): StringBuilder
同上,每個元素用sep分隔符分開
val a = List(1,2,3,4)
val b = new StringBuilder()
val c = a.addString(b,",")
println("c: "+c) // c: 1,2,3,4- def addString(b: StringBuilder, start: String, sep: String, end: String): StringBuilder
同上,在首尾各加一個字串,並指定sep分隔符
val a = List(1,2,3,4)
val b = new StringBuilder()
val c = a.addString(b,"{",",","}")
println("c: "+c) // c: {1,2,3,4}- def aggregate[B](z: ⇒ B)(seqop: (B, T) ⇒ B, combop: (B, B) ⇒ B): B
聚合計算,aggregate是柯里化方法,引數是兩個方法,為了方便理解,我們把aggregate的兩個引數,分別封裝成兩個方法,並把計算過程打印出來。
def main(args: Array[String]) {
val a = List(1,2,3,4)
val c = a.par.aggregate(5)(seqno,combine)
println("c:"+c)
}
def seqno(m:Int,n:Int): Int ={
val s = "seq_exp=%d+%d"
println(s.format(m,n))
return m+n
}
def combine(m:Int,n:Int): Int ={
val s = "com_exp=%d+%d"
println(s.format(m,n))
return m+n
}
/**
seq_exp=5+3
seq_exp=5+2
seq_exp=5+4
seq_exp=5+1
com_exp=6+7
com_exp=8+9
com_exp=13+17
c:30
*/上面過程可以簡寫為
val c = a.par.aggregate(5)(_+_,_+_)- def apply(i: Int): T
同下面程式碼,取出指定索引處的元素
val first = numbers(0) // 讀取第一個元素def canEqual(that: Any): Boolean
判斷兩個物件是否可以進行比較def charAt(index: Int): Char
獲取index索引處的字元,這個方法會執行一個隱式的轉換,將Array[T]轉換為 ArrayCharSequence,只有當T為char型別時,這個轉換才會發生。
val chars = Array('a','b','c')
println("c:"+chars.charAt(0)) //結果 a- def clone(): Array[T]
建立一個副本
val chars = Array('a','b','c')
println(a.apply(2))
val newchars = chars.clone()- def collect[B](pf: PartialFunction[A, B]): Array[B]
通過執行一個平行計算(偏函式),得到一個新的陣列物件
val chars = Array('a','b','c')
val newchars = chars.collect(fun)
println("newchars:"+newchars.mkString(","))
//我們通過下面的偏函式,把chars陣列的小寫a轉換為大寫的A
val fun:PartialFunction[Char,Char] = {
case 'a' => 'A'
case x => x
}
/**輸出結果是 newchars:A,b,c */- def collectFirst[B](pf: PartialFunction[T, B]): Option[B]
在序列中查詢第一個符合偏函式定義的元素,並執行偏函式計算
val arr = Array(1,'a',"b")
//定義一個偏函式,要求當被執行物件為Int型別時,進行乘100的操作,對於上面定義的物件arr來說,只有第一個元素符合要求
val fun:PartialFunction[Any,Int] = {
case x:Int => x*100
}
//計算
val value = arr.collectFirst(fun)
println("value:"+value)
//另一種寫法
val value = arr.collectFirst({case x:Int => x*100})- def combinations(n: Int): collection.Iterator[Array[T]]
排列組合,這個排列組合會選出所有包含字元不一樣的組合,對於 “abc”、“cba”,只選擇一個,引數n表示序列長度,就是幾個字元為一組
val arr = Array("a","b","c")
val newarr = arr.combinations(2)
newarr.foreach((item) => println(item.mkString(",")))
/**
a,b
a,c
b,c
*/def contains[A1 >: A](elem: A1): Boolean
序列中是否包含指定物件def containsSlice[B](that: GenSeq[B]): Boolean
判斷當前序列中是否包含另一個序列
val a = List(1,2,3,4)
val b = List(2,3)
println(a.containsSlice(b)) //true- def copyToArray(xs: Array[A]): Unit
此方法還有兩個類似的方法
copyToArray(xs: Array[A], start: Int): Unit
copyToArray(xs: Array[A], start: Int, len: Int): Unit
val a = Array('a', 'b', 'c')
val b : Array[Char] = new Array(5)
a.copyToArray(b) /**b中元素 ['a','b','c',0,0]*/
a.copyToArray(b,1) /**b中元素 [0,'a',0,0,0]*/
a.copyToArray(b,1,2) /**b中元素 [0,'a','b',0,0]*/- def copyToBuffer[B >: A](dest: Buffer[B]): Unit
將陣列中的內容拷貝到Buffer中
val a = Array('a', 'b', 'c')
val b:ArrayBuffer[Char] = ArrayBuffer()
a.copyToBuffer(b)
println(b.mkString(","))- def corresponds[B](that: GenSeq[B])(p: (T, B) ⇒ Boolean): Boolean
判斷兩個序列長度以及對應位置元素是否符合某個條件。如果兩個序列具有相同的元素數量並且p(x, y)=true,返回結果為true
下面程式碼檢查a和b長度是否相等,並且a中元素是否小於b中對應位置的元素
val a = Array(1, 2, 3)
val b = Array(4, 5,6)
println(a.corresponds(b)(_<_)) //true- def count(p: (T) ⇒ Boolean): Int
統計符合條件的元素個數,下面統計大於 2 的元素個數
val a = Array(1, 2, 3)
println(a.count({x:Int => x > 2})) // count = 1- def diff(that: collection.Seq[T]): Array[T]
計算當前陣列與另一個數組的不同。將當前陣列中沒有在另一個數組中出現的元素返回
val a = Array(1, 2, 3,4)
val b = Array(4, 5,6,7)
val c = a.diff(b)
println(c.mkString) //1,2,3- def distinct: Array[T]
去除當前集合中重複的元素,只保留一個
val a = Array(1, 2, 3,4,4,5,6,6)
val c = a.distinct
println(c.mkString(",")) // 1,2,3,4,5,6- def drop(n: Int): Array[T]
將當前序列中前 n 個元素去除後,作為一個新序列返回
val a = Array(1, 2, 3,4)
val c = a.drop(2)
println(c.mkString(",")) // 3,4- def dropRight(n: Int): Array[T]
功能同 drop,去掉尾部的 n 個元素
def dropWhile(p: (T) ⇒ Boolean): Array[T]
去除當前陣列中符合條件的元素,這個需要一個條件,就是從當前陣列的第一個元素起,就要滿足條件,直到碰到第一個不滿足條件的元素結束(即使後面還有符合條件的元素),否則返回整個陣列
//下面去除大於2的,第一個元素 3 滿足,它後面的元素 2 不滿足,所以返回 2,3,4
val a = Array(3, 2, 3,4)
val c = a.dropWhile( {x:Int => x > 2} )
println(c.mkString(","))
//如果陣列 a 是下面這樣,第一個元素就不滿足,所以返回整個陣列 1, 2, 3,4
val a = Array(1, 2, 3,4) - def endsWith[B](that: GenSeq[B]): Boolean
判斷是否以某個序列結尾
val a = Array(3, 2, 3,4)
val b = Array(3,4)
println(a.endsWith(b)) //true- def exists(p: (T) ⇒ Boolean): Boolean
判斷當前陣列是否包含符合條件的元素
val a = Array(3, 2, 3,4)
println(a.exists( {x:Int => x==3} )) //true
println(a.exists( {x:Int => x==30} )) //false- def filter(p: (T) ⇒ Boolean): Array[T]
取得當前陣列中符合條件的元素,組成新的陣列返回
val a = Array(3, 2, 3,4)
val b = a.filter( {x:Int => x> 2} )
println(b.mkString(",")) //3,3,4def filterNot(p: (T) ⇒ Boolean): Array[T]
與上面的 filter 作用相反def find(p: (T) ⇒ Boolean): Option[T]
查詢第一個符合條件的元素
val a = Array(1, 2, 3,4)
val b = a.find( {x:Int => x>2} )
println(b) // Some(3)- def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): Array[B]
對當前序列的每個元素進行操作,結果放入新序列返回,引數要求是GenTraversableOnce及其子類
val a = Array(1, 2, 3,4)
val b = a.flatMap(x=>1 to x)
println(b.mkString(","))
/**
1,1,2,1,2,3,1,2,3,4
從1開始,分別於集合a的每個元素生成一個遞增序列,過程如下
1
1,2
1,2,3
1,2,3,4
*/- def flatten[U](implicit asTrav: (T) ⇒ collection.Traversable[U], m: ClassTag[U]): Array[U]
將二維陣列的所有元素聯合在一起,形成一個一維陣列返回
val dArr = Array(Array(1,2,3),Array(4,5,6))
val c = dArr.flatten
println(c.mkString(",")) //1,2,3,4,5,6-def fold[A1 >: A](z: A1)(op: (A1, A1) ⇒ A1): A1
對序列中的每個元素進行二元運算,和aggregate有類似的語義,但執行過程有所不同,我們來對比一下他們的執行過程。
因為aggregate需要兩個處理方法,所以我們定義一個combine方法
def seqno(m:Int,n:Int): Int ={
val s = "seq_exp=%d+%d"
println(s.format(m,n))
return m+n
}
def combine(m:Int,n:Int): Int ={
val s = "com_exp=%d+%d"
println(s.format(m,n))
return m+n
}
val a = Array(1, 2, 3,4)
val b = a.fold(5)(seqno)
/** 運算過程
seq_exp=5+1
seq_exp=6+2
seq_exp=8+3
seq_exp=11+4
*/
val c = a.par.aggregate(5)(seqno,combine)
/** 運算過程
seq_exp=5+1
seq_exp=5+4
seq_exp=5+3
com_exp=8+9
seq_exp=5+2
com_exp=6+7
com_exp=13+17
*/
看上面的運算過程發現,fold中,seqno是把初始值順序和每個元素相加,把得到的結果與下一個元素進行運算
而aggregate中,seqno是把初始值與每個元素相加,但結果不參與下一步運算,而是放到另一個序列中,由第二個方法combine進行處理
-def foldLeft[B](z: B)(op: (B, T) ⇒ B): B
從左到右計算,簡寫方式:def /:[B](z: B)(op: (B, T) ⇒ B): B
def seqno(m:Int,n:Int): Int ={
val s = "seq_exp=%d+%d"
println(s.format(m,n))
return m+n
}
val a = Array(1, 2, 3,4)
val b = a.foldLeft(5)(seqno)
/** 運算過程
seq_exp=5+1
seq_exp=6+2
seq_exp=8+3
seq_exp=11+4
*/
/**
簡寫 (5 /: a)(_+_)
*/-def foldRight[B](z: B)(op: (B, T) ⇒ B): B
從右到左計算,簡寫方式:def :\[B](z: B)(op: (T, B) ⇒ B): B
def seqno(m:Int,n:Int): Int ={
val s = "seq_exp=%d+%d"
println(s.format(m,n))
return m+n
}
val a = Array(1, 2, 3,4)
val b = a.foldRight(5)(seqno)
/** 運算過程
seq_exp=4+5
seq_exp=3+9
seq_exp=2+12
seq_exp=1+14
*/
/**
簡寫 (a :\ 5)(_+_)
*/-def forall(p: (T) ⇒ Boolean): Boolean
檢測序列中的元素是否都滿足條件 p,如果序列為空,返回true
val a = Array(1, 2, 3,4)
val b = a.forall( {x:Int => x>0}) //true
val b = a.forall( {x:Int => x>2}) //false-def foreach(f: (A) ⇒ Unit): Unit
檢測序列中的元素是否都滿足條件 p,如果序列為空,返回true
val a = Array(1, 2, 3,4)
val b = a.forall( {x:Int => x>0}) //true
val b = a.forall( {x:Int => x>2}) //false-def foreach(f: (A) ⇒ Unit): Unit
遍歷序列中的元素,進行 f 操作
val a = Array(1, 2, 3,4)
a.foreach(x => println(x*10))
/**
10
20
30
40
*/-def groupBy[K](f: (T) ⇒ K): Map[K, Array[T]]
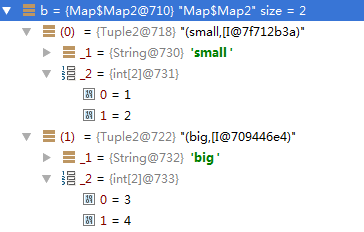
按條件分組,條件由 f 匹配,返回值是Map型別,每個key對應一個序列,下面程式碼實現的是,把小於3的數字放到一組,大於3的放到一組,返回Map[String,Array[Int]]
val a = Array(1, 2, 3,4)
val b = a.groupBy( x => x match {
case x if (x < 3) => "small"
case _ => "big"
})
-def grouped(size: Int): collection.Iterator[Array[T]]
按指定數量分組,每組有 size 數量個元素,返回一個集合
val a = Array(1, 2, 3,4,5)
val b = a.grouped(3).toList
b.foreach((x) => println("第"+(b.indexOf(x)+1)+"組:"+x.mkString(",")))
/**
第1組:1,2,3
第2組:4,5
*/-def hasDefiniteSize: Boolean
檢測序列是否存在有限的長度,對應Stream這樣的流資料,返回false
val a = Array(1, 2, 3,4,5)
println(a.hasDefiniteSize) //true-def head: T
返回序列的第一個元素,如果序列為空,將引發錯誤
val a = Array(1, 2, 3,4,5)
println(a.head) //1-def headOption: Option[T]
返回Option型別物件,就是scala.Some 或者 None,如果序列是空,返回None
val a = Array(1, 2, 3,4,5)
println(a.headOption) //Some(1)-def indexOf(elem: T): Int
返回elem在序列中的索引,找到第一個就返回
val a = Array(1, 3, 2, 3, 4)
println(a.indexOf(3)) // return 1-def indexOf(elem: T, from: Int): Int
返回elem在序列中的索引,可以指定從某個索引處(from)開始查詢,找到第一個就返回
val a = Array(1, 3, 2, 3, 4)
println(a.indexOf(3,2)) // return 3-def indexOfSlice[B >: A](that: GenSeq[B]): Int
檢測當前序列中是否包含另一個序列(that),並返回第一個匹配出現的元素的索引
val a = Array(1, 3, 2, 3, 4)
val b = Array(2,3)
println(a.indexOfSlice(b)) // return 2-def indexOfSlice[B >: A](that: GenSeq[B], from: Int): Int
檢測當前序列中是否包含另一個序列(that),並返回第一個匹配出現的元素的索引,指定從 from 索引處開始
val a = Array(1, 3, 2, 3, 2, 3, 4)
val b = Array(2,3)
println(a.indexOfSlice(b,3)) // return 4-def indexWhere(p: (T) ⇒ Boolean): Int
返回當前序列中第一個滿足 p 條件的元素的索引
val a = Array(1, 2, 3, 4)
println(a.indexWhere( {x:Int => x>3})) // return 3-def indexWhere(p: (T) ⇒ Boolean, from: Int): Int
返回當前序列中第一個滿足 p 條件的元素的索引,可以指定從 from 索引處開始
val a = Array(1, 2, 3, 4, 5, 6)
println(a.indexWhere( {x:Int => x>3},4)) // return 4-def indices: collection.immutable.Range
返回當前序列索引集合
val a = Array(10, 2, 3, 40, 5)
val b = a.indices
println(b.mkString(",")) // 0,1,2,3,4-def init: Array[T]
返回當前序列中不包含最後一個元素的序列
val a = Array(10, 2, 3, 40, 5)
val b = a.init
println(b.mkString(",")) // 10, 2, 3, 40-def inits: collection.Iterator[Array[T]]
對集合中的元素進行 init 操作,該操作的返回值中, 第一個值是當前序列的副本,包含當前序列所有的元素,最後一個值是空的,對頭尾之間的值進行init操作,上一步的結果作為下一步的操作物件
val a = Array(1, 2, 3, 4, 5)
val b = a.inits.toList
for(i <- 1 to b.length){
val s = "第%d個值:%s"
println(s.format(i,b(i-1).mkString(",")))
}
/**計算結果
第1個值:1,2,3,4,5
第2個值:1,2,3,4
第3個值:1,2,3
第4個值:1,2
第5個值:1
第6個值
*/-def intersect(that: collection.Seq[T]): Array[T]
取兩個集合的交集
val a = Array(1, 2, 3, 4, 5)
val b = Array(3, 4, 6)
val c = a.intersect(b)
println(c.mkString(",")) //return 3,4-def isDefinedAt(idx: Int): Boolean
判斷序列中是否存在指定索引
val a = Array(1, 2, 3, 4, 5)
println(a.isDefinedAt(1)) // true
println(a.isDefinedAt(10)) // false-def isEmpty: Boolean
判斷當前序列是否為空
-def isTraversableAgain: Boolean
判斷序列是否可以反覆遍歷,該方法是GenTraversableOnce中的方法,對於 Traversables 一般返回true,對於 Iterators 返回 false,除非被複寫
-def iterator: collection.Iterator[T]
對序列中的每個元素產生一個 iterator
val a = Array(1, 2, 3, 4, 5)
val b = a.iterator //此時就可以通過迭代器訪問 b-def last: T
取得序列中最後一個元素
val a = Array(1, 2, 3, 4, 5)
println(a.last) // return 5-def lastIndexOf(elem: T): Int
取得序列中最後一個等於 elem 的元素的位置
val a = Array(1, 4, 2, 3, 4, 5)
println(a.lastIndexOf(4)) // return 4-def lastIndexOf(elem: T, end: Int): Int
取得序列中最後一個等於 elem 的元素的位置,可以指定在 end 之前(包括)的元素中查詢
val a = Array(1, 4, 2, 3, 4, 5)
println(a.lastIndexOf(4,3)) // return 1-def lastIndexOfSlice[B >: A](that: GenSeq[B]): Int
判斷當前序列中是否包含序列 that,並返回最後一次出現該序列的位置處的索引
val a = Array(1, 4, 2, 3, 4, 5, 1, 4)
val b = Array(1, 4)
println(a.lastIndexOfSlice(b)) // return 6-def lastIndexOfSlice[B >: A](that: GenSeq[B], end: Int): Int
判斷當前序列中是否包含序列 that,並返回最後一次出現該序列的位置處的索引,可以指定在 end 之前(包括)的元素中查詢
val a = Array(1, 4, 2, 3, 4, 5, 1, 4)
val b = Array(1, 4)
println(a.lastIndexOfSlice(b,4)) // return 0-def lastIndexWhere(p: (T) ⇒ Boolean): Int
返回當前序列中最後一個滿足條件 p 的元素的索引
val a = Array(1, 4, 2, 3, 4, 5, 1, 4)
val b = Array(1, 4)
println(a.lastIndexWhere( {x:Int => x<2})) // return 6-def lastIndexWhere(p: (T) ⇒ Boolean, end: Int): Int
返回當前序列中最後一個滿足條件 p 的元素的索引,可以指定在 end 之前(包括)的元素中查詢
val a = Array(1, 4, 2, 3, 4, 5, 1, 4)
val b = Array(1, 4)
println(a.lastIndexWhere( {x:Int => x<2},2)) // return 0-def lastOption: Option[T]
返回當前序列中最後一個物件
val a = Array(1, 2, 3, 4, 5)
println(a.lastOption) // return Some(5)-def length: Int
返回當前序列中元素個數
val a = Array(1, 2, 3, 4, 5)
println(a.length) // return 5-def lengthCompare(len: Int): Int
比較序列的長度和引數 len,根據二者的關係返回不同的值,比較規則是
x < 0 if this.length < len
x == 0 if this.length == len
x > 0 if this.length > len-def map[B](f: (A) ⇒ B): Array[B]
對序列中的元素進行 f 操作
val a = Array(1, 2, 3, 4, 5)
val b = a.map( {x:Int => x*10})
println(b.mkString(",")) // 10,20,30,40,50-def max: A
返回序列中最大的元素
val a = Array(1, 2, 3, 4, 5)
println(a.max) // return 5-def minBy[B](f: (A) ⇒ B): A
返回序列中第一個符合條件的最大的元素
val a = Array(1, 2, 3, 4, 5)
println(a.maxBy( {x:Int => x > 2})) // return 3-def mkString: String
將所有元素組合成一個字串
val a = Array(1, 2, 3, 4, 5)
println(a.mkString) // return 12345-def mkString(sep: String): String
將所有元素組合成一個字串,以 sep 作為元素間的分隔符
val a = Array(1, 2, 3, 4, 5)
println(a.mkString(",")) // return 1,2,3,4,5-def mkString(start: String, sep: String, end: String): String
將所有元素組合成一個字串,以 start 開頭,以 sep 作為元素間的分隔符,以 end 結尾
val a = Array(1, 2, 3, 4, 5)
println(a.mkString("{",",","}")) // return {1,2,3,4,5}-def nonEmpty: Boolean
判斷序列不是空
-def padTo(len: Int, elem: A): Array[A]
後補齊序列,如果當前序列長度小於 len,那麼新產生的序列長度是 len,多出的幾個位值填充 elem,如果當前序列大於等於 len ,則返回當前序列
val a = Array(1, 2, 3, 4, 5)
val b = a.padTo(7,9) //需要一個長度為 7 的新序列,空出的填充 9
println(b.mkString(",")) // return 1,2,3,4,5,9,9-def par: ParArray[T]
返回一個並行實現,產生的並行序列,不能被修改
val a = Array(1, 2, 3, 4, 5)
val b = a.par // "ParArray" size = 5-def partition(p: (T) ⇒ Boolean): (Array[T], Array[T])
按條件將序列拆分成兩個新的序列,滿足條件的放到第一個序列中,其餘的放到第二個序列,下面以序列元素是否是 2 的倍數來拆分
val a = Array(1, 2, 3, 4, 5)
val b:(Array[Int],Array[Int]) = a.partition( {x:Int => x % 2 == 0})
println(b._1.mkString(",")) // return 2,4
println(b._2.mkString(",")) // return 1,3,5-def patch(from: Int, that: GenSeq[A], replaced: Int): Array[A]
批量替換,從原序列的 from 處開始,後面的 replaced 數量個元素,將被替換成序列 that
val a = Array(1, 2, 3, 4, 5)
val b = Array(3, 4, 6)
val c = a.patch(1,b,2)
println(c.mkString(",")) // return 1,3,4,6,4,5
/**從 a 的第二個元素開始,取兩個元素,即 2和3 ,這兩個元素被替換為 b的內容*/-def permutations: collection.Iterator[Array[T]]
排列組合,他與combinations不同的是,組合中的內容可以相同,但是順序不能相同,combinations不允許包含的內容相同,即使順序不一樣
val a = Array(1, 2, 3, 4, 5)
val b = a.permutations.toList // b 中將有120個結果,知道排列組合公式的,應該不難理解吧
/**如果是combinations*/
val b = a.combinations(5).toList // b 中只有一個,因為不管怎樣排列,都是這5個數字組成,所以只能保留第一個-def prefixLength(p: (T) ⇒ Boolean): Int
給定一個條件 p,返回一個前置數列的長度,這個數列中的元素都滿足 p
val a = Array(1,2,3,4,1,2,3,4)
val b = a.prefixLength( {x:Int => x<3}) // b = 2-def product: A
返回所有元素乘積的值
val a = Array(1,2,3,4,5)
val b = a.product // b = 120 (1*2*3*4*5)-def reduce[A1 >: A](op: (A1, A1) ⇒ A1): A1
同 fold,不需要初始值
val fun:PartialFunction[Any,Int] = {
case 'a' => 'A'
case x:Int => x*100
}
val a = Array(1,2,3,4,5)
val b = a.reduce(seqno)
println(b) // 15
/**
seq_exp=1+2
seq_exp=3+3
seq_exp=6+4
seq_exp=10+5
*/
-def reduceLeft[B >: A](op: (B, T) ⇒ B): B
從左向右計算
-def reduceRight[B >: A](op: (T, B) ⇒ B): B
從右向左計算
-def reduceLeftOption[B >: A](op: (B, T) ⇒ B): Option[B]
計算Option,參考reduceLeft
-def reduceRightOption[B >: A](op: (T, B) ⇒ B): Option[B]
計算Option,參考reduceRight
-def reverse: Array[T]
反轉序列
val a = Array(1,2,3,4,5)
val b = a.reverse
println(b.mkString(",")) //5,4,3,2,1-def reverseIterator: collection.Iterator[T]
反向生成迭代
-def reverseMap[B](f: (A) ⇒ B): Array[B]
同 map 方向相反
val a = Array(1,2,3,4,5)
val b = a.reverseMap( {x:Int => x*10} )
println(b.mkString(",")) // 50,40,30,20,10-def sameElements(that: GenIterable[A]): Boolean
判斷兩個序列是否順序和對應位置上的元素都一樣
val a = Array(1,2,3,4,5)
val b = Array(1,2,3,4,5)
println(a.sameElements(b)) // true
val c = Array(1,2,3,5,4)
println(a.sameElements(c)) // false-def scan[B >: A, That](z: B)(op: (B, B) ⇒ B)(implicit cbf: CanBuildFrom[Array[T], B, That]): That
用法同 fold,scan會把每一步的計算結果放到一個新的集合中返回,而 fold 返回的是單一的值
val a = Array(1,2,3,4,5)
val b = a.scan(5)(seqno)
println(b.mkString(",")) // 5,6,8,11,15,20-def scanLeft[B, That](z: B)(op: (B, T) ⇒ B)(implicit bf: CanBuildFrom[Array[T], B, That]): That
從左向右計算
-def scanRight[B, That](z: B)(op: (T, B) ⇒ B)(implicit bf: CanBuildFrom[Array[T], B, That]): That
從右向左計算
-def segmentLength(p: (T) ⇒ Boolean, from: Int): Int
從序列的 from 處開始向後查詢,所有滿足 p 的連續元素的長度
val a = Array(1,2,3,1,1,1,1,1,4,5)
val b = a.segmentLength( {x:Int => x < 3},3) // 5-def seq: collection.mutable.IndexedSeq[T]
產生一個引用當前序列的 sequential 檢視
-def size: Int
序列元素個數,同 length
-def slice(from: Int, until: Int): Array[T]
取出當前序列中,from 到 until 之間的片段
val a = Array(1,2,3,4,5)
val b = a.slice(1,3)
println(b.mkString(",")) // 2,3-def sliding(size: Int): collection.Iterator[Array[T]]
從第一個元素開始,每個元素和它後面的 size - 1 個元素組成一個數組,最終組成一個新的集合返回,當剩餘元素不夠 size 數,則停止
val a = Array(1,2,
相關推薦
Scala:Array(集合、序列)
Scala開篇(目錄)
陣列是一種可變的、可索引的資料集合。在Scala中用Array[T]的形式來表示Java中的陣列形式 T[]。
val numbers = Array(1, 2, 3, 4) //宣告一個數組物件
val first = numb
Extjs5.0(6):控制器(Controller、ViewController)和路由器(Router)
控制器
上一篇文章我們已經為專案添加了左側導航欄,接下來要為導航欄新增點選事件,點選左側導航欄,右側介面出現相應變化。
為元件新增事件,就要用到控制器了。Extjs5提供了兩種控制器:Controller和ViewController,這兩種控制器都繼承自BaseCon
Jenkins上下游jobs設定(並行、序列)
使用jenkins中,當有多個jobs需要互相關聯時,就需要設定jobs的上下游關聯關係。比如job_A執行後觸發job_B。
1.Build after other projects are bu
Spark核心程式設計:建立RDD(集合、本地檔案、HDFS檔案)
1,建立RDD
1.進行Spark核心程式設計時,首先要做的第一件事,就是建立一個初始的RDD。該RDD中,通常就代表和包含了Spark應用程式的輸入源資料。然後在建立了初始的RDD之後,才可以通過Spark Core提供的transformation運算元,
java進階(三):反射(3)——陣列的反射與集合的運用(ArrayList、HashSet)
一、陣列的反射
1、簡單的陣列反射:
1)同樣型別切且具有相同維度的陣列擁有同一份位元組碼
/*
* 5- 陣列的的反射
*/
int[] a1 = new int[3];
int[] a2 = new int[4];
int[][] a3 =
面試:在面試中關於List(ArrayList、LinkedList)集合會怎麼問呢?你該如何回答呢?
前言
在一開始基礎面的時候,很多面試官可能會問List集合一些基礎知識,比如:
ArrayList預設大小是多少,是如何擴容的?
ArrayList和LinkedList的底層資料結構是什麼?
ArrayList和LinkedList的區別?分別用在什麼場景?
為什麼說ArrayList查詢快
筆記:XML-解析文檔-流機制解析器(SAX、StAX)
輸入 tex 字符數 表示 getname 重要 樹形 puts ron DOM
解析器完整的讀入XML文檔,然後將其轉換成一個樹型的數據結構,對於大多數應用,DOM 都運行很好,但是,如果文檔很大,並且處理算法又非常簡單,可以在運行時解析節點,而不必看到完整的樹形
Linux時間子系統之八:動態時鐘框架(CONFIG_NO_HZ、tickless)
sleep file rup linux時間 load 曾經 大致 獲取 conf 在前面章節的討論中,我們一直基於一個假設:Linux中的時鐘事件都是由一個周期時鐘提供,不管系統中的clock_event_device是工作於周期觸發模式,還是工作於單觸發模式,也不管定時
Linux內核project導論——網絡:Filter(LSF、BPF、eBPF)
linux內核 空間使用 自己 ket iat cls number 那種 機制
概覽
LSF(Linux socket filter)起源於BPF(Berkeley Packet Filter)。基礎從架構一致。但使用更簡單。LSF內部的BP
Day50:CSS屬性(float、position)
定位 alt 變化 white 覆蓋問題 ecc wid 寬度 epp 一、float屬性
1、基本屬性
先來了解一下block元素和inline元素在文檔流中的排列方式。
block元素通常被現實為獨立的一塊,獨占一行,多個block元素會各自新起一行,默認block
集合(List、Set)
特性 完成 index cas ren mil public 決定 void 第19天 集合
第1章 List接口
我們掌握了Collection接口的使用後,再來看看Collection接口中的子類,他們都具備那些特性呢?
接下來,我們一起學習Collection中的常用
springMVC怎麽接受前臺傳過來的多種類型參數?(集合、實體、單個參數)
pat con getc get gpo catalog pwd list集合 success 創建一個實體:裏面包含需要接受的多種類型的參數。如實體、list集合、單個參數。(因為springMVC無法同時接受這幾種參數,需要創建一個實體包含它們來接受)
如接收User(
構建微服務架構Spring Cloud:服務註冊與發現(Eureka、Consul)
comm 簡介 foundry 架構 eas args 包含 什麽 其他 Spring Cloud簡介
Spring Cloud是一個基於Spring Boot實現的雲應用開發工具,它為基於JVM的雲應用開發中涉及的配置管理、服務發現、斷路器、智能路由、微代理、控制總線、全
POJ-3275:Ranking the Cows(Floyd、bitset)
accep lines ... std between farmer 轉折點 using 多少 Ranking the Cows
Time Limit: 2000MS
Memory Limit: 65536K
Total Submissions: 3301
19_集合_第19天(List、Set)_講義
錯誤 equal 異常 UNC 規則 加載 ofb jpg ret
今日內容介紹
1、List接口
2、Set接口
3、判斷集合唯一性原理
非常重要的關系圖
xmind下載地址
鏈接:https://pan.baidu.com/s/1kx0XabmT27pt4Ll9A
Spring Boot + Spring Cloud 實現許可權管理系統 後端篇(十九):服務消費(Ribbon、Feign)
技術背景
上一篇教程中,我們利用Consul註冊中心,實現了服務的註冊和發現功能,這一篇我們來聊聊服務的呼叫。單體應用中,程式碼可以直接依賴,在程式碼中直接呼叫即可,但在微服務架構是分散式架構,服務都執行在各自的程序之中,甚至部署在不同的主機和不同的地區。這個時候就需要相關的遠端呼叫技術了。
Spring
Spring Boot + Spring Cloud 實現許可權管理系統 後端篇(二十):服務熔斷(Hystrix、Turbine)
線上演示
演示地址:http://139.196.87.48:9002/kitty
使用者名稱:admin 密碼:admin
雪崩效應
在微服務架構中,由於服務眾多,通常會涉及多個服務層級的呼叫,而一旦基礎服務發生故障,很可能會導致級聯故障,進而造成整個系統不可用,這種現象被稱為服務雪崩效應。服務雪崩
Spring Boot + Spring Cloud 實現許可權管理系統 後端篇(二十二):鏈路追蹤(Sleuth、Zipkin)
線上演示
演示地址:http://139.196.87.48:9002/kitty
使用者名稱:admin 密碼:admin
技術背景
在微服務架構中,隨著業務發展,系統拆分導致系統呼叫鏈路愈發複雜,一個看似簡單的前端請求可能最終需要呼叫很多次後端服務才能完成,那麼當整個請求出現問題時,我們很難得知到
大資料(十三):MapJoin(DistributedCache分散式快取)、資料清理例項與計數器應用
一、在map端表合併(DistributedCache分散式快取)
1.適用場景
適合用於關聯表中有小表的情形。
可以將小表分發到所有的
python學習第六天:python基礎(dict、set)
dict
dict的支援,dict全稱dictionary,在其他語言中也稱為map,使用鍵-值(key-value)儲存,具有極快的查詢速度
建立&取值
為什麼dict查詢速度這麼快?
因為dict的實現原理和查字典是