
dubbo+zookeeper構建高可用分散式叢集
我們討論過Nginx+tomcat組成的叢集,這已經是非常靈活的叢集技術,但是當我們的系統遇到更大的瓶頸,全部應用的單點伺服器已經不能滿足我們的需求,這時,我們要考慮另外一種,我們熟悉的內容,就是分散式,而當下流行的Dubbo框架。
一,背景
以前我們需要遠端呼叫他人的介面,我們是這麼做的:
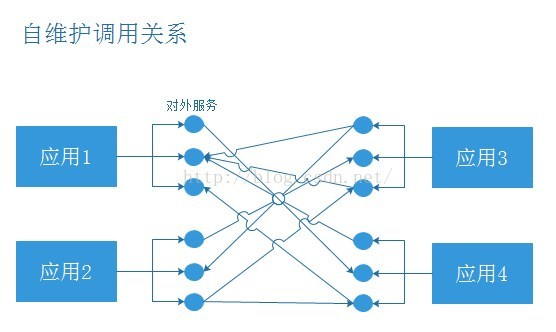
我們遇到的問題:
(1) 當服務越來越多時,服務URL配置管理變得非常困難,F5硬體負載均衡器的單點壓力也越來越大。
此時需要一個服務註冊中心,動態的註冊和發現服務,使服務的位置透明。
並通過在消費方獲取服務提供方地址列表,實現軟負載均衡和Failover,降低對F5硬體負載均衡器的依賴,也能減少部分成本。
(2) 當進一步發展,服務間依賴關係變得錯蹤複雜,甚至分不清哪個應用要在哪個應用之前啟動,架構師都不能完整的描述應用的架構關係。
這時,需要自動畫出應用間的依賴關係圖,以幫助架構師理清理關係。
(3) 接著,服務的呼叫量越來越大,服務的容量問題就暴露出來,這個服務需要多少機器支撐?什麼時候該加機器?
為了解決這些問題,第一步,要將服務現在每天的呼叫量,響應時間,都統計出來,作為容量規劃的參考指標。
其次,要可以動態調整權重,在線上,將某臺機器的權重一直加大,並在加大的過程中記錄響應時間的變化,直到響應時間到達閥值,記錄此時的訪問量,再以此訪問量乘以機器數反推總容量。
為解決這些問題,Dubbo為我們做了什麼呢:
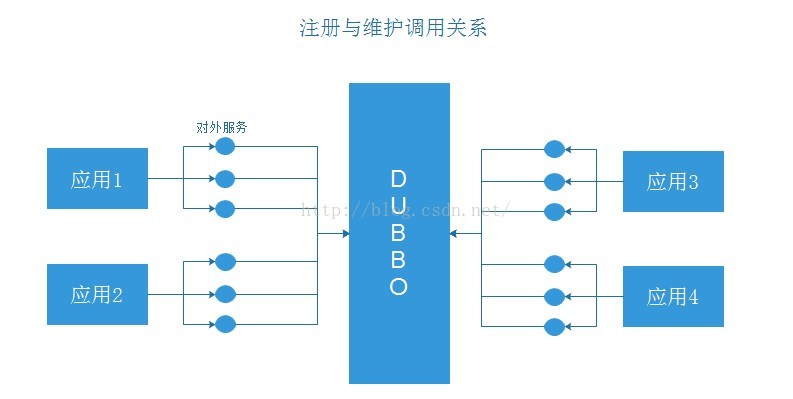
負載均衡:
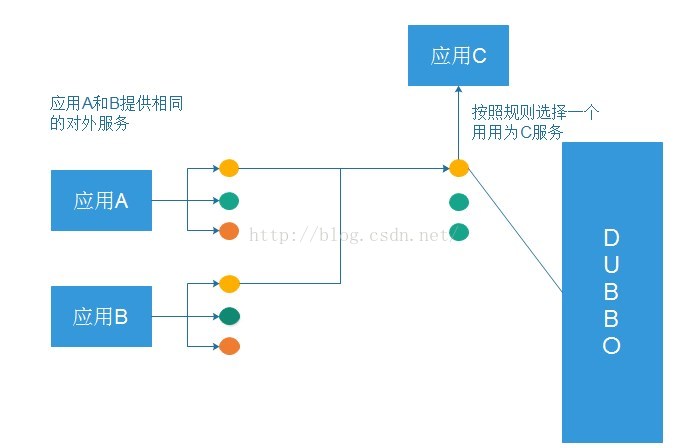
這就是所謂的軟負載均衡!
現在讓我們一起來接觸下這個優秀的框架:
簡介
架構如圖:
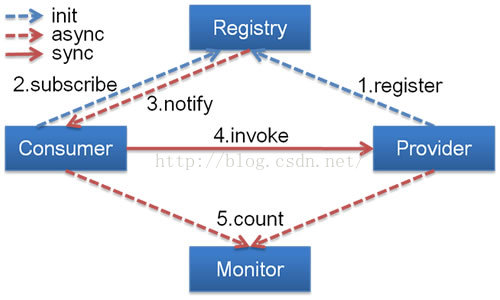
節點角色說明:
Provider: 暴露服務的服務提供方。
Consumer: 呼叫遠端服務的服務消費方。
Registry: 服務註冊與發現的註冊中心。
Monitor: 統計服務的呼叫次調和呼叫時間的監控中心。
Container: 服務執行容器。
呼叫關係說明:
0. 服務容器負責啟動,載入,執行服務提供者。
1. 服務提供者在啟動時,向註冊中心註冊自己提供的服務。
2. 服務消費者在啟動時,向註冊中心訂閱自己所需的服務。
3. 註冊中心返回服務提供者地址列表給消費者,如果有變更,註冊中心將基於長連線推送變更資料給消費者。
4. 服務消費者,從提供者地址列表中,基於軟負載均衡演算法,選一臺提供者進行呼叫,如果呼叫失敗,再選另一臺呼叫。
5. 服務消費者和提供者,在記憶體中累計呼叫次數和呼叫時間,定時每分鐘傳送一次統計資料到監控中心。
Dubbo提供了很多協議,Dubbo協議、RMI協議、Hessian協議,我們檢視Dubbo原始碼,有各種協議的實現,如圖所示:

我們之前沒用Dubbo之前時,大部分都使用Hessian來使用我們服務的暴露和呼叫,利用HessianProxyFactory呼叫遠端介面。
上面是參考了Dubbo官方網介紹,接下來我們來介紹SpringMVC、Dubbo、Zookeeper整合使用。
第一步:在Linux上安裝Zookeeper
Zookeeper作為Dubbo服務的註冊中心,Dubbo原先基於資料庫的註冊中心,沒采用Zookeeper,Zookeeper一個分散式的服務框架,是樹型的目錄服務的資料儲存,能做到叢集管理資料 ,這裡能很好的作為Dubbo服務的註冊中心,Dubbo能與Zookeeper做到叢集部署,當提供者出現斷電等異常停機時,Zookeeper註冊中心能自動刪除提供者資訊,當提供者重啟時,能自動恢復註冊資料,以及訂閱請求。我們先在linux上安裝Zookeeper,我們安裝最簡單的單點,叢集比較麻煩。
先需要安裝JdK,從Oracle的Java網站下載,安裝很簡單,就不再詳述。
單機模式
單機安裝非常簡單,只要獲取到 Zookeeper 的壓縮包並解壓到某個目錄如:C:\zookeeper-3.4.5\下,Zookeeper 的啟動指令碼在 bin 目錄下,Windows 下的啟動指令碼是 zkServer.cmd。
在你執行啟動指令碼之前,還有幾個基本的配置項需要配置一下,Zookeeper 的配置檔案在 conf 目錄下,這個目錄下有 zoo_sample.cfg 和 log4j.properties,你需要做的就是將 zoo_sample.cfg 改名為 zoo.cfg,因為 Zookeeper 在啟動時會找這個檔案作為預設配置檔案。下面詳細介紹一下,這個配置檔案中各個配置項的意義。
- <spanstyle="font-size:18px;"># The number of milliseconds of each tick
- tickTime=2000
- # The number of ticks that the initial
- # synchronization phase can take
- initLimit=10
- # The number of ticks that can pass between
- # sending a request and getting an acknowledgement
- syncLimit=5
- # the directory where the snapshot is stored.
- # do not use /tmp for storage, /tmp here is just
- # example sakes.
- dataDir=C:\\zookeeper-3.4.5\\data
- dataLogDir=C:\\zookeeper-3.4.5\\log
- # the port at which the clients will connect
- clientPort=2181
- #
- # Be sure to read the maintenance section of the
- # administrator guide before turning on autopurge.
- #
- # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
- #
- # The number of snapshots to retain in dataDir
- #autopurge.snapRetainCount=3
- # Purge task interval in hours
- # Set to "0" to disable auto purge feature
- #autopurge.purgeInterval=1</span>
- tickTime:這個時間是作為 Zookeeper 伺服器之間或客戶端與伺服器之間維持心跳的時間間隔,也就是每個 tickTime 時間就會發送一個心跳。
- dataDir:顧名思義就是 Zookeeper 儲存資料的目錄,預設情況下,Zookeeper 將寫資料的日誌檔案也儲存在這個目錄裡。
- dataLogDir:顧名思義就是 Zookeeper 儲存日誌檔案的目錄
- clientPort:這個埠就是客戶端連線 Zookeeper 伺服器的埠,Zookeeper 會監聽這個埠,接受客戶端的訪問請求。
當這些配置項配置好後,你現在就可以啟動 Zookeeper 了,啟動後要檢查 Zookeeper 是否已經在服務,可以通過 netstat – ano 命令檢視是否有你配置的 clientPort 埠號在監聽服務。
第二步:配置dubbo-admin的管理頁面,方便我們管理頁面
(1)下載dubbo-admin-2.4.1.war包,在windows的tomcat部署,先把dubbo-admin-2.4.1放在tomcat的webapps/ROOT下,然後進行解壓
(2)然後到webapps/ROOT/WEB-INF下,有一個dubbo.properties檔案,裡面指向Zookeeper ,使用的是Zookeeper 的註冊中心,如圖所示:
- <spanstyle="font-size:18px;">dubbo.registry.address=zookeeper://127.0.0.1:2181
- dubbo.admin.root.password=root
- dubbo.admin.guest.password=guest</span>
(3)然後啟動tomcat服務,使用者名稱和密碼:root,並訪問服務,顯示登陸頁面,說明dubbo-admin部署成功,如圖所示:
第三步:SpringMVC與Dubbo的整合,這邊使用的Maven的管理專案
第一:我們先開發服務註冊的,就是提供服務,專案結構如圖所示:
(1)test-maven-api專案加入了一個服務介面,程式碼如下:
- publicinterface TestRegistryService {
- public String hello(String name);
- }
(2)test-maven-console在pom.xml加入Dubbo和Zookeeper的jar包、引用test-maven-api的jar包,程式碼如下:
- <spanstyle="font-size:18px;"><dependency>
- <groupId>cn.test</groupId>
- <artifactId>test-maven-api</artifactId>
- <version>0.0.1-SNAPSHOT</version>
- </dependency>
- <dependency>
- <groupId>com.alibaba</groupId>
- <artifactId>dubbo</artifactId>
- <version>2.5.3</version>
- </dependency>
- <dependency>
- <groupId>org.apache.zookeeper</groupId>
-
<artifactId>zookeeper
相關推薦
dubbo+zookeeper構建高可用分散式叢集
我們討論過Nginx+tomcat組成的叢集,這已經是非常靈活的叢集技術,但是當我們的系統遇到更大的瓶頸,全部應用的單點伺服器已經不能滿足我們的需求,這時,我們要考慮另外一種,我們熟悉的內容,就
使用Keepalived構建高可用Web叢集
Keepalived的作用是檢測伺服器的狀態,如果有一臺web伺服器宕機,或工作出現故障,Keepalived將檢測到,並將有故障的伺服器從系統中剔除,同時使用其他伺服器代替該伺服器的工作,當伺服器工作正常後Keepalived自動將伺服器加入到伺服器群中,這些工作全部自動完成,不需要人工干涉,需要人工做的只
redis詳解(四)-- 高可用分散式叢集
一,高可用 高可用(High Availability),是當一臺伺服器停止服務後,對於業務及使用者毫無影響。 停止服務的原因可能由於網絡卡、路由器、機房、CPU負載過高、記憶體溢位、自然災害等不可預期的原因導致,在很多時候也稱單點問題。 (1)解決單點問題主要有2種方
.net core下簡單構建高可用服務叢集
一說到叢集服務相信對普通開發者來說肯定想到很複雜的事情,如zeekeeper ,反向代理服務閘道器等一系列的搭建和配置等等;總得來說需要有一定經驗和規劃的團隊才能應用起來。在這文章裡你能看到在.net core下的另一種叢集構建方案,通過Beetlex即可非常便捷地構建高可用的叢集服務。 簡述
構建高可用分散式Key-Value儲存服務
前言 當我們構建服務端應用的時候,都會面臨資料存放的問題。不同的資料型別有不同的存放方式,譬如關係型資料通常使用MySQL來儲存,文件型資料則會考慮使用MongoDB,而這裡,我們僅僅考慮最簡單的kv(key-value)。 kv的使用場景很多,一個很典型的場景就是使用者session的存放,key為
Flume + Keepalived構建高可用分散式採集系統
10.0.1.76作為Client,通過exec獲取nginx的日誌資訊,然後將資料傳到10.0.1.68(配置了Failover和Load balancing)的節點,最後10.0.1.68將資料傳送的10.0.1.70,77,85,86,87節點,這些節點最終將資料
實踐部署 repmgr+pg9.6構建高可用性叢集
環境:vlnx107001.firstshare.cn primaryvlnx107002.firstshare.cn slavecentos7postresql9.6repmgr4.0.5開啟防火牆firewall-cmd --zone=public -
一張圖講解最少機器搭建FastDFS高可用分散式叢集安裝說明
很幸運參與零售雲快消平臺的公有云搭建及孵化專案。零售雲快消平臺源於零售雲家電3C平臺私有專案,是與公司業務強耦合的。為了適用於全場景全品類平臺,集團要求專案平臺化,我們搶先並承擔了此任務。並由我來主要負責平臺建設及專案落地。 今天講解在零售雲快消平臺中使用的圖片服務FastDFS叢集搭建說明,此叢集模式是
高可用分散式服務框架搭建(Dubbo、ZooKeeper)
以下是官方例項部署方法。此處涉及四個服務: zookeeper:註冊中心 dubbo-admin:服務管理後臺 dubbo-demo-provider:生產者(服務提供者) dubbo-demo-consumer:消費者(服務使用者) 需要注意的是,必
構建高可用ZooKeeper叢集
ZooKeeper 是 Apache 的一個頂級專案,為分散式應用提供高效、高可用的分散式協調服務,提供了諸如資料釋出/訂閱、負載均衡、命名服務、分散式協調/通知和分散式鎖等分散式基礎服務。由於 ZooKeeper 便捷的使用方式、卓越的效能和良好的穩定性,被廣泛地應用於
構建高可用ZooKeeper集群
新的 好的 機器數 單點 java_home 規模 機器 很遺憾 proc 前言 ZooKeeper 是 Apache 的一個頂級項目,為分布式應用提供高效、高可用的分布式協調服務,提供了諸如數據發布/訂閱、負載均衡、命名服務、分布式協調/通知和分布式鎖等分布式基礎服務。由
P7架構師帶你構建高可用ZooKeeper集群
server ado 斷開 分布式 建立 kafka 保存 步驟 運行 前言: ZooKeeper 是 Apache 的一個頂級項目,為分布式應用提供高效、高可用的分布式協調服務,提供了諸如數據發布/訂閱、負載均衡、命名服務、分布式協調/通知和分布式鎖等分布式基礎服務。由於
Centos7上利用corosync+pacemaker+crmsh構建高可用叢集
一、高可用叢集框架 資源型別: primitive(native):表示主資源 group:表示組資源,組資源裡包含多個主資源 clone:表示克隆資源 masterslave:表示主從資源 資源約束方式: 位置約束:定義資源對節點的傾向性 排序約束:定義資源彼此能否執行在同一
corosync+pacemaker使用crmsh構建高可用叢集
一、叢集簡介 引自suse官方關於corosync的高可用叢集的框架圖: 由圖,我們可以看到,suse官方將叢集的Architecture Layers分成四層。最低層Messaging/Infra
一鍵配置高可用Hadoop叢集(hdfs HA+zookeeper HA)
準備環境 3臺節點,主節點 建議 2G 記憶體,兩個從節點 1.5G記憶體, 橋接網路 關閉防火牆 配置ssh,讓節點之間能夠相互 ping 通 準備 軟體放到 autoInstall 目錄下,已存放 hadoop-2.9.0.tar.g
Spark叢集搭建+基於zookeeper的高可用HA
export JAVA_HOME=/usr/java/jdk1.8.0_20/ export SCALA_HOME=/home/iespark/hadoop_program_files/scala-2.10.6/ export HADOOP_HOME=/home/iespark/hadoop_program
快速搭建 Zookeeper+Kafka 高可用叢集環境
1、概念和方案 本文只介紹快速的搭建方案,不囉嗦哈。搭建方案圖,如下: Zookeeper獨立3臺叢集(根據專案情況擴充套件),一臺為leader,其他為follower。 Kafka為多節點多br
基於zookeeper的高可用Hadoop HA叢集安裝
1.Hadoop叢集方式介紹 1.1 hadoop1.x和hadoop2.x都支援的namenode+secondarynamenode方式 優點:搭建環境簡單,適合開發者模式下除錯程式 缺點:namenode作為很重
構建高可用redis(4.0.8)快取叢集-根據圖靈公開課完整實現搭建
redis 主從模式 單體應用,系統中只有一臺redis伺服器,只有一臺時候有單點的問題。 redis升級 主從形式: 升級主從後,從redis 伺服器不對外提供服務,只是從主伺服器哪裡同步資料;一旦主redis伺服器不能提供服務後,前臺運維人員手
dubbo高可用:叢集容錯(十四)
在叢集呼叫失敗時,Dubbo 提供了多種容錯方案,預設為 failover 重試。 Failover Cluster 失敗自動切換,當出現失敗,重試其它伺服器。通常用於讀操作,但重試會帶來更長延遲。可通過 retries="2" 來設定重試次數(不含第一次) 重試次數配