
Scala學習之路(基礎入門)
阿新 • • 發佈:2018-12-25
一、Scala直譯器的使用REPL:Read(取值)-> Evaluation(求值)-> Print(列印)-> Loop(迴圈)scala直譯器也被稱為REPL,會快速編譯scala程式碼為位元組碼,然後交給JVM來執行。計算表示式:在scala>命令列內,鍵入scala程式碼,直譯器會直接返回結果。如果你沒有指定變數來存放這個值,那麼值預設的名稱為res,而且會顯示結果的資料型別,比如Int、Double、String等等。例如,輸入1 + 1,會看到res0: Int = 2內建變數:在後面可以繼續使用res這個變數,以及它存放的值。例如,"Hi, " + res0,返回res2: String = Hi, 2自動補全:在scala>命令列內,可以使用Tab鍵進行自動補全。二、宣告變數 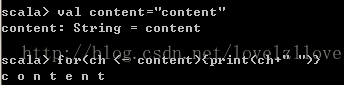
二、求和---------1到8的和
三、以 變數<-表示式 的形式提供多個生成器,用分號將它們隔開(巢狀迴圈)for(i<- 1 to 9;j<- 1 to i){if(i==j) println(j+"*"+i+"="+j*i)else print(j+"*"+i+"="+j*i+"\t")}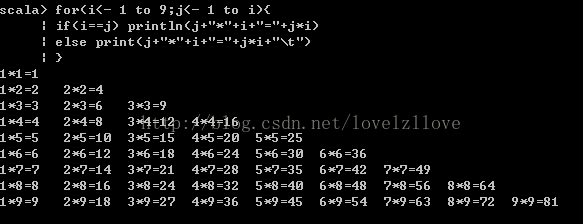
四、在迴圈中使用變數for(i<- 1 to 6;tem=2*i-1;j<- 1 to tem){print("*");if(j==tem) {println()}}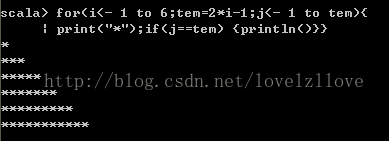
五、守衛式,即在for迴圈中新增過濾條件if語句for(i<- 1 to 3;j<- 1 to 3 if i!=j) print((10*i+j)+" ")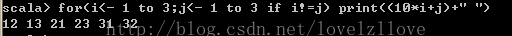
六、推導式如果for迴圈的迴圈體以yield開始,則該迴圈會構造出一個集合,每次迭代生成集合中的一個值。
 六、函式1、函式的分類單行函式:def sayHello(name: String) = print("Hello, " + name)多行函式:如果函式體中有多行程式碼, 則可以使用程式碼塊的方式包裹多行程式碼, 程式碼塊中最後一行的返回值就是整個函式的返回值。 與Java中不同, 不能使用return返回值。比如如下的函式, 實現累加的功能:def sum(n: Int) :Int= {var sum = 0;for(i <- 1 to n) sum += isum}
六、函式1、函式的分類單行函式:def sayHello(name: String) = print("Hello, " + name)多行函式:如果函式體中有多行程式碼, 則可以使用程式碼塊的方式包裹多行程式碼, 程式碼塊中最後一行的返回值就是整個函式的返回值。 與Java中不同, 不能使用return返回值。比如如下的函式, 實現累加的功能:def sum(n: Int) :Int= {var sum = 0;for(i <- 1 to n) sum += isum}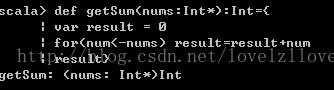
2、函式的定義與呼叫在Scala中定義函式時, 需要定義函式的函式名、 引數、 函式體。def sayHello(name: String, age: Int) = {if (age > 18) { printf("hi %s, you are a big boy\n", name); age }else { printf("hi %s, you are a little boy\n", name); age}}呼叫:sayHello("leo", 30)注:Scala要求必須給出所有引數的型別, 但是不一定給出函式返回值的型別。只要右側的函式體中不包含遞迴的語句, Scala就可以自己根據右側的表示式推斷出返回型別。3、遞迴函式與返回型別如果在函式體內遞迴呼叫函式自身, 則必須給出函式的返回型別。例如, 實現經典的斐波那契數列:def feibo(n:Int):Int={if(n<=2) 1else feibo(n-1)+feibo(n-2)}例如如下階乘: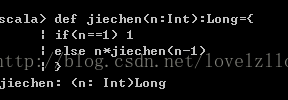
4、引數1》預設引數在Scala中, 有時我們呼叫某些函式時, 不希望給出引數的具體值, 而希望使用引數自身預設的值, 此時就在定義函式時使用預設引數。def sayHello(firstName: String, middleName: String = "William", lastName:String = "Croft") = firstName + " " + middleName + " " + lastName如果給出的引數不夠, 則會從左往右依次應用引數。Java與Scala實現預設引數的區別如下:-----------------------------------------------------------------------------------Java:public void sayHello(String name, int age) {if(name == null) {name = "defaultName"} if(age == 0) {age = 18}} sayHello(null, 0)-----------------------------------------------------------------------------------Scala:def sayHello(name: String, age: Int = 20) {print("Hello, " + name + ", your age is " + age)}sayHello("leo")2》帶名引數在呼叫函式時, 也可以不按照函式定義的引數順序來傳遞引數, 而是使用帶名引數的方式來傳遞。如:sayHello(firstName = "Mick", lastName = "Nina", middleName = "Jack")還可以混合使用未命名引數和帶名引數, 但是未命名引數必須排在帶名引數前面。如下:正確:sayHello("Mick", lastName = "Nina", middleName = "Jack")錯誤:sayHello("Mick", firstName = "Nina", middleName = "Jack")3》使用序列呼叫變長引數在如果要將一個已有的序列直接呼叫變長引數函式, 是不對的。 比如val s = sum(1 to 5)。此時需要使用Scala特殊的語法將引數定義為序列, 讓Scala直譯器能夠識別。這種語法非常有用!Spark的原始碼中大量地使用。例如:val s = sum(1 to 5 : _*) 通過:_*轉換成引數序列案例: 使用遞迴函式實現累加,如下:def sum2(nums: Int*): Int = {if (nums.length == 0) 0else nums.head + sum2(nums.tail: _*)}呼叫:sum2(1,2,3,4,5) 或是 sum2(1 to 5 :_*)注:1、定義nums為一個變長引數,定義函式時用*,呼叫函式需要表示一個引數序列時用:_*2、head 表示集合中的第一個元素,tail 表示集合中除了第一個元素外的其他元素七、過程定義:在Scala中, 定義函式時, 如果函式體直接包裹在了花括號裡面, 而沒有使用=連線,則函式的返回值型別就是Unit, 這樣的函式就被稱之為過程。過程通常用於不需要返回值的函式。過程還有一種寫法, 就是將函式的返回值型別定義為Unit。比較如下:def sayHello(name: String) = "Hello, " + namedef sayHello(name: String) { print("Hello, " + name); "Hello, " + name }def sayHello(name: String): Unit = "Hello, " + name八、lazy值在Scala中, 提供了lazy值的特性, 也就是說, 如果將一個變數宣告為lazy, 則只有在第一次使用該變數時, 變數對應的表示式才會發生計算。這種特性對於特別耗時的計算操作特別有用, 比如開啟檔案進行IO, 進行網路IO等。1、import scala.io.Source._lazy val lines = fromFile("C://Users//Administrator//Desktop//test.txt").mkString即使檔案不存在, 也不會報錯, 只有第一次使用變數時會報錯, 證明了表示式計算的lazy特性val lines = fromFile("C://Users//Administrator//Desktop//test.txt").mkString 這句會報錯2、val lines=sc.textFile("file:///home/tg/datas/ws")val rdd1=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)val rdd2=rdd1.collect運算元: flatMap() map() reduceByKey()轉換型別的運算元(transformation)collect()行動型別的運算元(action)3、val rdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).map(m=>(m._2,m._1)).sortByKey(true).map(m=>(m._2,m._1)).collect注:轉換型別的運算元就是lazy型別,當遇到action行動型別的運算元時,才會觸發執行。總結下劃線的用法:1、導包時,匯入包中所有內容 import scala.io.Source._2、將數列(集合)轉換成引數序列 val result=sum(1 to 10:_*)3、表示Spark運算元操作的每一個元素 lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)八、異常在Scala中, 異常處理和捕獲機制與Java是非常相似的。try {throw new IllegalArgumentException("x should not be negative")} catch {case _:IllegalArgumentException => println("Illegal Argument!")} finally {print("release resources!")} try {throw new IOException("user defined exception")} catch {case e1:IllegalArgumentException => println("illegal argument")case e2:IOException => println("io exception")}九、陣列若陣列長度固定使用Array,若陣列長度不固定則使用ArrayBuffer1、定長陣列的兩種建立方式1》val nums=new Array[Int](10); //10個整數的陣列 2》val array=Array("hello","jack")省略關鍵字new建立陣列的方式,實際上呼叫的是 Array.scala中的apply()方法。原始碼如下:def apply[T: ClassTag](xs: T*): Array[T] = {val array = new Array[T](xs.length)var i = 0for (x <- xs.iterator) {array(i) = x;i += 1 }array}2、變長陣列:陣列緩衝注:scala.collection.mutable._ 可變 scala.collection.immutable._ 不可變對於那種長度按需要變化的陣列,Java有ArrayList,Scala有ArrayBuffer變長陣列ArrayBuffer使用時要導包 import scala.collection.mutable.ArrayBuffervar arr1=ArrayBuffer[Int]()變長陣列操作:1、arr1+=1 2、arr1+=(2,5,6) 3、arr1 ++=Array(3,4)4、arr1.trimEnd(5) 返回值為空,需再次呼叫arr1來檢視刪除後的資料5、arr1.insert(1,3,4) 指定1的位置新增3,4元素 6、arr1.remove(3)
6、arr1.remove(3)
7、arr1.remove(3,2) 指定位置刪除指定數量的元素
3、變長陣列與定長陣列之間的轉換變長陣列→定長陣列:.toArray (不改變原來的陣列,系統會自動建立一個新的arry)定長陣列→變長陣列:.toBuffer4、遍歷陣列until是RichInt類的方法, 返回所有小於( 不包括) 上限的數字。
5、陣列常用演算法,除了sum求和,max最大值,min最小值以外還有如下:
6、陣列的quickSort()快速排序方法scala.util.Sorting.quickSort(array)十、高階函式filter :把一個函式作為引數的函式
for(i <- 0 until arr1.length if(arr1(i)%2==0)) print(arr1(i)+" ")array.filter(m=>m%2==0) 這裡的m可以省去簡寫成 array.filter(_%2==0)m=>m%2==0 匿名函式 m=>{m%2==0}運算元: spark中的運算元有一部分是和scala中的高階函式是一致的,但是有一部分是scala中沒有的,比如reducekey簡寫用下劃線代替m: val rdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)lines.flatMap(m=>m.split(" ")).map(word=>(word,1)).reduceByKey((x,y)=>x+y)十一、對映(Map)1、Scala對映就是鍵值對的集合Map。預設情況下,Scala中使用不可變的對映。如果想使用可變集合Map,必須匯入scala.collection.mutable.Map不可變:val map=Map("tom"->20,"jack"->23,"marray"->22)val map2=Map(("tom",20),("jack",23),("marray",22))可變:val map3=scala.collection.mutable.Map(("tom",20),("jack",23),("marray",22))val map4=new scala.collection.mutable.HashMap[String,Int]對映這種資料結構是一種將鍵對映到值的函式。 區別在於通常的函式計算值, 而對映只是做查詢。2、獲取對映中的值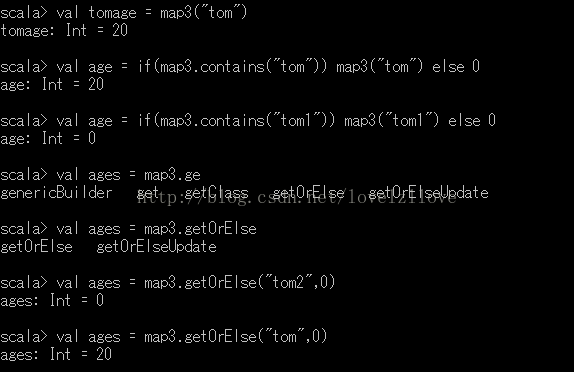
注:1》如果對映並不包含請求中使用的鍵, 則會丟擲異常。2》要檢查對映中是否有某個指定的鍵, 可以用contains方法。3》getOrElse方法, 若包含相應的鍵, 就返回這個鍵所對應的值, 否則返加0。4》對映.get(鍵)這樣的呼叫返回一個Option物件, 要麼是Some(鍵對應的值), 要麼是None。3、修改Map的元素更新可變Map集合:1》更新Map的元素 ages("Leo") = 312》增加多個元素 ages += ("Mike" -> 35, "Tom" -> 40)3》 移除元素 ages -= "Mike"更新不可變Map集合:1》 新增不可變Map的元素, 產生一個新的集合Map, 原Map不變val ages2 = ages + ("Mike" -> 36, "Tom" -> 40)2》移除不可變Map的元素, 產生一個新的集合Map, 原Map不變val ages3 = ages - "Tom"4、遍歷Map操作//遍歷map的entrySet for ((key, value) <- ages) println(key + " " + value)// 遍歷map的key for (key <- ages.keySet) println(key)// 遍歷map的value for (value <- ages.values) println(value)// 生成新map, 反轉key和value for ((key, value) <- ages) yield (value, key)5、SortedMap和LinkedHashMap// SortedMap可以自動對Map的key的排序val ages = scala.collection.immutable.SortedMap("leo" -> 30, "alice" -> 15, "jen" -> 25)// LinkedHashMap可以記住插入entry的順序val ages = new scala.collection.mutable.LinkedHashMap[String, Int]ages("leo") = 30ages("alice") = 15ages("jen") = 256、Java Map與Scala Map的隱式轉換import scala.collection.JavaConversions.mapAsScalaMapval javaScores = new java.util.HashMap[String, Int]()javaScores.put("Alice", 10)javaScores.put("Bob", 3)javaScores.put("Cindy", 8)val scalaScores: scala.collection.mutable.Map[String, Int] = javaScores===========================================================import scala.collection.JavaConversions.mapAsJavaMapimport java.awt.font.TextAttribute._val scalaAttrMap = Map(FAMILY -> "Serif", SIZE -> 12)val font = new java.awt.Font(scalaAttrMap)7、元組(tuple)概念:元組是不同型別的值的聚集,對偶是元組的最簡單形態,元組的索引從1開始,而不是0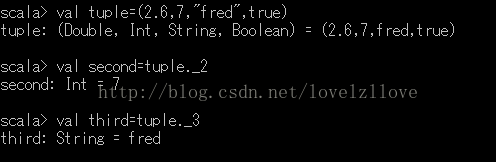
Tuple拉鍊操作:Tuple拉鍊操作指的就是zip操作,zip操作是Array類的方法, 用於將兩個Array, 合併為一個Array比如 Array(v1)和Array(v2), 使用zip操作合併後的格式為Array((v1,v2)),合併後的Array的元素型別為Tuple。例子如下:val students = Array("Leo", "Jack", "Jen")val scores = Array(80, 100, 90)val studentScores = students.zip(scores)for ((student, score) <- studentScores) println(student + " " + score)注:如果Array的元素型別是Tuple, 呼叫Array的toMap方法, 可以將Array轉換為Map如,studentScores.toMap
二、求和---------1到8的和
三、以 變數<-表示式 的形式提供多個生成器,用分號將它們隔開(巢狀迴圈)for(i<- 1 to 9;j<- 1 to i){if(i==j) println(j+"*"+i+"="+j*i)else print(j+"*"+i+"="+j*i+"\t")}
四、在迴圈中使用變數for(i<- 1 to 6;tem=2*i-1;j<- 1 to tem){print("*");if(j==tem) {println()}}
五、守衛式,即在for迴圈中新增過濾條件if語句for(i<- 1 to 3;j<- 1 to 3 if i!=j) print((10*i+j)+" ")
六、推導式如果for迴圈的迴圈體以yield開始,則該迴圈會構造出一個集合,每次迭代生成集合中的一個值。
2、函式的定義與呼叫在Scala中定義函式時, 需要定義函式的函式名、 引數、 函式體。def sayHello(name: String, age: Int) = {if (age > 18) { printf("hi %s, you are a big boy\n", name); age }else { printf("hi %s, you are a little boy\n", name); age}}呼叫:sayHello("leo", 30)注:Scala要求必須給出所有引數的型別, 但是不一定給出函式返回值的型別。只要右側的函式體中不包含遞迴的語句, Scala就可以自己根據右側的表示式推斷出返回型別。3、遞迴函式與返回型別如果在函式體內遞迴呼叫函式自身, 則必須給出函式的返回型別。例如, 實現經典的斐波那契數列:def feibo(n:Int):Int={if(n<=2) 1else feibo(n-1)+feibo(n-2)}例如如下階乘:
4、引數1》預設引數在Scala中, 有時我們呼叫某些函式時, 不希望給出引數的具體值, 而希望使用引數自身預設的值, 此時就在定義函式時使用預設引數。def sayHello(firstName: String, middleName: String = "William", lastName:String = "Croft") = firstName + " " + middleName + " " + lastName如果給出的引數不夠, 則會從左往右依次應用引數。Java與Scala實現預設引數的區別如下:-----------------------------------------------------------------------------------Java:public void sayHello(String name, int age) {if(name == null) {name = "defaultName"} if(age == 0) {age = 18}} sayHello(null, 0)-----------------------------------------------------------------------------------Scala:def sayHello(name: String, age: Int = 20) {print("Hello, " + name + ", your age is " + age)}sayHello("leo")2》帶名引數在呼叫函式時, 也可以不按照函式定義的引數順序來傳遞引數, 而是使用帶名引數的方式來傳遞。如:sayHello(firstName = "Mick", lastName = "Nina", middleName = "Jack")還可以混合使用未命名引數和帶名引數, 但是未命名引數必須排在帶名引數前面。如下:正確:sayHello("Mick", lastName = "Nina", middleName = "Jack")錯誤:sayHello("Mick", firstName = "Nina", middleName = "Jack")3》使用序列呼叫變長引數在如果要將一個已有的序列直接呼叫變長引數函式, 是不對的。 比如val s = sum(1 to 5)。此時需要使用Scala特殊的語法將引數定義為序列, 讓Scala直譯器能夠識別。這種語法非常有用!Spark的原始碼中大量地使用。例如:val s = sum(1 to 5 : _*) 通過:_*轉換成引數序列案例: 使用遞迴函式實現累加,如下:def sum2(nums: Int*): Int = {if (nums.length == 0) 0else nums.head + sum2(nums.tail: _*)}呼叫:sum2(1,2,3,4,5) 或是 sum2(1 to 5 :_*)注:1、定義nums為一個變長引數,定義函式時用*,呼叫函式需要表示一個引數序列時用:_*2、head 表示集合中的第一個元素,tail 表示集合中除了第一個元素外的其他元素七、過程定義:在Scala中, 定義函式時, 如果函式體直接包裹在了花括號裡面, 而沒有使用=連線,則函式的返回值型別就是Unit, 這樣的函式就被稱之為過程。過程通常用於不需要返回值的函式。過程還有一種寫法, 就是將函式的返回值型別定義為Unit。比較如下:def sayHello(name: String) = "Hello, " + namedef sayHello(name: String) { print("Hello, " + name); "Hello, " + name }def sayHello(name: String): Unit = "Hello, " + name八、lazy值在Scala中, 提供了lazy值的特性, 也就是說, 如果將一個變數宣告為lazy, 則只有在第一次使用該變數時, 變數對應的表示式才會發生計算。這種特性對於特別耗時的計算操作特別有用, 比如開啟檔案進行IO, 進行網路IO等。1、import scala.io.Source._lazy val lines = fromFile("C://Users//Administrator//Desktop//test.txt").mkString即使檔案不存在, 也不會報錯, 只有第一次使用變數時會報錯, 證明了表示式計算的lazy特性val lines = fromFile("C://Users//Administrator//Desktop//test.txt").mkString 這句會報錯2、val lines=sc.textFile("file:///home/tg/datas/ws")val rdd1=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)val rdd2=rdd1.collect運算元: flatMap() map() reduceByKey()轉換型別的運算元(transformation)collect()行動型別的運算元(action)3、val rdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).map(m=>(m._2,m._1)).sortByKey(true).map(m=>(m._2,m._1)).collect注:轉換型別的運算元就是lazy型別,當遇到action行動型別的運算元時,才會觸發執行。總結下劃線的用法:1、導包時,匯入包中所有內容 import scala.io.Source._2、將數列(集合)轉換成引數序列 val result=sum(1 to 10:_*)3、表示Spark運算元操作的每一個元素 lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)八、異常在Scala中, 異常處理和捕獲機制與Java是非常相似的。try {throw new IllegalArgumentException("x should not be negative")} catch {case _:IllegalArgumentException => println("Illegal Argument!")} finally {print("release resources!")} try {throw new IOException("user defined exception")} catch {case e1:IllegalArgumentException => println("illegal argument")case e2:IOException => println("io exception")}九、陣列若陣列長度固定使用Array,若陣列長度不固定則使用ArrayBuffer1、定長陣列的兩種建立方式1》val nums=new Array[Int](10); //10個整數的陣列 2》val array=Array("hello","jack")省略關鍵字new建立陣列的方式,實際上呼叫的是 Array.scala中的apply()方法。原始碼如下:def apply[T: ClassTag](xs: T*): Array[T] = {val array = new Array[T](xs.length)var i = 0for (x <- xs.iterator) {array(i) = x;i += 1 }array}2、變長陣列:陣列緩衝注:scala.collection.mutable._ 可變 scala.collection.immutable._ 不可變對於那種長度按需要變化的陣列,Java有ArrayList,Scala有ArrayBuffer變長陣列ArrayBuffer使用時要導包 import scala.collection.mutable.ArrayBuffervar arr1=ArrayBuffer[Int]()變長陣列操作:1、arr1+=1 2、arr1+=(2,5,6) 3、arr1 ++=Array(3,4)4、arr1.trimEnd(5) 返回值為空,需再次呼叫arr1來檢視刪除後的資料5、arr1.insert(1,3,4) 指定1的位置新增3,4元素
6、arr1.remove(3)7、arr1.remove(3,2) 指定位置刪除指定數量的元素
3、變長陣列與定長陣列之間的轉換變長陣列→定長陣列:.toArray (不改變原來的陣列,系統會自動建立一個新的arry)定長陣列→變長陣列:.toBuffer4、遍歷陣列until是RichInt類的方法, 返回所有小於( 不包括) 上限的數字。
5、陣列常用演算法,除了sum求和,max最大值,min最小值以外還有如下:
6、陣列的quickSort()快速排序方法scala.util.Sorting.quickSort(array)十、高階函式filter :把一個函式作為引數的函式
for(i <- 0 until arr1.length if(arr1(i)%2==0)) print(arr1(i)+" ")array.filter(m=>m%2==0) 這裡的m可以省去簡寫成 array.filter(_%2==0)m=>m%2==0 匿名函式 m=>{m%2==0}運算元: spark中的運算元有一部分是和scala中的高階函式是一致的,但是有一部分是scala中沒有的,比如reducekey簡寫用下劃線代替m: val rdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)lines.flatMap(m=>m.split(" ")).map(word=>(word,1)).reduceByKey((x,y)=>x+y)十一、對映(Map)1、Scala對映就是鍵值對的集合Map。預設情況下,Scala中使用不可變的對映。如果想使用可變集合Map,必須匯入scala.collection.mutable.Map不可變:val map=Map("tom"->20,"jack"->23,"marray"->22)val map2=Map(("tom",20),("jack",23),("marray",22))可變:val map3=scala.collection.mutable.Map(("tom",20),("jack",23),("marray",22))val map4=new scala.collection.mutable.HashMap[String,Int]對映這種資料結構是一種將鍵對映到值的函式。 區別在於通常的函式計算值, 而對映只是做查詢。2、獲取對映中的值
注:1》如果對映並不包含請求中使用的鍵, 則會丟擲異常。2》要檢查對映中是否有某個指定的鍵, 可以用contains方法。3》getOrElse方法, 若包含相應的鍵, 就返回這個鍵所對應的值, 否則返加0。4》對映.get(鍵)這樣的呼叫返回一個Option物件, 要麼是Some(鍵對應的值), 要麼是None。3、修改Map的元素更新可變Map集合:1》更新Map的元素 ages("Leo") = 312》增加多個元素 ages += ("Mike" -> 35, "Tom" -> 40)3》 移除元素 ages -= "Mike"更新不可變Map集合:1》 新增不可變Map的元素, 產生一個新的集合Map, 原Map不變val ages2 = ages + ("Mike" -> 36, "Tom" -> 40)2》移除不可變Map的元素, 產生一個新的集合Map, 原Map不變val ages3 = ages - "Tom"4、遍歷Map操作//遍歷map的entrySet for ((key, value) <- ages) println(key + " " + value)// 遍歷map的key for (key <- ages.keySet) println(key)// 遍歷map的value for (value <- ages.values) println(value)// 生成新map, 反轉key和value for ((key, value) <- ages) yield (value, key)5、SortedMap和LinkedHashMap// SortedMap可以自動對Map的key的排序val ages = scala.collection.immutable.SortedMap("leo" -> 30, "alice" -> 15, "jen" -> 25)// LinkedHashMap可以記住插入entry的順序val ages = new scala.collection.mutable.LinkedHashMap[String, Int]ages("leo") = 30ages("alice") = 15ages("jen") = 256、Java Map與Scala Map的隱式轉換import scala.collection.JavaConversions.mapAsScalaMapval javaScores = new java.util.HashMap[String, Int]()javaScores.put("Alice", 10)javaScores.put("Bob", 3)javaScores.put("Cindy", 8)val scalaScores: scala.collection.mutable.Map[String, Int] = javaScores===========================================================import scala.collection.JavaConversions.mapAsJavaMapimport java.awt.font.TextAttribute._val scalaAttrMap = Map(FAMILY -> "Serif", SIZE -> 12)val font = new java.awt.Font(scalaAttrMap)7、元組(tuple)概念:元組是不同型別的值的聚集,對偶是元組的最簡單形態,元組的索引從1開始,而不是0
Tuple拉鍊操作:Tuple拉鍊操作指的就是zip操作,zip操作是Array類的方法, 用於將兩個Array, 合併為一個Array比如 Array(v1)和Array(v2), 使用zip操作合併後的格式為Array((v1,v2)),合併後的Array的元素型別為Tuple。例子如下:val students = Array("Leo", "Jack", "Jen")val scores = Array(80, 100, 90)val studentScores = students.zip(scores)for ((student, score) <- studentScores) println(student + " " + score)注:如果Array的元素型別是Tuple, 呼叫Array的toMap方法, 可以將Array轉換為Map如,studentScores.toMap