
資料結構 : 字首樹 Trie
阿新 • • 發佈:2018-12-25
字首樹 Trie
1 什麼是Trie樹
- Trie樹,又叫字典樹 字首樹 單詞查詢樹 鍵樹
- 是一種樹形結構,是一種雜湊樹的變種
- 是一種多叉樹.
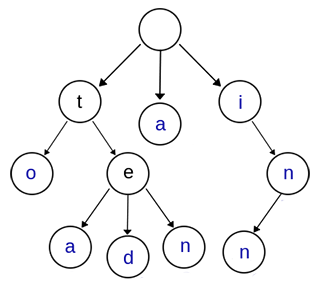
1.1 基本性質:
- 根節點不包含字元. 除了根節點之外,每個子節點包含一個字元.
- 從根節點到某一節點,路徑通過經過的字元連線.為該節點對應字串
- 每個節點的所有子節點包換的字元互不相同
通常,會在節點結構中設定一個標誌,用來標記該結點處是否構成一個單詞(關鍵字).
2 Tire樹的優缺點
Tire樹的核心思想是通過 空間來換時間.
利用字串的公共字首來減少無謂的字串比較
2.1 優點
-
插入和查詢效率高! 都是 O(m). m為字串長度.
-
Tire樹中不同的關鍵字不會產生衝突.
Trie樹只有在允許一個關鍵字關聯多個值的情況下才有類似hash碰撞發生.
-
Trie樹不用求 hash 值.對短字串有更快的速度.
通常求hash值也是需要遍歷字串的.
-
Trie樹可以對關鍵字按字典序排序
2.2 缺點
-
當 hash 函式很好時. Trie樹的查詢效率會低於雜湊搜尋
-
空間消耗比較大
優化:
壓縮字典樹 Compressed Trie
Ternay Search Trie 三分搜尋樹
3 Trie樹的應用
3.1 字串檢索
檢索/查詢功能是Trie樹最原始的功能
思路 是從根節點開始一個一個字元進行比較
- 如果沿路比較,發現不同的字元,則表示該字串在集合中不存在
- 如果所有的字元全部比較完並且全部相同,還需要判斷一下最後一個節點的標誌位.標記該節點是否代表一個關鍵字.
class Node { public: bool isWord; // 標記是否是一個關鍵字 map<char, Node*> next; // 存放各個子節點 Node(bool isWord) { this->isWord = isWord; } Node() { Node(false); } };
3.2 詞頻統計
Trie樹常被搜尋引擎系統用於文字詞頻統計
思路 就是增加一個 count 來計數. 對每一個關鍵字執行插入操作時,若已經存在,則計數+1.若不存在則,插入後 count 置為1.
3.3 字串排序
Trie樹可以對大量字串按字典序進行排序
思路 就是遍歷一遍所有的關鍵字,將他們全部插入 Trie 樹.
樹的每個結點的所有兒子,很顯然按照字母表排序.然後先序遍歷輸出 Trie 樹中所有關鍵字即可.
3.4 字首匹配
例如: 找出一個字串集合中所有以ab開頭的字串 . 需要用所有的字串構造一個 trie 樹. 然後然後輸出 以 a->b-> 開頭的路徑的搜有關鍵字即可.
trie樹字首匹配常用於搜尋提示 :
如當輸入一個網址. 可以自動搜尋出可能的選擇.
當沒有完全匹配的搜尋結果,可以返回字首最相似的可能.
3.5 作為其他資料結構和演算法的輔助結構
字尾樹 : (字串模式識別)
4 C++實現簡單的 Trie 樹
class Trie {
private:
class Node {
public:
bool isWord;
map<char, Node*> next;
Node(bool isWord) {
this->isWord = isWord;
}
Node() {
Node(false);
}
};
Node* root; // 根節點
int size;
public:
Trie() {
root = new Node();
size = 0;
}
// 獲得Trie儲存的單詞數量
int getSize() {
return size;
}
// trie中新增一個新的word
void add(string word) {
Node* cur = root;
for (int i = 0; i < word.size(); i++) {
char c = word[i]; // 當前的字元
if(cur->next.count(c)==0){ // 如果找不到呢,就要自己加一個
cur->next.insert(make_pair(c, new Node(false)));
}
// 移動節點到下一個節點
cur = cur->next[c];
}
// 若當前這個單詞滿意出現過,則把它置為真
if (!cur->isWord) {
cur->isWord = true;
size++;
}
}
// 查詢單詞word是否在Trie中
bool contains(string word) {
Node* cur = root;
for (int i = 0; i < word.size(); i++) {
char c = word[i];
if (cur->next.count(c) == 0) {
return false;
}
cur = cur->next[c];
}
return cur->isWord;
}
// 在Trie中查詢是否有單詞以orefix為字首
bool isPrefix(string prefix) {
Node* cur = root;
for (int i = 0; i < prefix.size(); i++) {
char c = prefix[i];
if (cur->next.count(c) == 0) {
return false;
}
cur = cur->next[c];
}
return true;
}
};
5 Trie刪除操作
待續
6 LeetCode題解
208. Implement Trie (Prefix Tree)
參考上面程式碼
211. Add and Search Word - Data structure design
class WordDictionary {
public:
class Node {
public:
bool isWord;
map<char, Node*> next;
Node(bool isWord) {
this->isWord = isWord;
}
Node() {
Node(false);
}
};
Node* root;
/** Initialize your data structure here. */
WordDictionary() {
root = new Node(false);
}
/** Adds a word into the data structure. */
void addWord(string word) {
Node* cur = root;
for (int i = 0; i < word.size(); i++) {
char c = word[i]; // 當前的字元
if (cur->next.count(c) == 0) { // 如果找不到呢,就要自己加一個
cur->next.insert(make_pair(c, new Node(false)));
}
// 移動節點到下一個節點
cur = cur->next[c];
}
// 若當前這個單詞滿意出現過,則把它置為真
if (!cur->isWord) {
cur->isWord = true;
}
}
bool search(Node* node, string word, int start) {
// 遞迴結束條件
if (start == word.size()) {
return node->isWord;
}
Node* cur = node;
char c = word[start];
if (c == '.') {
for (auto it = cur->next.begin(); it != cur->next.end(); it++) {
if (search(it->second,word,start+1))
{
return true;
}
}
return false;
}
else { // 不是'.' 就要判斷存不存在 c
if (cur->next.count(c) == 0) {
return false;
}
cur = cur->next[c];
return search(cur, word, start + 1);
}
}
/** Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter. */
bool search(string word) {
Node* cur = root;
return search(cur, word, 0);
}
};
677
class MapSum {
public:
class Node {
public:
Node(int val) {
this->val = val;
}
Node() {
Node(0);
}
map<char, Node*> next;
int val;
};
Node* root;
/** Initialize your data structure here. */
MapSum() {
root = new Node();
}
void insert(string key, int val) {
Node* cur = root;
for (auto c : key) {
if (cur->next.count(c) == 0) {
cur->next.insert(make_pair(c, new Node(0)));
}
cur = cur->next[c];
}
cur->val = val;
}
int sum(Node* node) {
int res = 0;
Node* cur = node;
if (cur->val != 0) {
res += cur->val;
}
for (auto it = cur->next.begin(); it != cur->next.end(); it++) {
res += sum(it->second);
}
return res;
}
int sum(string prefix) {
Node* cur = root;
for (auto c : prefix) {
if (cur->next.count(c) == 0) {
return 0;
}
cur = cur->next[c];
}
// 找到了以prefix開頭的節點,接下來要遍歷所有的的節點
return sum(cur);
}
};
/**
* Your MapSum object will be instantiated and called as such:
* MapSum obj = new MapSum();
* obj.insert(key,val);
* int param_2 = obj.sum(prefix);
*/