
MySQL支援的索引型別(B-Tree索引、hash索引)
索引,是儲存引擎用於快速找到記錄的一種資料結構。尤其是在表中的資料量越來越大時,索引對於效能的提升非常關鍵。今天先聊一聊MySQL支援的兩種主要的索引型別。
在MySQL中,儲存引擎在使用索引時,會先在索引中找到對應值,然後根據所匹配的索引記錄找到對應的資料行。例如:
select name from user where id = 10;
若在id列上建有索引,則mysql將使用該索引找到id = 10的行,然後返回所有包含該值的資料行。
B-Tree索引
大多數的MySQL引擎都支援B-Tree索引,它底層使用的是B+Tree這種資料結構來儲存資料的。若是有人對B-Tree這種資料結構不太熟悉的話,可以參考我之前的一篇博文
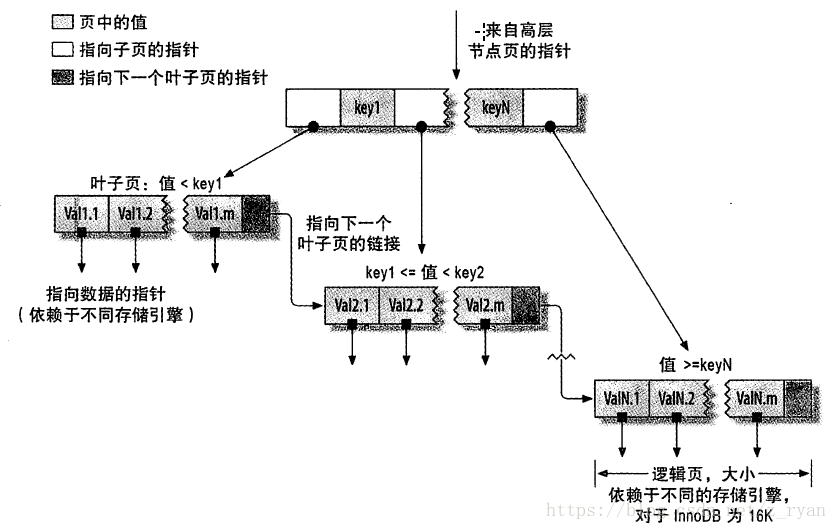
B-Tree索引是一個平衡查詢樹,葉子到根部的節點距離相等。所有的記錄都是按照鍵值的大小排列,葉子結點由指標連線。
B-Tree索引的特點
1、B-tree索引可以加快資料的查詢速度
儲存引擎不需要進行全表掃描來獲得需要的資料,取而代之的是從索引的根節點開始進行搜尋。然後根據指標逐層向下查詢,通過比較節點頁的值和有目標值就可以找到合適的指標進入下層節點,而這些指標實際上定義了子節點頁中值的上限和下限。
2、B-tree索引更適合進行範圍查詢
因為前面說過,B-tree對索引是順序組織儲存的,所以就很適合進行查詢範圍資料。
B-tree索引的使用場景
1、全值匹配的查詢
指的是和索引中的所有列進行匹配,比如查詢欄位 name = ‘tom’;
2、匹配最左字首的查詢
比如為a列和b列設定聯合索引,只要聯合索引的第一列(a列)符合查詢條件,索引就會被用到,若只是第二列(b列)符合條件則不會被用到該索引。
3、匹配列字首的查詢
只匹配某一列的值的開頭部分
4、匹配範圍值
5、精準匹配某一列並範圍匹配另外一列
6、只訪問索引的查詢
在這裡指的就是覆蓋索引,即只需要訪問索引,而無需訪問資料行
7、用於查詢中的order by 操作
索引樹中的節點是有序的。一般來說,若B-Tree可以按照某種方式查詢到該值,那麼也可以用這種方式用於排序。所以,如果 order by 子句中滿足前面列出的幾種查詢型別,則這個索引也可以滿足對應的排序需求。
B-Tree索引的限制
1、若不是按照索引的最左列開始查詢,則無法使用該索引
比如建立聯合索引(name 、phone_num),若搜尋phone_num則無法使用該索引
2、使用索引時,不能跳過索引中的列
比如建立聯合索引(name 、phone_num 、addr),若搜尋name和addr 則無法使用該索引只能使用那麼過濾
3、not in 和 <> 操作無法使用該索引
4、若查詢中有某個列的範圍查詢,則其右邊的所有列都無法使用索引
注意:
儲存引擎用不同的方式使用B-Tree索引,效能也各有不同,各有優劣。例如,MyISAM使用字首壓縮的技術使得索引更小,但InnoDB則按照原資料格式進行儲存。
MyISAM索引通過資料的物理位置引用被索引的行,而InnoDB則根據逐漸引用被索引的行
至此,我們基本已經將B-Tree索引介紹完了,下面我們來了解另外的一種MySQL的索引型別:HASH索引。
HASH索引
在MySQL的儲存引擎中,MyISAM不支援雜湊索引,而InnoDB中的hash索引是儲存引擎根據B-Tree索引自建的,後面會對其做具體說明。
hash索引的特點
1、hash索引是基於hash表實現的,只有查詢條件精確匹配hash索引中的所有列的時候,才能用到hash索引。
2、對於hash索引中的所有列,儲存引擎都會為每一行計算一個hash碼,hash索引中儲存的就是hash碼。
3、hash索引包括鍵值、hash碼和指標 。
因為hash索引本身只需要儲存對應的hash值,所以索引的結構十分緊湊,這也讓hash索引查詢的速度非常快。然而,hash索引也是存在其限制的:
hash索引的限制
1、Hash索引必須進行二次查詢
使用哈市索引兩次查詢,第一次找到相應的行,第二次讀取資料,但是被頻繁訪問到的行一般會快取在記憶體中,這點對資料庫效能的影響不大。
2、hash索引不能用於外排序
hash索引儲存的是hash碼而不是鍵值,所以無法用於外排序
3、hash索引不支援部分索引查詢也不支援範圍查詢
只能用到等值查詢,不能範圍和模糊查詢
4、hash索引中的hash碼的計算可能存在hash衝突
當出現hash衝突的時候,儲存引擎必須遍歷整個連結串列中的所有行指標,逐行比較,直到找到所有的符合條件的行,若hash衝突很多的話,一些索引的維護代價機會很高,所以說hash索引不適用於選擇性很差的列上(重複值很多)。姓名、性別、身份證(合適)
上面說到InnoDB的“自適應hash索引”。就是當InnoDB注意到某些索引值被使用的非常頻繁時,它會在記憶體中基於B-Tree索引上在建立一個hash索引,這樣就讓B-tree索引也具有hash索引的一些優點。這是一個完全自動的內部的行為,使用者無法控制或配置,不過,如果有需要,完全可以關閉該功能。
建立自定義hash索引
若儲存引擎不支援hash索引,又想擁有hash索引所帶來的效能提升,則可以模擬InnoDB一樣建立雜湊索引。
思路也比較簡單,就是在B-tree基礎上建立一個偽雜湊索引。這和真正的hash索引不是一回事,因為還是採用B-Tree進行查詢,但是它使用的是hash值而不是鍵本身進行查詢。只需要在查詢的where子句中手動指定使用hash函式即可。下面舉個簡單的例子:
比如:當我們需要儲存大量的URL,並需要根據URL進行搜尋查詢。若用B-Tree來儲存URL,儲存的內容就會很大。此時的查詢語句就是:
select id from url where url = "www.baidu.com";
若刪除原來的url列上的索引,而新增一個被索引的url_crc列,使用crc32做hash函式,則可以使用如下方式查詢:
select id from url where url = "www.baidu.com" and url_crc=CRC32("www.baidu.com");
這樣做的話,效能就會有很大提升,因為mysql優化器會使用這個選擇性高而體積很小的基於url_crc列的多音來完成查詢。即使有多個記錄相同的索引值,查詢仍然很快,只需要根據hash值做快速的整數比較就能找到索引條目,然後一一返回對應的行。
缺點
1、需要維護hash值,可以手動維護,也可以使用觸發器實現。
2、若資料表非常大的話,CRC32()會出現大量hash衝突,則可以自己實現一個64位的hash函式,這個自定義的hash函式要返回整數而不是字串,因為範圍整數,對此效率更高。一個簡單的辦法就是使用MD5()函式返回值的一部分來作為自定義的hash函式。但是這可能比自己寫一個hash演算法效能要差一些。