
[聊天機器人]:開源ChatterBot工作原理
作者:鄒祁峰
郵箱:[email protected]
部落格:http://blog.csdn.net/qifengzou
日期:2017.08.12 18:35
轉載請註明來自"祁峰"的CSDN部落格
1 引言
ChatterBot is a machine-learning based conversational dialog engine build in Python which makes it possible to generate responses based on collections of known conversations. The language independent design of ChatterBot allows it to be trained to speak any language.
完成聊天室系統的研發之後,在生產環境中發現部分聊天室中人數較少,使用者之間的交流互動更是沉寂,顯得十分冷清。為解決此問題,本人計劃開發一個聊天機器人使其能夠模擬人類的對話過程,讓原本沉寂的聊天室活躍起來。
為達到以上目標,本人分析了開源社群關注度較高的聊天機器人專案ChatterBot的實現原理。
1.訓練語料可存放在多種介質上
2.訓練結果可存放在多種介質上
3.應答匹配演算法支援多種應答匹配演算法:相似度匹配、數學估值演算法等
4.可訓練支援任何語言的聊天機器人
1.效能較低:收到聊天請求時,其需要遍歷所有語料以找到相似度最高的語句,並提取對應的應答語句。因此,訓練語料過多時(超過1萬條),應答時延可能已無法讓人接受。
2.場景有限:其只能應用到一些情況簡單、場景單一的環境。由於效能較低,因此,無法使用過多的語料對ChatterBot進行訓練,這也必然限制了應用場景。
2 工作原理
2.1 準備語料
ChatterBot的最大特點是:可訓練支援任何語言的聊天機器人。如果希望ChatterBot能夠應答中文,則需要使用中文對話語料訓練;如果希望ChatterBot能夠應答英文,則需要使用英文對話語料訓練;其他語言依次類推。可以將ChatterBot的訓練對話語料儲存在資料庫或本地檔案中,如:MONGODB/SQLite/JSON-FILE等。[注:以下提到的資料庫中的訓練語料指的就是儲存在MONGODB/SQLite/JSON-FILE中的對話語料]
對話語料的好壞將會直接影響聊天機器人的對話效果。設想一下,訓練的對話語料的都不是正常人類的對話過程,怎麼能夠訓練出類似人類的聊天機器人呢?最後,大家應該清楚訓練語料的準備階段與其他階段相比非常的費時費力,可以說該階段是最重要的。
2.2 訓練階段
完成對話語料的準備後,則需要使用這些對話語料來訓練ChatterBot機器人。訓練的過程其實就是將對話語料轉換成對話過程中能夠查詢、轉換的資料物件。以下是ChatterBot的訓練過程:
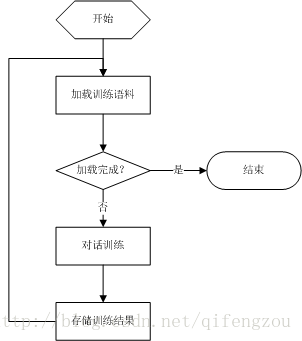
1. 載入訓練語料
在進行聊天機器人的訓練時,需要將儲存在資料庫中的訓練語料逐段/全部載入記憶體,為對話訓練做準備。
如果訓練語料較多,而且使用JSON儲存,則載入語料過程可能會耗費較長時間。因此,訓練語料較多時,建議使用MONGODB/SQLite等資料庫儲存訓練語料。
2. 對話訓練
使用“訓練”一詞非常抽象,其實對話訓練的過程就是將對話語料轉換成對話過程中能夠查詢、轉換的資料物件。ChatterBot之所以能夠訓練出支援“任何語言”的聊天機器人,關鍵就在於其訓練過程。
ChatterBot之所以能夠訓練出支援“任何語言”的聊天機器人,是因為其在此過程並不對訓練語料做深度加工(如:分詞)處理,而是直接將訓練語料直接轉換成Statement->Response對,並將其儲存起來。雖然其帶來了支援“任何語言”的優點,但是其也帶來了致命的缺點:效能低下!
3. 儲存訓練結果
完成對話訓練後,我們需要將訓練結果儲存起來,以便在收到聊天請求時能夠快速從之前的訓練結果中找到答案並響應對方。
之前提到過:ChatterBot可將訓練結果儲存在資料庫中(MONGODB/SQLite/JSON-FILE)。但是需要注意的是:使用Json檔案儲存訓練語料和訓練結果時,每訓練一對對話ChatterBot就會將其寫入到Json檔案中,這樣導致對Json檔案大量的重複載入、重複解析、重複生成、重複寫入檔案的操作,非常的耗時。當訓練語句超過1萬條時,即使訓練4-5小時可能也完不成機器人的訓練過程。因此,建議使用資料庫(MONGODB/SQLite)來儲存最終的訓練結果。
2.2 對話階段
對話過程就是根據當前的對話請求,從之前的訓練結果中找到應答語句,併發送給請求方。
如果我們採用最佳匹配策略時,當ChatterBot收到對話請求後,其將遍歷所有的訓練結果,讓其與當前對話請求語句進行相似度計算(餘旋夾角),將訓練結果中與對話請求相似度最高的語句的應答作為當前請求語句的應答並返回。因此,可以發現當訓練語句過大時,將會出現ChatterBot應答請求的時間太長。
2.3 效能優化
經過以上的分析,可以發現ChatterBot在訓練階段、對話階段中均效能較低的問題,其也直接限制了ChatterBot的應用場景的擴充套件。如果能解決ChatterBot儲存的效能問題,將會極大的增加其應用場景。
1. 對話語料的儲存
使用資料庫(MONGODB/SQLite)替換JSON-FILE儲存對話語料,可有效防止程式一次性將對話語料載入記憶體。
當對話語料過大時,如果將對話語料一次性載入記憶體,訓練過程將會出現長時間的阻塞。如果機器效能較低、記憶體空間較小,可能導致機器無法進行後續訓練處理。
2. 對話訓練的優化
ChatterBot為了能夠實現對“任何語言”的處理,未對訓練語料進行深度處理,且也導致了對話過程的效能低下的問題。因此,我們可以根據機器人的應用場景進行語料分詞、構建倒排索引等機制,大幅提升聊天機器人的對話效能。
如果我們構建的機器人只需要支援中文對話,此時完全可以對語料進行分詞處理,並構建倒排索引。當收到對話請求時,也需要對對話請求進行分詞處理,根據分詞結果搜尋倒排索引,再根據搜尋結果進行相似度匹配,將會大大的縮減相似度匹配的規模,大幅提升聊天機器人的效能。