
資料庫索引(B樹,B+樹,雜湊)
資料庫索引是儲存引擎用於快速找到記錄的一種資料結構。 《高效能MySQL》
一. 什麼是索引?
索引的目的就是便於快速查詢。一本書的索引就是目錄,可以讓我們快速定位到要查詢的內容;資料庫的資料是以記錄的方式存在的,所以索引的目的就是便於查詢某一些記錄。
索引型別(常見的資料庫書籍中的關於索引類別的一些稱呼):
①唯一索引:不允許其中任何兩行具有相同值的索引
使用主鍵和候選鍵建立的索引就是唯一索引,因為主鍵和候選鍵都可以確定唯一一個元組,即一張表中不存在相同的主鍵和候選鍵。在MySQL中,當你建立一個主鍵和候選鍵之後,MySQL會為它們分別建立索引。畢竟要想滿足唯一性,依然會在更新資料的時候檢驗是否已經存在該主鍵或者候選鍵,而索引無疑是快速檢驗的標配。
②.主鍵索引:可以認為是特殊的唯一索引,僅利用主鍵建立的索引
③.單一索引:任何一個單一資料項建立的索引
假如有下表【country,city,personNumber】,如果我們想查詢某個國家的人數,我們就應當以國家建立索引,這樣單一資料項建立的索引就是單一索引。
④.複合索引:多個數據項建立的索引
假如有下表【country,city,personNumber】,如果我們想查詢某個城市的人數,我們就應當以【country,city】建立索引,多個數據項建立索引的時候,我們應當指定其排序的先後順序,此處國家應優先排序,城市次之。
⑤.聚簇索引:利用主鍵建立的索引,其物理存放順序與主鍵順序一致。因為資料只有一個物理存放順序,所以一個表只有一個聚簇索引。
在MySQL中,選定主鍵之後將會自動為主鍵建立索引。該索引可以維護主鍵的唯一性。非葉子節點包含了主鍵值,而葉子節點則指向了一條完整的記錄
⑥.非聚簇索引(二級索引,輔助索引):除了聚簇索引之外,其餘所有的索引都是非聚簇索引
非聚簇索引為什麼是二級索引呢?重點在於一個二字。可以料想如果WHERE條件不是根據主鍵進行索引,那麼我們就需要基於該非主鍵建立的索引進行檢索,這樣建立的索引葉子節點中包含了記錄的主鍵,再使用主鍵在聚簇索引中找尋到完整的記錄。可以說進行了兩次B+ Tree查詢而不是一次
⑦.覆蓋索引:一個索引包含(覆蓋)所要查詢的欄位的值,注意覆蓋索引與具體的查詢有關
假如有下表【country,city,personNumber】,如果我們想查詢某個城市的人數,覆蓋索引指的是可以將你想要查詢的列建立在一個索引中,如(國家,城市,人數)作為一個複合索引,此時查詢某一個國家的所有城市利用索引就可以完成,實際上這也相當於完成了聚簇索引的功能
二. 如何快速找到記錄?
說到查詢演算法,最樸實的就是無序排列的遍歷了。在資料量較小的時候(PS:如果資料量較小我想資料庫也不會有這麼快的發展),此方法也不失為一種好的方法,畢竟沒有相應資料結構的維護,插入更新資料的時候就可以再快一點。在學習演算法的書籍中,資料結構總也是扮演著重要的角色。無序排列的資料簡直就是一種佛系的資料結構,不管不顧它就是那樣。一個好的演算法基於一個合適的資料結構的例子比比皆是,堆排序基於堆這種資料結構;二叉搜尋基於一棵構建好的二叉搜尋樹,雜湊查詢基於雜湊表……所以資料庫中為了快速查詢到需要的記錄也需要選擇合適的資料結構。
三. 什麼樣的資料結構適合作為索引?
下面就介紹幾種資料庫中快速查詢記錄的資料結構:
Ⅰ. B+ Tree索引(MySQL,SQL Server,Oracle)
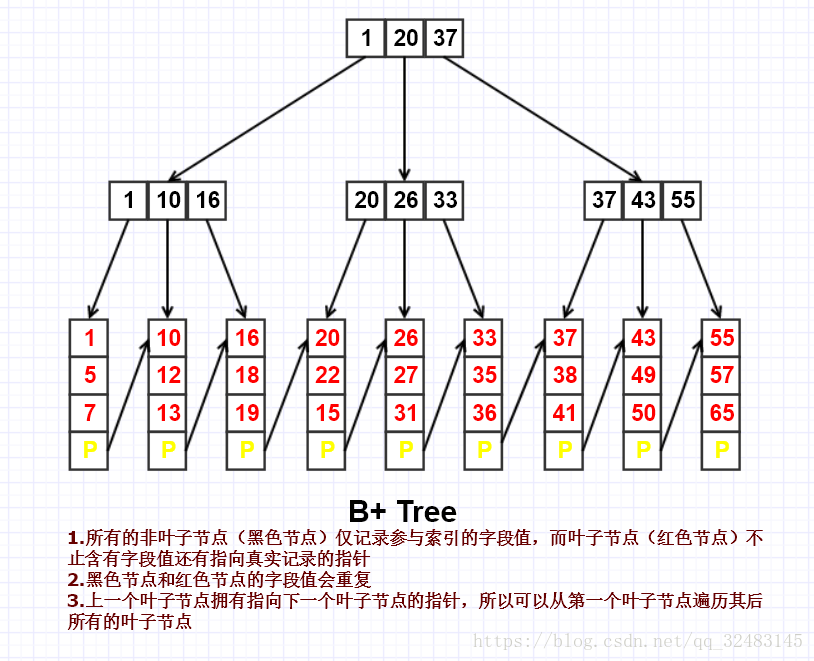
以上為一個3階的B+ Tree,其上的數字我們可以認為使用ID建立起來的單一索引。如果需要使用如下SQL語句進行查詢:
SELECT * FROM STUDENTS WHERE ID=1
這個查詢語句只需要三次查詢就可以找到ID為1的葉子節點,找到存放該條記錄(存放了ID為1的學生的所有屬性)的實體地址,進而找到該條資料。
B+ Tree索引優點
①.全值匹配:指的是和索引中所有列進行匹配。假設以(姓,名,出生日期)三個資料項建立複合索引,那麼可以查詢姓名為張三,出生日期在2000-12-12的人
②.匹配最左字首:假設以(姓,名,出生日期)三個資料項建立複合索引,可以查詢所有姓張的人
③.匹配列字首:假設有姓為司徒,司馬的人,我們也可以查詢第一列的字首部分,如查詢所有以司開頭的姓的人
④.匹配範圍值:可以查詢所有在李和張之間的姓的人,注意範圍查詢只在複合索引的優先排序的第一列。(假設姓名按照拼音排序)
⑤.精確匹配前面列並範圍匹配後一列:可以查詢姓李並出生日期在2000-12-12之後的人或姓名為張三並出生日期在2000-12-12之後的人,注意範圍第一個範圍查詢後面的列無法再使用索引查詢
⑥.只訪問索引的查詢:即查詢只需訪問索引,而無需訪問資料行。(此時應想到索引中的覆蓋索引)
B+ Tree索引缺點
①.如果不是按照索引的最左列開始查詢,則無法使用索引。如無法查詢名為龍的人,也無法查詢在2000-12-12之後出生的人,當然也無法查詢姓中以龍結尾的人(注意為和含有的區別)
②.不能跳過索引中的列:無法查詢姓李並在2000-12-12之後出生的人
③.如果查詢中包括某個列的範圍查詢,則其右邊所有列都無法使用索引優化查詢
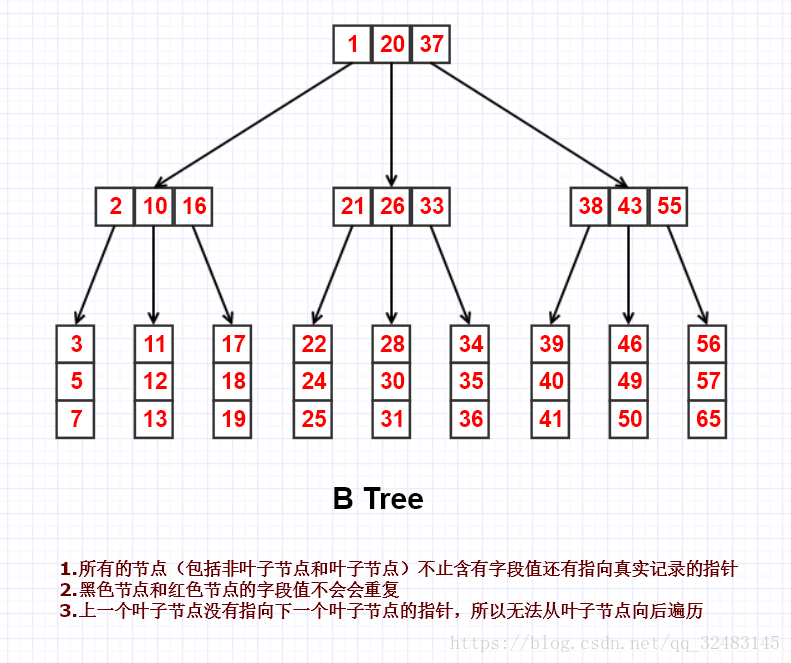
Ⅱ. B Tree索引
Ⅲ.雜湊索引(MySQL,Oracle)
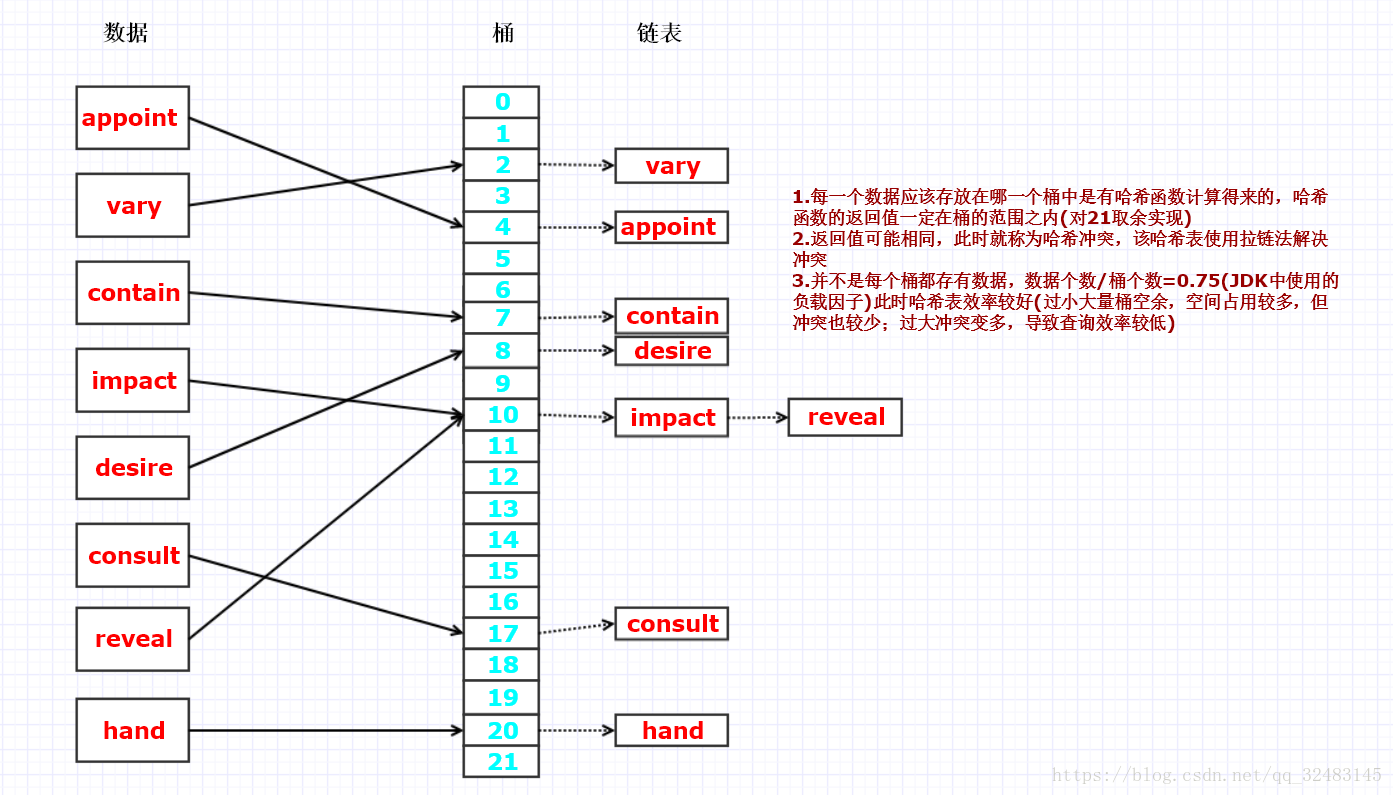
雜湊索引優點
①.快速查詢:參與索引的欄位只要進行Hash運算之後就可以快速定位到該記錄,時間複雜度約為1
雜湊索引缺點
①.雜湊索引只包含雜湊值和行指標,所以不能用索引中的值來避免讀取行
②.雜湊索引資料並不是按照索引值順序儲存的,所以也就無法用於排序和範圍查詢
③.雜湊索引也不支援部分索引列查詢,因為雜湊索引始終是使用索引列的全部資料進行雜湊計算的。
④.雜湊索引只支援等值比較查詢,如=,IN(),<=>操作
⑤.如果雜湊衝突較多,一些索引的維護操作的代價也會更高
參考資料:
《高效能MySQL 第三版》 Baron Schwartz / Peter Zaitsev / Vadim Tkachenko著