
X86/X64處理器體系結構及定址模式
由8086/8088、x86、Pentium發展到core系列短短40多年間,處理器的時鐘頻率幾乎已接近極限,儘管如此,自從86年Intel推出386至今除了增加一些有關流媒體的指令如mmx/sse之外,其他新增的大多數指令都可以從最初的指令集中組合實現同樣的功能,整個程式設計模型維持了約有20多年。
1. 處理器體系結構
1.1. 處理器簡要結構
我們都知道CPU的根本任務就是執行指令,對計算機來說最終都是一串由“0”和“1”組成的序列。CPU從邏輯上可以劃分成3個模組,分別是控制單元、運算單元和儲存單元,這三部分由CPU內部匯流排連線起來。如下所示:

1. 控制單元:控制單元是整個CPU的指揮控制中心,由指令暫存器IR(Instruction Register)、指令譯碼器ID(Instruction Decoder)和操作控制器OC(Operation Controller)等,對協調整個電腦有序工作極為重要。它根據使用者預先編好的程式,依次從儲存器中取出各條指令,放在指令暫存器IR中,通過指令譯碼(分析)確定應該進行什麼操作,然後通過操作控制器OC,按確定的時序,向相應的部件發出微操作控制訊號。操作控制器OC中主要包括節拍脈衝發生器、控制矩陣、時鐘脈衝發生器、復位電路和啟停電路等控制邏輯。
2. 運算單元
3. 儲存單元:包括CPU片內快取和暫存器組,是CPU中暫時存放資料的地方,裡面儲存著那些等待處理的資料,或已經處理過的資料,CPU訪問暫存器所用的時間要比訪問記憶體的時間短。採用暫存器,可以減少CPU訪問記憶體的次數,從而提高了CPU的工作速度。但因為受到芯片面積和整合度所限,暫存器組的容量不可能很大。暫存器組可分為專用暫存器和通用暫存器。專用暫存器的作用是固定的,分別寄存相應的資料。而通用暫存器用途廣泛並可由程式設計師規定其用途,通用暫存器的數目因微處理器而異。這個是我們以後要介紹這個重點,這裡先提一下。
我們將上圖細化一下,可以得出CPU的工作原理概括如下:
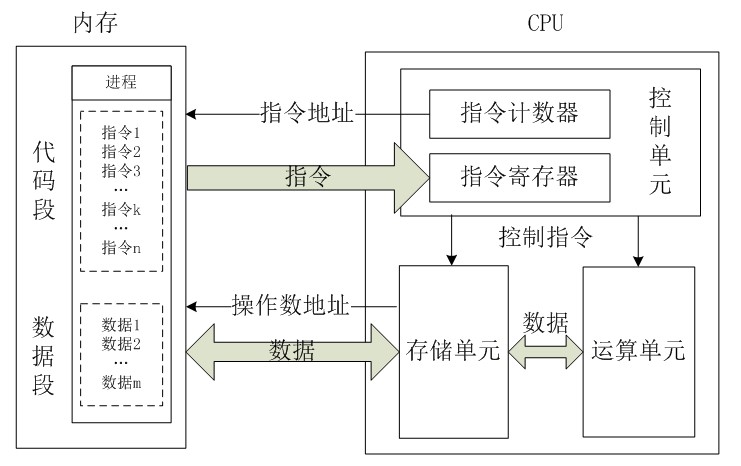
總的來說,CPU從記憶體中一條一條地取出指令和相應的資料,按指令操作碼的規定,對資料進行運算處理,直到程式執行完畢為止。
1.2. 暫存器簡要結構
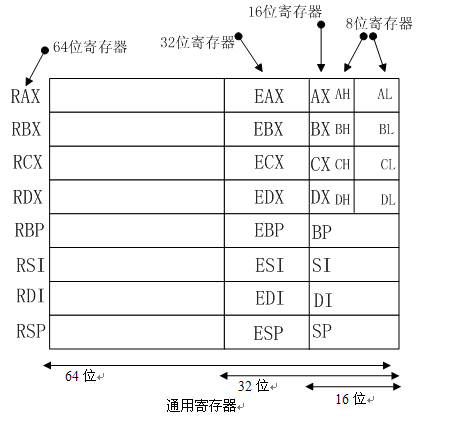

以上所列出的一些通用暫存器(注:其中RSP為專用暫存器,之所以把它放在通用暫存器組中只是為了方便記憶整個模型),除了資料位寬度不同之外,並無多大差別:
- RAX(累加器):RAX如果是8/16/32位定址,則只改變該暫存器的一部分。累加器用於乘法、除法及一些調整指令,同時也可以儲存儲存單元的偏移地址。
- RBX(基址):用於儲存儲存單元的偏移地址,同時也能定址儲存器資料,作為偏移地址訪問資料時預設使用資料段基址DS作為段字首。
- RCX(計數):可儲存訪問儲存單元的偏移地址,或在串指令(REP/REPE/REPNE)以及移位、迴圈和LOOP/LOOPD指令中用作計數器。
- RDX(資料):可使用RDX/EDX/DX/DH/DL定址,同時作為通用暫存器也用於儲存乘法形成的部分結果或者除法之前的部分被除數,也可用於定址儲存單元。
- RBP(基指標):可用RBP/EBP/BP定址,同時作為偏移地址訪問儲存單元時預設使用堆疊段基址SS作為段字首。
- RDI(目的變址):可用RDI/EDI/DI定址,常用於在串指令中定址目的資料串。
- RSI(源變址):如RDI一樣,RSI也可作為通用暫存器使用,通常為串指令定址源資料串。
段暫存器CS、DS、ES、SS、FS、GS以及RSP為專用暫存器,以下是這些暫存器的概要描述:
- RSP(堆疊指標):RSP定址稱為堆疊的儲存區,通過該指標存取堆疊資料。用作16位暫存器時使用SP,如果是32位則為ESP。
- CS(程式碼段):程式碼段暫存器存放程式所使用的程式碼在儲存器中的基地址。 • DS(資料段):存放資料段的基地址。
- ES(附加段):該段暫存器通常在串指令(LODS/STOS/MOVS/INS/OUTS)中使用,主要用於在儲存器中將資料進行成塊轉移。
- SS(堆疊段):為堆疊定義一個儲存區域。主要用來存放過程呼叫所需引數、本地區域性變數以及處理器狀態等。
- FS與GS:這兩個段暫存器是386~Core2中新增的段暫存器,以允許程式訪問附加的儲存器段。可以將其視為“通用的段暫存器”,通過將段的基地址存入這兩個暫存器中可以實現自定義的定址操作,從而增加了程式設計的靈活性。
每一個暫存器都有一個”可見”部分和一個”隱藏”部分。(這個隱藏部分有時也指一個”描述符快取”(descriptor cache)或者”陰影暫存器”(shadow register))。當一個段選擇器被載入到段暫存器的可見部分,處理器也會自動把基址,段界限,和段描述符中的訪問控制資訊載入到段暫存器的隱藏部分。把資訊快取在段暫存器(可見和隱藏部分)允許處理器不經過額外的匯流排迴圈(bus cycles)去段描述符總讀取基址和界限來轉換地址。當描述符表發生了更改,軟體有義務重新載入段暫存器。如果不這樣做,段暫存器中使用的老段描述符還是會繼續使用。
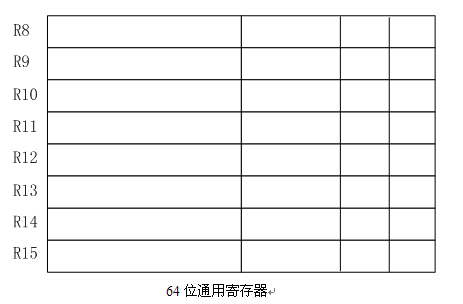
如上圖所示,在Pentium4及更高型號處理器中增加了R8~R15這8個64位通用暫存器,這些新增的64位暫存器仍支援按位元組、字、雙字或四字方式定址,而不同之處在於只有最右邊的資料位可以用來作為單獨的一個位元組/字等。注意在使用這些新增暫存器的其中一個部分時需要在暫存器末尾新增控制字,例如:
- mov R11D, R8D ;其中字母D用於表示雙字訪問
- ;也可以將D改為B或者W,B表示位元組訪問,W表示字訪問
- ;如果不加任何控制字則使用整個暫存器

RIP定址程式碼段中當前執行指令的下一條指令,當處理器工作在真實模式下時使用16位的IP暫存器,當工作於保護模式時則使用32位的EIP。指令指標可由轉移指令或呼叫指令修改。需要注意的是,在64位模式中由於處理器包含40位地址匯流排,所以總共可以定址240=1TB的記憶體。
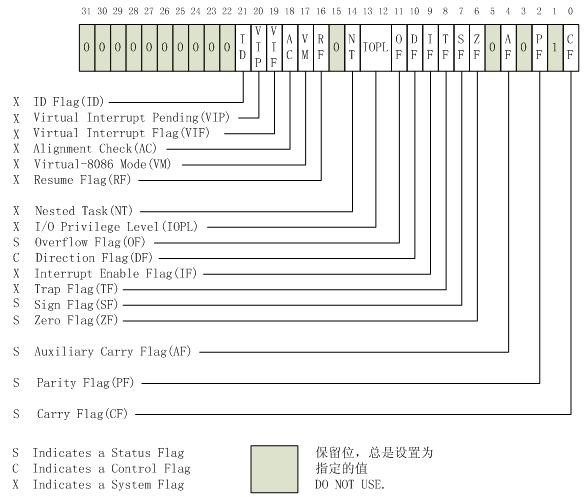
EFLAGS(program status and control) register主要用於提供程式的狀態及進行相應的控制,在64-bit模式下,EFLGAS暫存器被擴充套件為64位的RFLGAS暫存器,高32位被保留,而低32位則與EFLAGS暫存器相同。
32位的EFLAGS暫存器包含一組狀態標誌、系統標誌以及一個控制標誌。在x86處理器初始化之後,EFLAGS暫存器的狀態值為0000 0002H。第1、3、5、15以及22到31位均被保留,這個暫存器中的有些標誌通過使用特殊的通用指令可以直接被修改,但並沒有指令能夠檢查或者修改整個暫存器。通過使用LAHF/SAHF/PUSHF/POPF/POPFD等指令,可以將EFLAGS暫存器的標誌位成組移到程式棧或EAX暫存器,或者從這些設施中將操作後的結果儲存到EFLAGS暫存器中。在EFLAGS暫存器的內容被傳送到棧或是EAX暫存器後,可以通過位操作指令(BT, BTS, BTR, BTC)檢查或修改這些標誌位。當呼叫中斷或異常處理程式時,處理器將在程式棧上自動儲存EFLAGS的狀態值。若在中斷或異常處理時發生任務切換,那麼EFLAGS暫存器的狀態將被儲存在TSS中 【the state of the EFLAGS register is saved in the TSS for the task being suspended.】 ,注意是將要被掛起的本次任務的狀態。
EFLAGS暫存器的狀態標誌(0、2、4、6、7以及11位)指示算術指令(如ADD, SUB, MUL以及DIV指令)的結果。位於EFLAGS暫存器的第10位DF標誌(DF flag) 控制串指令(MOVS, CMPS, SCAS, LODS以及STOS)。設定DF標誌使得串指令自動遞減(從高地址向低地址方向處理字串),清除該標誌則使得串指令自動遞增。EFLAGS暫存器中的系統標誌以及IOPL域(System Flags and IOPL Field) 用於控制作業系統或是執行操作,它們不允許被應用程式所修改。
2. 處理器工作及定址模式
對於一根實際的、實實在在的、物理的、可看得見、摸得著的記憶體條而言,處理器把它當做8位一個位元組的序列來管理和存取,每一個記憶體位元組都有一個對應的地址,我們叫它實體地址,用地址可以表示的長度叫做定址空間。而CPU是如何去訪問記憶體單元裡的資料的方式就叫做定址。
2.1. 真實模式
8086得CPU在記憶體定址方面第一次引入了一個非常重要的概念—-段。在8086之前都是4位機和8位機的天下,那是並沒有段的概念。當程式要訪問記憶體時都是要給出記憶體的實際實體地址,這樣在程式原始碼中就會出現很多硬編碼的實體地址。段暫存器的產生源於Intel 8086 CPU體系結構中資料匯流排與地址匯流排的寬度不一致。也就是為了實現16位8086 CPU實現20位地址匯流排位寬。為了支援分段機制,Intel在8086的CPU裡新增了4個暫存器,分別是程式碼段CS,資料段DS,堆疊段SS和其他ES。這樣一來,一個實體地址就由兩個部分組成,分別是“段地址”:“段內偏移量”。在真實模式中,通常定址時都是通過段暫存器+通用暫存器,即基址+變址的方式進行定址。例如,ES=0x1000,DI=0xFFFF,那麼這個資料ES:DI在記憶體裡的絕對實體地址就是:
AD(Absolute Address)=(ES)*(0x10)+(DI)=0x1FFFF
就是講段基地址左移4位然後加上段內偏移量就得到了實體記憶體裡的絕對地址,經過這麼一個變換,就可以得到一個20位的地址,8086就可以對20位的1M記憶體空間進行定址了。如下:

很明顯,這種方式可以定址的最高地址為0xFFFF:0xFFFF,其地址空間為0x00000~0x10FFEF,因為8086的地址匯流排是20位,最大隻能訪問到1MB的實體地址空間,即實體地址空間是0x00000~0xFFFFF。當程式訪問0x100000~0x10FFEF這一段地址時,因為其邏輯上是正常的,CPU並不會認為其訪問越界而產生異常,但這段地址確實沒有實際的實體地址與其對應,怎麼辦?此時CPU採取的策略是,對於這部分超出1M地址空間的部分,自動將其從物理0地址處開始對映。也就是說,系統計算實際實體地址時是按照對1M求模運算的方式進行的,在有些技術文獻裡你會看到這種技術被稱之為wrap-around。還是通過一幅圖來描述一下吧:
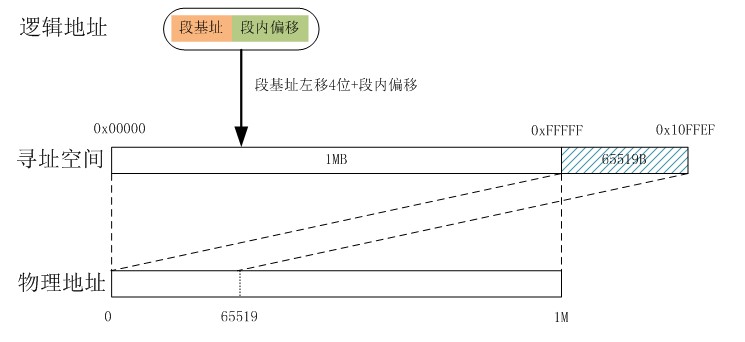
根據前面的講解我們可以發現段基址有個特徵,其低4位全為0,也就是說每個段的起始地址一定是16的整數倍,這是分段的一個基本原則。這樣每個段的最小長度是16位元組,而最大長度只能是64KB。這裡我們可以計算一下,1MB的實體地址空間能劃分成多少個段。
如果每個段的長度為16位元組,這樣1MB實體地址空間最多可以劃分成64K個段;
如果每個段的長度為64KB,那麼1MB的實體地址空間最多能劃分成16個段。
8086這種分段基址雖然實現了定址空間的提升,但是也帶來一些問題:
- 同一個實體地址可以有多種表示方法。例如0x01C0:0x0000和0x0000:0x1C00所表示的實體地址都是0x01C00。
- 地址空間缺乏保護機制。對於每一個由段暫存器的內容確定的“基地址”,一個程序總是能夠訪問從此開始64KB的連續地址空間,而無法加以限制。另一方面,可以用來改變段暫存器內容的指令也不是什麼“特權指令”,也就是說,通過改變段暫存器的內容,一個程序可以隨心所欲地訪問記憶體中的任何一個單元,而絲毫不受限制。不能對一個程序的記憶體訪問加以限制,也就談不上對其他程序以及系統本身的保護。與此相應,一個CPU如果缺乏對記憶體訪問的限制,或者說保護,就談不上什麼記憶體管理,也就談不上是現代意義上的中央處理器。
8086和後來的80186,這種只能訪問1MB地址空間的工作模式,我們將其稱之為“真實模式”。我的理解就是“實際地址模式”,因為通過段基址和段偏移算出來的地址,經過模1MB之後得出來的地址都是實際記憶體的實體地址。
雖然現在CPU已經發展到了64位的酷睿6代,但是仍然保持著真實模式這個工作模式。CPU的真實模式是為了與8086處理器相容而設定的。在真實模式下,CPU處理器就相當於一個快速的8086處理器。CPU處理器被複位或加電的時候以真實模式啟動。這時候處理器中的各暫存器以真實模式的初始化值工作。CPU處理器在真實模式下的儲存器定址方式和8086基本一致,由段暫存器的內容乘以16作為基地址,加上段內的偏移地址形成最終的實體地址,這時候它的32位地址線只使用了低20位,即可訪問1MB的實體地址空間。在真實模式下,CPU處理器不能對記憶體進行分頁機制的管理,所以指令定址的地址就是記憶體中實際的實體地址。在真實模式下,所有的段都是可以讀、寫和執行的。真實模式下CPU不支援優先順序,所有的指令相當於工作在特權級(即優先順序0),所以它可以執行所有特權指令,包括讀寫控制暫存器CR0等。這實際上使得在真實模式下不太可能設計一個有保護能力的作業系統。真實模式下不支援硬體上的多工切換。真實模式下的中斷處理方式和8086處理器相同,也用中斷向量表來定位中斷服務程式地址。中斷向量表的結構也和8086處理器一樣,每4個位元組組成一箇中斷向量,其中包括兩個位元組的段地址和兩個位元組的偏移地址。應用程式可以任意修改中斷向量表的內容,使得計算機系統容易受到病毒、木馬等的攻擊,整個計算機系統的安全性無法得到保證。
2.2. 保護模式(IA-32模式)
由於8086的上述問題,1982年,Intel在80286的CPU裡,首次引入的地址保護的概念。也就是說80286的CPU能夠對記憶體及一些其他外圍裝置做硬體級的保護設定(實質上就是遮蔽一些地址的訪問)。自從最初的x86微處理器規格以後,它對程式開發完全向下相容,80286晶片被製作成啟動時繼承了以前版本晶片的特性,工作在真實模式下,在這種模式下實際上是關閉了新的保護功能特性,因此能使以往的軟體繼續工作在新的晶片下。後續的x86處理器都是在計算機加電啟動時都是工作在真實模式下。
也就是說,在保護模式下,程式不能再隨意的訪問實體記憶體了,有些記憶體地址CPU做了明確的保護限制。在這些要求下,286時代的“根據段暫存器確定段基址”方法已經行不通了,我們需要的不僅僅是基址,還需要訪問許可權等額外的資訊,而且我們不想把具體的基址暴露給使用者。
2.2.1. 段描述符
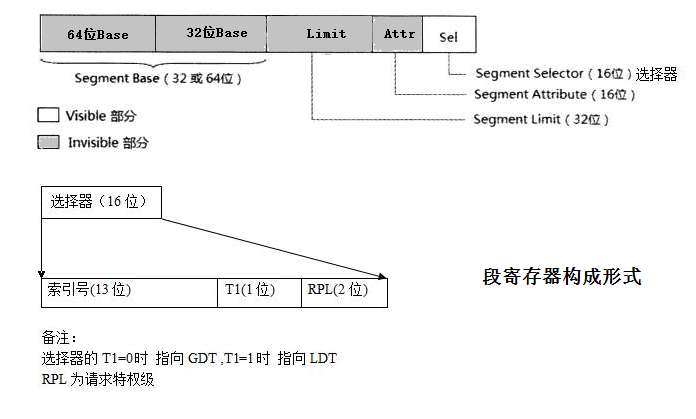
為了解決這些問題,intel引入一箇中間結構體,段描述符。並增設了兩個暫存器:GDTR (global descriptor talbe register)指向全域性段描述符陣列(表);LDTR (localdescriptor table register)執行區域性段描述符陣列(表)。而6個段暫存器,CS/DS/SS/ES包括後來的FS/GS,其內容不在用作基址,而是用作索引去段描述符陣列中查詢對應的段描述符。段描述符佔8個位元組,其定義以及其中各個標誌位的定義如下:

段限制欄位(Segment limit field) 確定段的大小。處理器將兩個段限制欄位放在一起形成一個20-bit的值。根據G(粒度(granularity))標記位設定的不同,處理器有兩種方式解析段限制。
- 如果G標記位被清除了,段大小範圍從1 byte到1 MByte,步長為一個位元組。
- 如果G欄位設定了,段大小範圍從4 KBytes到4GBytes,步長為4-KByte。
處理器有兩種方式使用段限制,取決於段是向上擴充套件段(expand-up
segment)還是向下擴充套件段(expand-down
segment)。對於向上擴充套件段,邏輯地址的偏移量範圍從0到段大小限制。大於段限制的偏移量會產生一個通用保護異常(GP,對於除了SS之外的段)或者棧錯誤異常(stack-fault
exception)(SS,對於SS段)。對於向下擴充套件段,段限制有一個反向函式;偏移量範圍從段限制加上1到加上FFFFFFFFH或者FFFFH,取決於B標記位的設定。小於或者等於段限制的偏移量會產生一個通用保護異常或者棧錯誤異常。在向下擴充套件段中申請新的記憶體的時候,會減少段限制欄位的值,並且新申請的空間在段地址空間的底部而不是頂部。IA-32
架構棧總是向下增長的,使這個機制對於擴充套件段來說非常便利。
基址欄位(Base address fields) 在4-GByte線性地址空間中定義了段基址byte0的位置。處理器將三個基址欄位加在一起形成一個32-bit的值。段基址需要在16-byte的邊界對齊。對染16-byte對齊並不是必須的,但是在16-byte邊界對齊的程式碼和資料的程式有最佳表現。
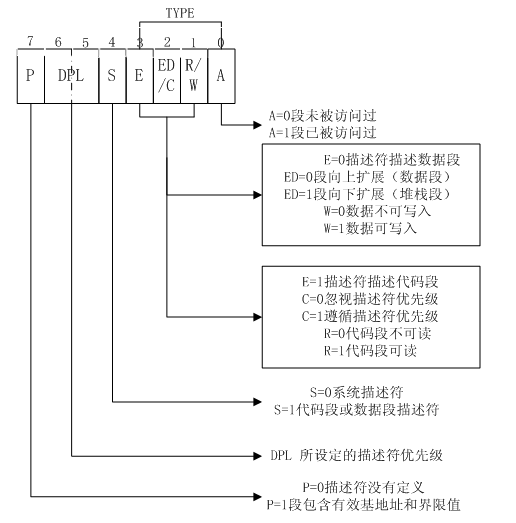
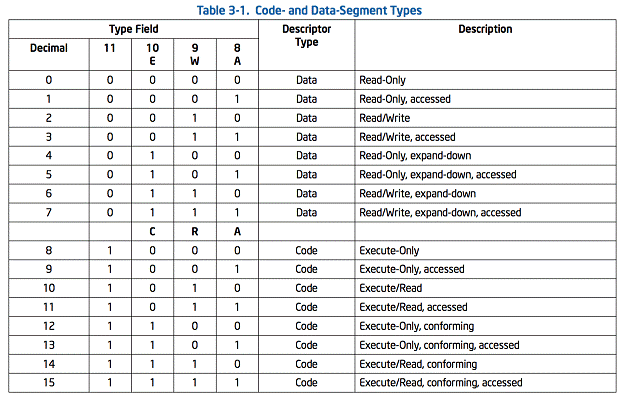
型別欄位(Type field) 指定了段和門的型別並且指定了段的訪問方式以及段資料增長方向。對這個欄位的解釋取決於描述符型別是應用(程式碼和資料)描述符或是系統描述符。型別欄位的編碼在程式碼,資料,和系統描述符中是不同的。
S(描述符型別(descriptor type))標識 決定了這個段描述符是一個系統段(S標記位清0)或是一個程式碼或者資料段(S標記位設定了)。
DPL(描述符優先順序(descriptor privilege level))欄位 決定了段的特權級別。特權級別範圍從0到3,其中0是最大特權級別。DPL用來控制對段的訪問的。
P(segment-present) flag 決定了是否這個段現在是在記憶體(set)還是不在(clear)。如果標記位為clear,如果有段選擇器指向段描述符載入到段暫存器的時候,處理器將會產生一個段不在異常(segment-not-present exception)(NP)。記憶體管理軟體使用這個標記位來控制當前時間哪些段真正的載入到實體記憶體。它在分頁虛擬記憶體之外提供了一個額外的控制。
下圖展示了當segment-present是clear狀態時,段描述符的格式。當這個標記位是clear,作業系統或者執行指令可以直接使用標記為”可用(Avilable)”的位置來儲存自己的資料,比如缺失段下落的資訊。
D/B(操作的預設大小/棧指標大小和/或上界)標記位 在段描述符是一個可執行程式碼段,一個向下擴充套件段,或是棧段不同情況下,表現出不同的方法。(在32-bit程式碼和資料段中,應該總是被設定成1,而在16-bit程式碼和資料段中總是0);
- 可執行程式碼段(Executable code segment)
此時標記位也稱為D標記,它決定了段中有效地址和指標運算子的預設大小。如果標記位是set,認定是一個32-bit地址和32-bit或者8-bit的運算子;如果是clear,認定是一個16-bit的地址和16-bit或者8-bit運算子。 - 棧段(Stack segment)(通過SS暫存器指向資料段)
此時標記也稱為B(big)標記,它決定了在隱式棧操作使用中棧指標的大小(比如pushes,pops,和calls)。如果標記為set,會使用一個儲存在32-bit
ESP暫存器的32-bit棧指標;如果標記是clear,會是歐諾個一個儲存在16-bit的SP暫存器的16-bit棧指標。如果棧段被設定成向下擴充套件的資料段,B標記也指定了棧段的上界。 - 向下擴充套件資料段(Expand-down data segment)
此時標記也稱為B標記,它指定了段的上界。如果標記是set,上界就是FFFFFFFFH(4
GBytes),否則(clear)就是FFFFH(64 KBytes)。

G(粒度(grandularity))標記位 決定段限制的縮放比例。如果粒度標記是clear,段限制是以位元組為單元的;如果是set,段限制是以4-KByte為單元的。(這個標記並不影響基址的粒度。)當粒度標記位是set的,檢查偏移量有沒有超過段限制時,不會測試一個偏移量中最不重要12個位(the twelve least significant bits of an offset are not tested when checking the offset against the segment limit. )。比如,當粒度標記是set的,段限制為0意味著有效偏移量是0到4095。
L(64-bit 程式碼段)標記 在IA-32e模式,段描述符第二個雙字(doubleword)中的bit21決定了一個程式碼段是否包含了原生64-bit程式碼。值為1決定了程式碼段中的指令按照64-bit模式執行。值為0決定了程式碼段中的執行按照相容模式執行。如果L-bit是set的,D-bit必須是clear的。當不在IA-32e模式或者非程式碼段,bit21是保留的,而且必須是0。
可用與保留位(Available and reserved bits) 段描述符的第二個雙字的bit20對系統軟體是可用的。
通過段描述符,我們能夠得到如下資訊:
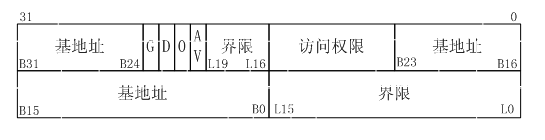
- 段的基址,由B31-B24/B23-B16/B15-B0構成,一共32位,基址可以是4GB空間中任意地址;
- 段的長度,由L19-L16/L15-L0構成,一共20位。如果G位為0,表示段的長度單位為位元組,則段的最大長度是1M,如果G位為1,表示段的長度單位為4kb,則段的最大長度為1M*4K=4G。假定我們把段的基地址設定為0,而將段的長度設定為4G,這樣便構成了一個從0地址開始,覆蓋整個4G空間的段。訪存指令中給出的“邏輯地址”,就是放到地址總線上的“實體地址”,這有別於“段基址加偏移”構成的“層次式”地址(其實應該算作“層次式”地址的特例),所以intel稱其為flat地址即平面地址。
- 段的型別,程式碼段還是資料段,可讀還是可寫
描述符表儲存在由作業系統維護著的特殊資料結構中,並且由處理器的記憶體管理硬體來引用。這些特殊結構應該儲存在僅由作業系統軟體訪問的受保護的記憶體區域中,以防止應用程式修改其中的地址轉換資訊。同時,為了避免每次訪問記憶體時都通過段暫存器去查表、去讀和解碼一個段描述符,每次更改段暫存器的內容時,CPU將段暫存器指向的段描述符中的段基址、長度以及訪問控制資訊等載入到CPU中的“影子結構”中快取起來。後續對該段的訪問控制都通過“影子結構體”來進行。
但是如果可以修改GDTR和LDTR的內容呢?我們不就可以隨便指定GDTR到我們自己偽造的段描述陣列從而掌控程式嗎?為了解決這個問題,intel將訪問這兩個暫存器的專門指令設為特權指令(LGDT/LLDT,SGDT/SLDT),這些指令只有當CPU處於系統狀態(即在作業系統核心中)才能使用,使用者空間無法訪問暫存器的內容。這樣一來,工作1-2就完成了。
2.2.1.1. 段描述符例項
以下是一個典型的程式碼段描述符:
- 基地址域的資料位寬度為16+8+8=32,該域指示儲存器段的起始位置。
- 20位的界限域指示段的最大偏移量,通常與描述符中的特徵位(G位,也稱為粒度位)一起使用,當G置位時,將在20位的界限域的尾部新增FFFH形成一個32位的值。
- AV位指示段是否有效,當AV=1時指示當前儲存器段有效,反之則無效,該位由作業系統使用,但Linux系統通常將其所省略。
- 偏移量的資料位寬度為32時D位被置位,為16時該位被清零。
下圖詳細解釋了訪問許可權域的各個位:
下表為Linux核心對段描述符的典型設定方式:
| 段 | 基地址 | G | 界限 | S | TYPE | DPL | D | P |
|---|---|---|---|---|---|---|---|---|
| 使用者程式碼段 | 0x0000 | 0000 | 1 | 0xF FFFF | 1 | 10(0x1010) | 3 | 1 |
| 使用者資料段 | 0x0000 | 0000 | 1 | 0xF FFFF | 1 | 2(0x0010) | 3 | 1 |
| 核心程式碼段 | 0x0000 | 0000 | 1 | 0xF FFFF | 1 | 10(0x1010) | 0 | 1 |
| 核心資料段 | 0x0000 | 0000 | 1 | 0xF FFFF | 1 | 2(0x0010) | 0 | 1 |
上述設定分別與Linux核心中的巨集__USER_CS,__USER_DS,__KERNEL_CS,__KERNEL_DS相對應。
- 4個段的基地址均被設定為0,這意味著在Linux下邏輯地址即為線性地址。
- 界限為0xF FFFF且粒度位G被置位為1,因此所有段的大小最多可達4GB。
- D位置位,所以偏移量的資料位寬度為32。
- P位被置位為1,指示所有段的基地址和界限域均是有效的。
- S位被置位,指示該描述符為程式碼段或資料段描述符。
- DPL域指示段的優先順序,上述設定方式表示將最高優先順序00分配給核心程式碼/資料段,而將最低優先順序11分配給使用者程式碼/資料段。
- 根據TYPE域中的E位指示當前段為程式碼段或是資料段。在使用者/核心程式碼段描述符中,C=0表示忽視描述符優先順序,R=1表示當前段可讀,A=0表示當前段尚未被訪問。相應地,在使用者/核心資料段描述符中,ED=0表示該段將向上擴充套件,W=1表示資料可寫入,A=0同樣表示當前段尚未被訪問過。
2.2.2. 段選擇符
16位段暫存器中的內容,稱之為段選擇符,除了高13位用作段描述符陣列的索引外(因此理論上段描述符陣列最多可以8192個元素),低3位有其他的用途,如下所示:
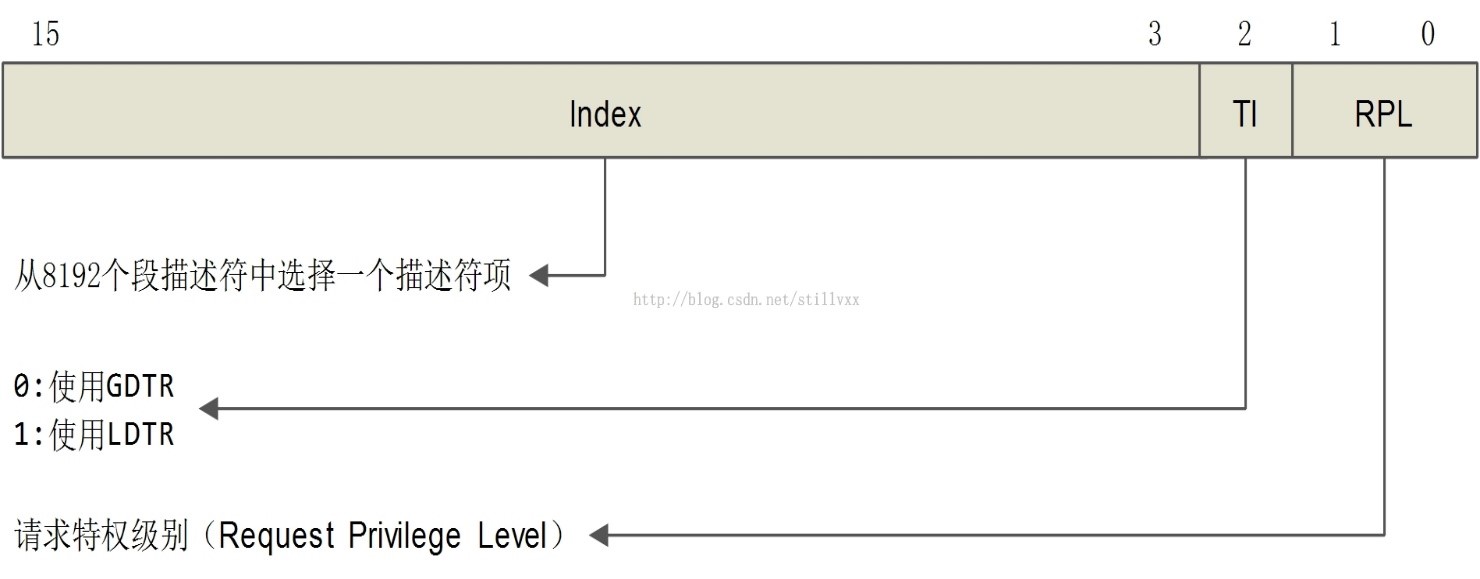
Index (Bits3 through 15) – 從GDT或者LDT中的8192個描述符中選擇一個。處理器將index的值乘以8(段描述符中的位元組數),然後加上GDT或者LDT的基址(各自從GDTR或者LDTR暫存器)。
由於有兩個描述符陣列,所以TI(Table Index)位用來確定從哪個陣列中索引。
在前面的段描述符結構中,我們看到了特權級別欄位(DPL),為什麼還需要在這裡設定一個特權欄位(RPL)呢?
intel的CPU有四種特權級別,0級最高,3級最低。每條指令都有其適用級別,如前述的LGDT指令要求0級特權,通常使用者的應用程式都是3級。Linux/windows中對CPU特權進行了簡化,只區分使用者級別和系統級別,分別對應3級和0級,這是後話。一般應用程式的當前級別由其程式碼段的區域性段描述符(即用段暫存器CS索引LDTR指向的區域性描述符項)中的dpl(descriptor privilege level)決定,當然,每個段描述符的dpl都是在0級狀態下由核心設定的。而全域性段描述符中的dpl有所不同,它表示所需的級別。段選擇符中的rpl也表示請求級別。這樣,當我們需要改變某個段暫存器(比如資料段DS)中的內容(段選擇符)來訪問一款新段空間時,CPU要做許可權檢查:
- 當前程式有權訪問新的段嗎?比較當前程式的當前級別與新段描述符中的dpl
- 新的段選擇符有權訪索引新的段嗎?比較新的段選擇符中的rpl與新段描述符的dpl。
當然,具體的許可權檢查比這要複雜,設計到段描述符中C位的取值,詳情情況請參考其他資料。
至此,工作1-3都完成了,保護模式已經建立了,我們來看看當訪存指令給出“邏輯地址”時,CPU如何將其轉換為“實體地址”送往地址匯流排:
- 根據指令性質確定該使用哪個段暫存器,如跳轉指令則目標地址在程式碼段CS,取資料的指令目標地址在資料段;
- 根據段暫存器的內容找到對應的段描述符。其實這一步不用找,前面介紹過了,段暫存器對應的段描述符已經在CPU的“影子結構”中了。
- 從段描述符中獲得基址
- 將指令中的“邏輯地址”與段的長度比較,確定是否越界
- 根據指令的性質和段描述符中的訪問許可權確定是否越權
- 將指令中的“邏輯地址”作為位移,與基地址相加得到實際的“實體地址”
GDT的第一個實體不是處理器使用的。一個指向GDT第一個實體的段選擇器(意思是說,一個index是0,且TI標記為0的段選擇器)是作為一個”空段選擇器”(null segment selector)。當一個帶有空選擇器的段暫存器(除了CS和SS之外)被載入了,處理器並不會產生異常。但是當一個帶有空選擇器的段暫存器被用來訪問記憶體的時候,會產生異常。一個空選擇器可以用來初始化未使用的段暫存器。當CS或者SS暫存器帶有空段選擇器時,會產生一個通用保護異常(general-protection exception)(GP)。
2.2.3. 程式碼和資料段描述符型別
當段描述符中S(段描述符(descriptor type))標記是設定的表示這個描述符是一個數據或者程式碼段的描述符。型別欄位中的最高順序位(描述符第二個雙字的bit11)決定了這個段是一個數據段(clear)還是一個程式碼段(set)。
當是一個數據段,型別欄位的三個低位(bits 8,9 and 10)視為訪問(accessed)(A),可寫(write-enable)(W),和擴充套件方向(expansion-direction)(E)的。查看錶3-1,關於程式碼和資料段總型別欄位的編碼。資料段只能是可讀或者讀寫段,由write-enable位決定。
棧段是必須可讀寫的資料段。將一個不可寫的資料段載入到SS暫存器將會產生一個通用保護異常(GP)。如果棧段的大小需要動態改變,棧段需要是一個向下擴充套件的資料段(expansion-direction)標記是set的)。這裡,動態改變段限制將會使棧空間被加在棧的底部。如果想要靜態的棧段空間大小,棧暫存器可能是向上擴充套件型別或者向下擴充套件型別。
訪問位(accessed bit)決定了這個段定義了從上次作業系統或者執行指令clear這個位之後,這個段是否是可以訪問的。無論何時處理器將段選擇符載入到段暫存器,它都會設定這個位,假定包含這個段描述符的記憶體支援處理器寫。這個位會保持set狀態直到顯式的clear。這個位可以在虛擬記憶體管理中使用和在debugging中使用。
對於程式碼段,型別欄位中三個低順序位分別意味著可訪問(accessed)(A),可讀(read enable)(R),和一致(conforming)(C)。程式碼段可以使只執行(execute-only)或者可執行/讀取(execute/read),取決於可讀位的設定。一個可執行/讀取段可能用在常量和靜態資料都已經被放置在指令程式碼的ROM中。資料可能通過使用重寫字首的CS指令或者在資料段暫存器(DS,ES,FS or GS暫存器)中加程式碼段的段選擇器來讀取。在保護模式下,程式碼段是不可寫的。
程式碼段可以是一致的(conforming)或者是非一致的(nonconforming)。將執行程式轉換成更加特權的(more-privileged)一致段允許程式碼繼續在當前特權級別執行。在不同特權級別的非一致段中進行轉換會導致一個通用保護異常(GP),除非使用一個呼叫門或者任務門。不訪問受保護功能和處理某些型別的異常(比如,除異常或者溢位)的系統工具可能被載入在一致程式碼段中。需要避免被從低特權等級的程式和過程中執行的系統工具需要被放置在非一致程式碼段。
注意
- 無論觸發段是一致的還是非一致的,執行過程不能通過一個呼叫(call)或者一個跳轉(jump)到一個低特權的(特權等級的數字更大)程式碼段。試圖進行這樣的操作會導致一個通用保護異常。
- 所有的資料段都是非一致的,意味著它們無法在低特權的程式或者過程中被訪問。然而,不同於程式碼段,資料段可以不經過使用一個特殊的訪問門被更高特權程式或者過程訪問。如果GDT或者LDT的段描述符被放置在ROM中,如果軟體或者處理器想要更新(寫入)基於ROM(ROM-based)段描述符,處理器會進入一個模糊的迴圈。設定所有ROM中的段描述符的可訪問位可以避免這個問題。當然,移除試圖修改ROM中段描述符的作業系統或者可執行程式碼(也可以避免這個問題)。
2.2.4. 系統描述符型別
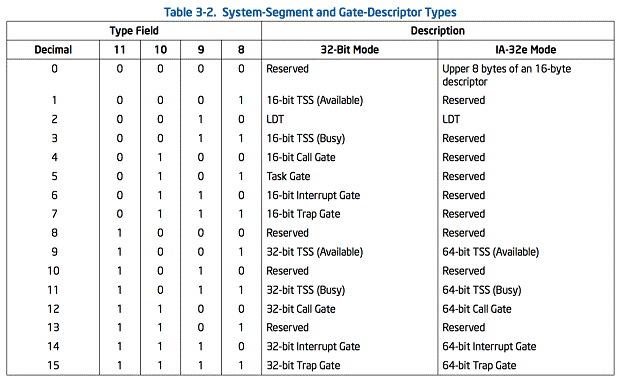
當段描述符中的S(描述符型別(descriptor type))標誌位是clear,描述符型別是系統描述符。處理器能識別下列型別的系統描述符:
- 本地描述符-表(local descriptor-table)(LDT)段描述符
- 任務狀態段(task-state segment)(TSS)描述符
- 門呼叫(call-gate)描述符
- 中斷門(interrupt-gate)描述符
- 陷阱門(trap-gate)描述符
- 任務門(task-gate)描述符
這些描述符型別分為兩類:系統段(system-segment)描述符和門(gate)描述符gate。系統段描述符指向系統段(LDT和TSS段)。門描述符分為放置有指向程式碼段中的過程實體的門(call,interrupt, and trap gates)或者放置TSS的段選擇器的門(task gates)。
表3-2顯示的是系統段描述符和門描述符中的型別欄位的編碼。注意在IA-32e模式下,系統描述符是16位元組的而不是8位元組。
2.2.5. 段描述符表
一個段描述符表是一個段描述符的陣列(參見圖3-10)。一個描述表的長度是可變的,並且最多可以容納8192(2^13)個8-byte的描述符。有下面兩種描述符表:
- 全域性描述符表(the global descriptor table)(GDT)
本地描述附表(the local descriptor tables)(LDT)
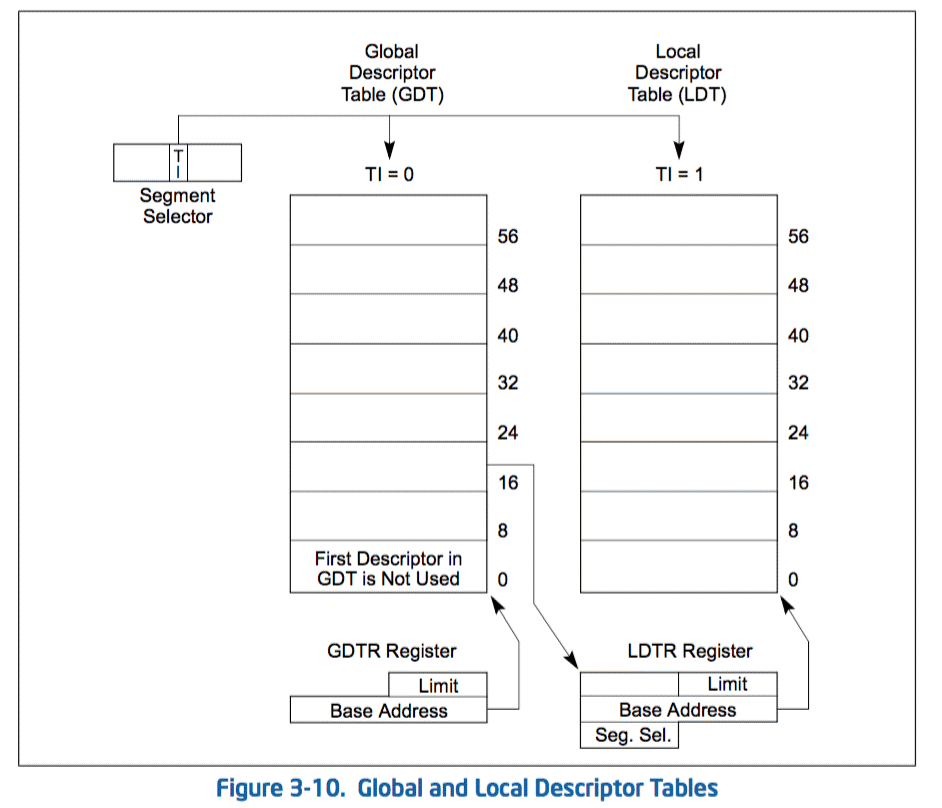
每一個系統必須定義一個GDT提供給系統裡面所有的程式和任務。定義一個或者多個LDT是可選項。比如,可以給每一個正在執行的獨立的任務定義一個LDT,或者一些或者所有任務共享一個相同的LDT。
GDT本身不是段;相反的,它是一個線性地址空間裡面的資料結構。GDT的線性地址的基址和限制必須被載入到GDTR暫存器中。GDT的基址必須是8位元組邊界對齊的,以滿足處理器的最佳表現。GDT的限制值是通過位元組描述的。和段一樣,通過將限制值和基址相加可以得到最後一個地址的有效位元組。限制值為0實際上意味著一個有效位元組。因為段描述符總是8位元組長的,GDT限制值應該總是比8得倍數少1(也就是說,8N-1)。
GDT中的第一個描述符不是給處理器使用的。當把一個指向這個”空描述符(null descriptor)”的段選擇器載入到資料段暫存器(DS,ES,FS, or GS)並不會產生異常。但是試圖使用這個描述符來訪問記憶體的時候,會產生一個通用保護異常(GP)。通過使用這個段選擇器初始化段暫存器,意外引用到未使用的段暫存器,會保證產生一個異常。
LDT是位於LDT型別的系統段。GDT必須包含一個LDT段的段描述符。如果系統支援多LDTs,每一個必須在GDT總有一個分隔的段選擇器和段描述符。GDT可以位於LDT段描述符的任意位置。
一個LDT和他的段選擇器是可訪問的。為了排除在LDT中訪問時的地址轉換,LDT的段選擇器,基本線性地址址,限制,和訪問許可權儲存在LDTR暫存器中。
當(將GDT)在GDTR中store時(使用SGDT指令),一個48-bit”偽描述符(pseudo-descriptor)”儲存在記憶體中(參見圖3-11)。為了避免對齊使用者模式(特權等級3)下的對齊檢查錯誤,加的描述符需要位於偶數位的字地址(就是說,address MOD 4 = 2)。這使得處理器儲存一個對齊的字,緊接著是一個對齊的雙字。使用者模式程式經常不儲存偽描述符,但是通過這種方式對齊偽描述符可以避免產生一個對齊檢查錯誤異常。當使用SIDT指令store IDTR暫存器時,也需要相同的對齊。當store LDTR或者任務暫存器(各自使用SLDT或者STR指令),偽描述符應該存放在雙字地址(就是說,address MOD 4 = 0)。

2.2.5.1. 段暫存器及段描述符表暫存器
在保護模式下使用32位通用暫存器,因而可供定址的實體記憶體多達232=4GB。並且此時處理器對段暫存器的使用方式也發生了改變,段暫存器不再被解釋為段的基地址,而是將該暫存器的16個位分成3個用於不同功能的域:
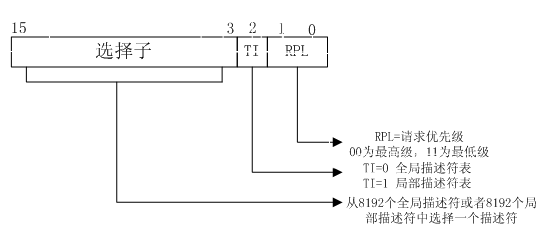
如上圖所示,第3~15位存放選擇子(Selector),用於索引描述符表內的一個描述符,該描述符用於描述儲存器段的位置、長度和訪問許可權。並且在TI=0時選擇全域性描述符表(Global Descriptor Table, GDT),TI=1時選擇區域性描述符表(Local Descriptor Table, LDT)。其中全域性描述符表包含所有程序的段定義,而區域性描述符表則通常由某個指定的程序所使用。因為段選擇子為13位,所以總共可以在一個全域性/區域性描述符表中索引出8192(213=8192)項,而每個描述符的大小為8個位元組,因此每個全域性/區域性描述符表佔用64KB記憶體空間。通常情況下作業系統並不為應用建立LDT,除非應用程式顯示要求這麼做,並且所有的程序均共享同一個GDT,這就意味著預設情況下整個系統的分段結構只由一個GDT指示。此外上述段描述符表的基地址被存放在一組專用暫存器中,這些專用暫存器被稱為段描述符表暫存器:
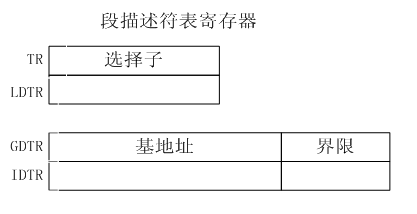
如圖所示,TR中包含的選擇子用於從任務的描述符表中索引出一個描述符,從而在多工系統中實現上下文切換操作,LDTR暫存器中包含的選擇子則用於從區域性描述符表中索引出一個描述符。另外的GDTR與IDTR暫存器包含基地址及界限域,其中界限域的資料位寬度為16,基地址域的資料位寬度為32。在進入保護模式之前,必須先初始化中斷描述符表,此後在保護模式下,全域性描述符表的基地址及其界限才被裝入GDTR中。
- 定址全域性描述符時,首先根據GDTR得到全域性描述符表的基地址,之後通過段暫存器中的13位段選擇子索引出其中的一個描述符。
- 在定址區域性描述符之前,作業系統會在全域性描述符表中為某個具體應用的區域性描述符表進行註冊。此後若段暫存器中的TI域被置位,則通過GDTR中的基地址域及LDTR中的段選擇子從全域性描述符表中找到對應的描述符,該描述符包含了區域性描述符的基地址,界限及訪問許可權等,接著根據段暫存器中的13位段選擇子在區域性描述符表中索引出相應的區域性描述符表項,圖解如下:
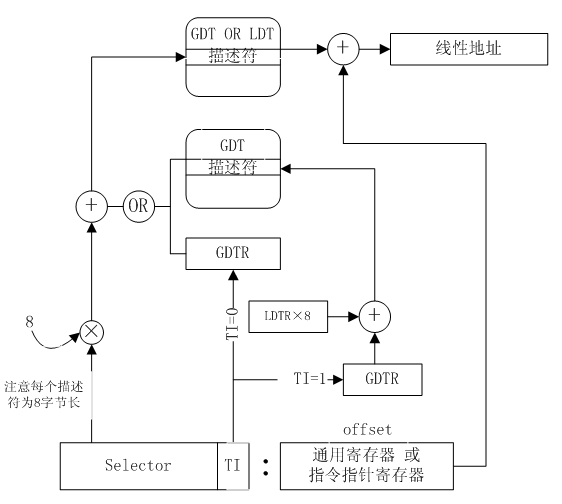
另外段暫存器中的RPL域指示對儲存器段的請求優先順序。因為該域資料位的寬度為2,所以總共有4種可以使用的優先順序。但Windows/Linux均只使用其中的兩種,且將優先順序00賦予核心和驅動,而將優先順序11分配給應用程式。優先順序從環0~環3逐漸降低,注意只有請求優先順序(RPL)等於或高於段描述符中訪問許可權域的優先順序(DPL)才允許訪問,否則系統將指示應用程式違例。
2.2.5.2. IA-32e模式下的段描述符表
在IA-32e 模式,一個段描述符表可以包含最多8192(2^13)個8-byte描述符。段描述符表總的每一個實體可以是8位元組的。系統描述符擴充套件成16位元組(擁有兩倍的實體空間)。
GDTR和LDTR暫存器被擴充套件了以存放64-bit基址。相應的偽描述符是80位的。 下列的系統描述符被擴充套件成16位元組:
- 呼叫門(call gate)描述符
- IDT門(IDT gate)描述符
- LDT和TSS描述符
2.3. 長模式(IA-32e模式)
目前的CPU大多是支援X86-64技術的相容CPU,這包括AMD64以及Intel的IA32E(後被正式命名為EM64T,Extended Memory 64 Technology),因為AMD64先出,而EM64T與AMD64完全相容,所以也統一稱為AMD64技術。由於AMD64技術向下相容,所以很好的承接了以前的16位、32位資源,與此相應,X86-64相容CPU可以執行在多種模式之下,除了熟悉的真實模式,保護模式,還有長模式(Long mode)等,在長模式下,處理器完全執行64位指令,使用64位地址空間(實體記憶體的定址能力卻沒有被完全擴充套件到64位,因為目前的眾多CPU在其壽命期限之內都沒有機會見識到如此巨大的記憶體)和64運算元。因此,為了降低製造成本,目前的CPU被限制在略少於64位定址。注意,當前的這些限制可以(也極有可能)隨著未來新型CPU微架構的釋出而改變。結果就是,如果實體記憶體容量受限,即使開啟全部的64位虛擬地址空間也沒有用。後者因此被加以限制來節省成本。具體來說,CPU中可以節省成本的地方有讀取/儲存單元、緩衝儲存器大小和MMU和TLB的複雜程度。
當處於長模式(Long mode)時,64位應用程式(或者是作業系統)可以使用64位指令和暫存器,而32位和16位程式將以一種相容子模式執行。x86-32架構的cpu,從很早的版本開始就支援“實體地址擴充套件”(PAE),該技術通過記憶體分頁機制將應用程式使用的32位地址對映到36位或52位。同樣,x86-64的cpu會做一個從64位線性地址到64位物理的對映,之後檢查這個64位實體地址的63到52位是否全0或全1,並取該地址的51到0位作為實際的實體地址。因此:
- 就目前的cpu來說,無論工作在長模式下,還是32位保護模式下,定址能力都是52位。但是,因為線性地址從32位提高到了64位,單個程式能夠使用的記憶體量變多了。實際上,32位windows上的程式只能使用2gb記憶體,而64位windows的64位程式可用的記憶體量實際上是無限的。
- 長模式下cpu遮蔽了段機制,簡化了應用程式的記憶體管理,提高了單個暫存器的運算位數,並引入了一系列的新指令集和字首(比如rex),使得合理優化過的64位程式比32位程式效率要高一些。
- 長模式下引入了rip相對定址機制,使得“位置無關程式碼”的實現更容易而且更快。
不過,因為64位windows下也要相容32位程式,所以windows不得不維持兩份相關程式碼,這就是wow64的來歷,wow64會多佔用一些資源。
還有一點是,64位下的相容模式不再支援16位程式,所以執行16位程式需要額外的軟體,比如dosbox。
2.3.1. x64下的物理資源及系統資料結構
2.3.1.1. segment registers
x64 體系在硬體級上最大限度地削弱了 segmentation 段式管理。採用平坦記憶體管理模式,因此體現出來的思想是 base 為 0、limit 忽略。但是,x64 還是對 segmentation 提供了某種程度上的支援。體現在 FS 與 GS 的與眾不同。segment registers 的 selector 與原來的 x86 下意義不變。
在 64 bit 模式下:
(1)code register(CS)
- CS.base = 0(強制為 0,實際上等於無效)
- CS.limit = invalid
- attribute:僅 CS.L 、CS.D、CS.P、CS.C 以及 CS.DPL 屬性是有效的。
注意:64 bit 模式下的 code segment descriptors 中的 L 位、D 位、P 位、C 位以及 DPL 域是有效的。code segment descriptor 載入到 CS 後僅 CS.L 、CS.D、CS.P、CS.C 以及 CS.DPL 屬性是有效的。
在 compatibility 模式下 code segment descriptor 和 CS 暫存器與原來 x86 意義相同。
(2)data registers (DS、ES 以及 SS)
- DS.base = 0(強制為 0,實際上等於無效)
- DS.limit = invalid
- DS.attribute = invalid:所有的屬性域都是無效的。
data registers 的所有域都是無效的。data segment 的 attribute 是無效的,那麼也包括 DPL、D/B 屬性。
在 64 bit 模式下,所有的 data segment 都具有 readable/writable 屬性,processor 對 data segment 的訪問不進行許可權 check 以及 limit 檢查。
(3)FS 與 GS
- FS.base 是完整是的 64 位。
- FS.limit = invalid
- FS.attribute = invalid
與其它 data registers 不同的是,FS 與 GS 的 base 是有效的。支援完整的 64 位地址。但是 limit 和 attribute 依舊無效的。
1、為 FS 和 GS 載入非 0 的 64 位 base 值,使用以下指令:
mov fs, ax
或
pop fs注意:這條指令只能為 fs 提供 32 位的 base 值,這根本的原因是:data segment descriptor 提供的 base 是 32 位值。在 x64 裡的 segment descriptor 是 8 個位元組。也就是 base 是 4 個位元組。通過 selector 載入 base 值,只能獲取 32 位地址值。
2、為 FS 和 GS提供 64 位地址值,可以使用以下指令:
mov ecx, C0000100 /* FS.base msr 地址 */
mov edx, FFFFF800
mov eax, 0F801000
wrmsr /* 寫 FS.base */上面程式碼為 FS.base 提供 0xFFFFF8000F801000 地址。
mov ecx, C0000101 /* GS.base msr 地址 */
mov edx, FFFFF800
mov eax, 0F801000
wrmsr /* 寫 GS.base */上面程式碼為 GS.base 提供 0xFFFFF8000F801000 地址。
另一種方法是使用 swapgs 指令,這條指令將 kernelGS 地址與 GS.base 交換。
2.3.1.2. descriptors 結構
x64 體系已經不提供對 segmentation 的支援(或者說最大程度削弱了),對於 user segment descriptor 來說,還是停留在 x86 的階段,絕大部分的功能已經去掉。但是對於 system descriptor 來說,它是被擴充套件為 16 個位元組,是 128 位的資料結構。因此,descriptors 結構要分兩部分來看。
1) user segment descriptors
在 long mode 下對 user segment descriptor 有兩種解釋結果:
- 64 位模式下的 descriptor
- compatibility 模式下的 descriptor
在 compatibility 模式下 code segment descriptor 與 legacy x86 的 code segment descriptor 在意義在只有一點差異,在 legacy x86 模式下不存在 L 屬性,這個 L 位在 legacy x86 模式下是 0 值。而 compatibility 模式下的 L 屬性也是 0 值。實際上它們是相等的。
下面是在 64 位模式下的解釋:
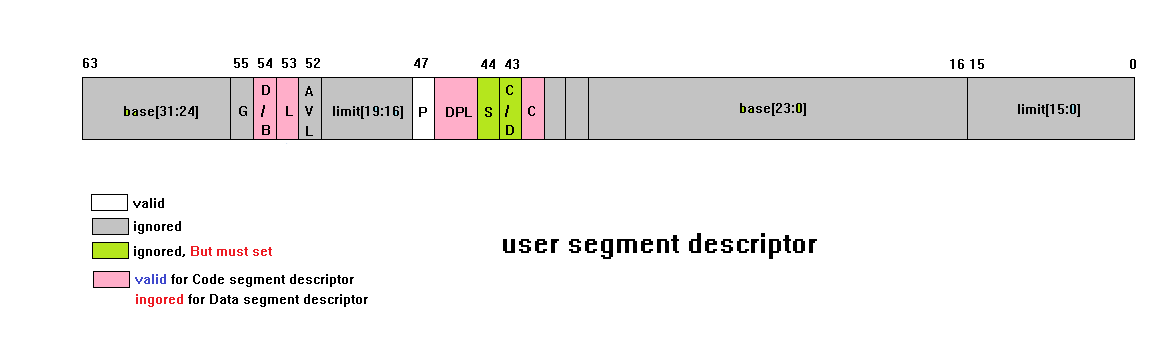
它們的 segment descriptor 的 S = 1 指示它們是 user segment descriptor。上圖灰色部分的 limit 和 base在 user segment descriptor 裡是無效被忽略的,有部分屬性是支援的。然而 attribute 部分對於 Code segment descriptor 和 Data segment descriptor 有著不同的表現,粉紅色部分在 code segmnt descriptor 裡是有效的,在 data segment descriptor 裡是無效的。
a) Code segment descriptor
上圖中的白色部分和紅色部分在 code segment descriptor 裡是有效的,它們是:
- C(Conforming):指示 code segment 是 conforming 還是 non-conforming
型別,它們在許可權控制上的表現是不一樣的。 - DPL(Descriptor Privilige Level): 指示訪問 code segment 需要的許可權
- P(Present):指示 code segment 是否載入在記憶體中
- L(Long):指示 code segment 是 64 位模式程式碼還是 compatibility 模式程式碼
- D(Default operand size):指示 code segment 的 default operand size
這些 attribute 位載入到 CS 暫存器後,在 CS 暫存器的 attribute 裡同樣是有效的。雖然 x64 體系非常想拋棄 segmentation 機制,但是為了整個 x86 架構的相容性不得以而為之:
- C 和 DPL 為許可權控制和轉移而保留
- L 和 D 為 processor 模式和指令運算元而設
- P 恐怕是最沒有異議
圖中綠色部分比較特別:
- S(system) 標誌
- C/D(Code/Data)標誌
雖然這兩個標誌是無效的,但是您必須為它設定初始值,在設定初始值後你不能進行更改,這是無效的一面。對於 Code segment descriptor 來說,它必須設為(注意是:必須):
- S = 1
- C/D = 1
說明這個 descriptor 是 code segment descriptor,如果你嘗試載入一個 S = 0 或者 C/D = 0 的 descriptor 進入 CS 暫存器,將會產生 #GP 異常。而下面兩個型別屬性是無效的:
- R(Readable)
- A(Accessed)
那麼 Code segment 在 64 位模式下強制為 Readable 可讀。
b) Data segment descriptor
在 data segment descriptor 情況有些特別。對於載入到 ES, DS, SS 暫存器的 data segment descriptor 來說僅有一個屬性是有效的:
- P(Present)
對於載入到 FS 和 GS 暫存器的 data segment descriptor 來說 base 是有效的,那麼可以在 FS 和 GS 暫存器的 base 裡設定非 0 的 segment base 值。 同樣必須設定 S 和 C/D 屬性,在 data segment descriptor 裡它們必須為:
- S = 1
- C/D = 0
指示該 descriptor 是 data segment descriptor,如果嘗試載入 S = 0 或者 C/D = 1 的 descriptor 進入 DS,ES,SS,FS 以及 GS 暫存器會產生 #GP 異常。下面的型別屬性是無效的:
- E(Expand-Down)
- W(Writable)
- A(Accessed)
那麼在 64 位模式下,data segment 被強制為 Expand-Up 和 Writable 的。
2) system descriptors
包括 LDT descriptor、TSS descriptor 。這些 descriptor 被擴充套件為 16 個位元組共 128 位。descriptor 的 base 域被擴充套件為 64 位值。用來在 64 位的線性地址空間中定位。在 compatibility 模式下,LDT / TSS 依舊是 32 位的 descriptor。
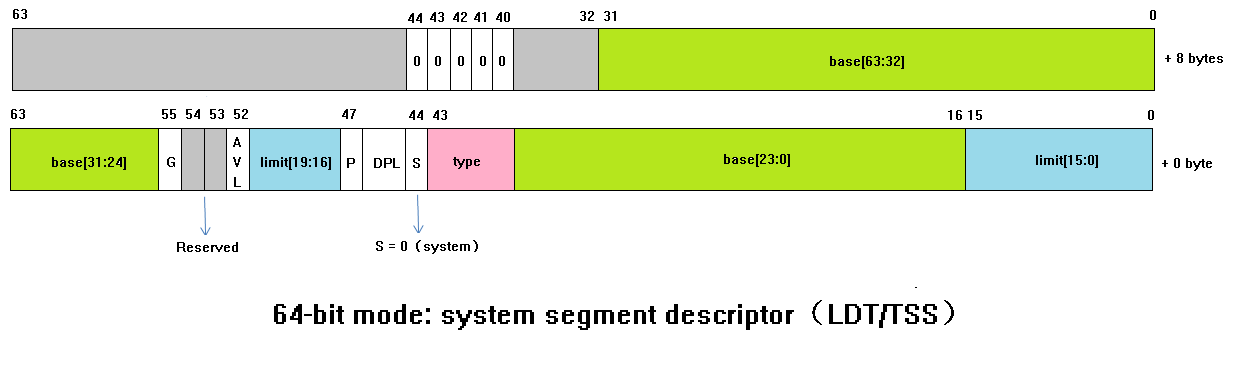
64 位模式下的 system segment descriptor 是 16 bytes 共 128 位,包括:
- 20 位的 segment limit
- 64 位的 segment base
- 12 位的 segment attribute
在 64 位模式下 user segment descriptor 是 8 bytes,而 system segment descriptor 是 16 bytes 的,它們存放在 GDT 表中就可能會產生了跨 descriptor 邊界的問題。
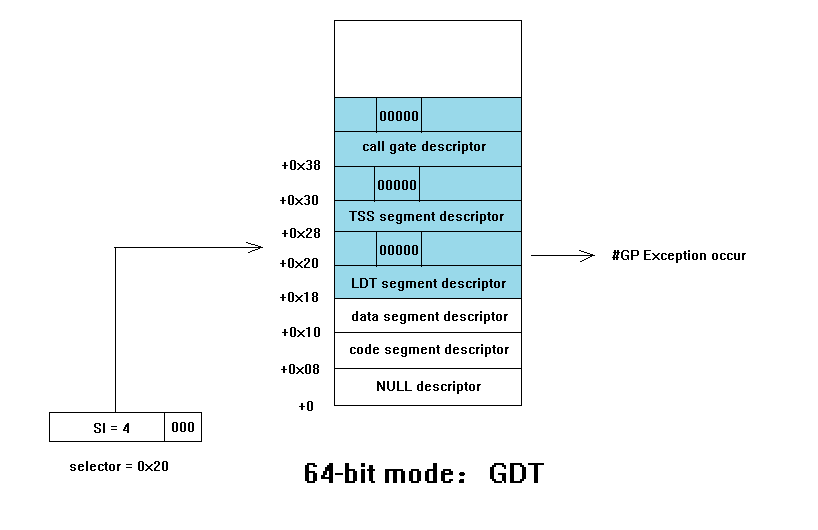
上圖顯示了在 64 位模式下的一個跨 descriptor 邊界產生 #GP 異常的示例:
當使用 selector = 0x20 企圖訪問一個 user segment descriptor,但是並不如願,+0x20 位置上並不是一個有效 user segment descriptor,它只是 LDT descriptor 的高半部分
結果會怎樣?答案是:未知
因此為了防止這種未知結果的產生,x64 體系中建議:須將 system descirptor(包括 call gate descriptor)的高 64 位中的對應 S 標誌和 type 位置上置00000,但是不包括 interrupt gate 和 trap gate。由於 00000(代表 0 型別的 system descriptor)是無效的 descriptor 型別,因此訪問這樣的 descriptor 會導致 #GP 異常的發生。從而避免未知結果的產生。這就是上圖中上半部分的 S 和 type 域為何置為 00000 的原因。當然這個跨 descriptor 邊界的情況在 LDT 也可能發生。但是在 IDT 是不可能發生的,那是因為 IDT 只能存在 system descriptor 不可存放 user segment descriptor。因此 IDT 表的索引因子固定為 16,這就是 interrupt gate 和 trap gate 的高半部分 s 和 type 域不用置為 00000 的原因。
LDT/TSS segment descriptor 大部分屬性是有效的,包括:
- type
- S
- DPL
- P
- AVL
- G
它們的 type 包括:
- type = 2 :64-bit LDT
- type = 9 :available 64-bit TSS
- type = B :busy 64-bit TSS
64 位模式的 system segment descriptor 已經不支援 16 位的 TSS,原來的 32 位 TSS 變成了 64 位的 TSS。
system segment descriptor 在 compatibility mode 下依舊是 32 位的 descriptor,這和 64 bit 模式下區別很大。在一個可以執行 legacy 32 位程式的 OS 裡,應該要準備兩份 LDT/TSS segment descriptor:64 位的 LDT/TSS segment descriptor 和 32 位的 LDT/TSS segment descriptor
3) gate descriptor
long mode 下不存在 task gate。所有的 gate(call、interrupt / trap) 都 64 位的。gate 所索引的 code segment 是 64 位的 code segment(L = 1 && D = 0)
注意:
1、long mode 下的 segment descriptor 與 x86 原有的 segment descriptor 格式完全一致,只是在 64 bit 模式中 descriptor 的大部分域是無效的。
2、64 bit 模式下的 system descriptor 被擴充套件為 16 個位元組。由於 system descriptor 中的 base 是有效的,base 被擴充套件為 64 位,故 system descriptor 被擴充套件為 128 位。
2.3.1.3. descriptor table
在 long mode 下 GDT 可以容納:
- 32 位的 code segment descriptor
- 32 位的 data segment descripotr
- 64 位的 LDT segment descriptor
- 64 位的 TSS segment descriptor
- 64 位的 call gate descriptor
全部 system descriptor(包括:LDT/TSS descriptor 和 call gate descriptor)都擴充套件為 64 位的 descriptor
注意:這些 system GDT entries 是 16 bytes 128 位的大小,這裡所說的 64 位的descriptor 是指 descriptor 的型別是 64 位,它的大小實際上 16 bytes,上文已經提過在 long mode 下“跨 descriptor 邊界”問題的產生就是因為這裡有 32 位的 descriptor 和 64 位的 descriptor 同時存放在 GDT 裡所造成的。
1) long mode 下 GDT 的 base
GDTR.base 擴充套件為 64 位,因此 GDT 可以在 64 位線性空間的任何位置,但 limit 還是 16 位不變。
2) long mode 下 GDT 的索引
long mode 下 GDT 依然是按以前的方式索引查詢 descriptor,即:selctor.SI * 8 而不是 selector.SI * 16,這是因為還存在 32 位的 code/data segment descriptor 的緣故。這是造成跨 descriptor 邊界的原因。
3) long mode 下的 LDT
在 long mode 下的 LDT 可以存放:
- 32 位 code/data segment descriptor
- 64 位的 call gate desciptor