
淺談chainer框架
一 chainer基礎
Chainer是一個專門為高效研究和開發深度學習演算法而設計的開源框架。 這篇博文會通過一些例子簡要地介紹一下Chainer,同時把它與其他一些框架做比較,比如Caffe、Theano、Torch和Tensorflow。
大多數現有的深度學習框架是在模型訓練之前構建計算圖。 這種方法是相當簡單明瞭的,特別是對於結構固定且分層的神經網路(比如卷積神經網路)的實現。
然而,現在的複雜神經網路(比如迴圈神經網路或隨機神經網路)帶來了新的效能改進和新的應用。雖然現有的框架可以用於實現這些複雜神經網路,但是它們有時需要一些(不優雅的)程式設計技巧,這可能會降低程式碼的開發效率和可維護性。
而Chainer的方法是獨一無二的:即在訓練時“實時”構建計算圖。
這種方法可以讓使用者在每次迭代時或者對每個樣本根據條件更改計算圖。同時也很容易使用標準偵錯程式和分析器來除錯和重構基於Chainer的程式碼,因為Chainer使用純Python和NumPy提供了一個命令式的API。 這為複雜神經網路的實現提供了更大的靈活性,同時又加快了迭代速度,提高了快速實現最新深度學習演算法的能力。
以下我會介紹Chainer是如何工作的,以及使用者可以從中獲得什麼樣的好處。
Chainer 是一個基於Python的獨立的深度學習框架。
不同於其它基於Python介面的框架(比如Theano和TensorFlow),Chainer通過支援相容Numpy的陣列間運算的方式,提供了宣告神經網路的命令式方法。Chainer 還包括一個名為CuPy的基於GPU的數值計算庫。
>>> from chainer import Variable
>>> import numpy as np
Variable 類是把numpy.ndarray陣列包裝在內的計算模組(numpy.ndarray存放在.data中)。
>>> x = Variable(np.asarray([[0, 2],[1, -3]]).astype(np.float32))
>>> print(x.data)
[[ 0. 2.]
[ 1. -3.]]
使用者可以直接在Variables上定義各種運算和函式(Function的例項)。
>>> y = x ** 2 – x + 1
>>> print(y.data)
[[ 1. 3.]
[ 1. 13.]]
因為這些新定義的Varriable類知道他們是由什麼類生成的,所以Variable y跟它的父類有一樣的加法運算(.creator)。
>>> print(y.creator)
<chainer.functions.math.basic_math.AddConstant at 0x7f939XXXXX>
利用這種機制,可以通過反向追蹤從最終損失函式到輸入的完整路徑來實現反向計算。完整路徑在執行正向計算的過程中儲存,而不預先定義計算圖。
在chainer.functions類中給出了許多數值運算和啟用函式。 標準神經網路的運算在Chainer類中是通過Link類實現的,比如線性全連線層和卷積層。Link可以看做是與其相應層的學習引數的一個函式(例如權重和偏差引數)。你也可以建立一個包含許多其他Link的Link。這樣的一個link容器被命名為Chain。這允許Chainer可以將神經網路建模成一個包含多個link和多個chain的層次結構。Chainer還支援最新的優化方法、序列化方法以及使用CuPy的由CUDA驅動的更快速計算。
>>> import chainer.functions as F
>>> import chainer.links as L
>>> from chainer import Chain, optimizers, serializers, cuda
>>> import cupy as cp
二 chainer的設計
訓練一個神經網路一般需要三個步驟:(1)基於神經網路的定義來構建計算圖;(2)輸入訓練資料並計算損失函式;(3)使用優化器迭代更新引數直到收斂。
通常,深度學習框架在步驟2之前先要完成步驟1。 我們稱這種方法是“先定義再執行”。

對於複雜神經網路,這種“先定義再執行”的方法簡單直接,但並不是最佳的,因為計算圖必須在訓練前確定。 例如,在實現迴圈神經網路時,使用者不得不利用特殊技巧(比如Theano中的scan()函式),這就會使程式碼變的難以除錯和維護。
與之不同的是,Chainer使用一種“邊執行邊定義”的獨特方法,它將第一步和第二步合併到一個步驟中去。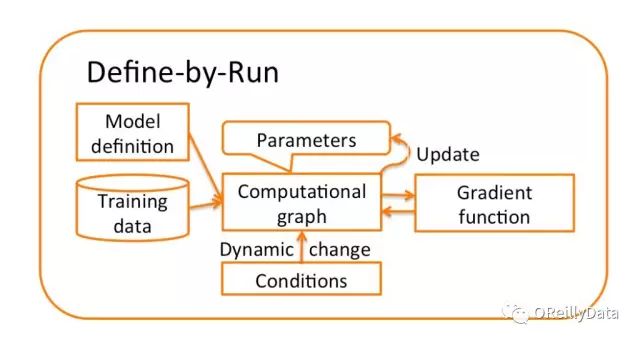
計算圖不是在訓練之前定義的,而是在訓練過程中獲得的。 因為正向計算直接對應於計算圖並且也通過計算圖進行反向傳播,所以可以在每次迭代甚至對於每個樣本的正向計算中對計算圖做各種修改。
舉一個簡單的例子,讓我們看看使用兩層感知器進行MNIST數字分類會發生什麼。

下面是Chainer中兩層感知器的實現程式碼:
# 2-layer Multi-Layer Perceptron (MLP)
# 兩層的多層感知器(MLP)
class MLP(Chain):
def __init__(self):
super(MLP, self).__init__()
l1=L.Linear(784, 100), # From 784-dimensional input to hidden unit with 100 nodes
# 從784維輸入向量到100個節點的隱藏單元
l2=L.Linear(100, 10), # From hidden unit with 100 nodes to output unit with 10 nodes (10 classes)
# 從100個節點的隱藏單元到10個節點的輸出單元(10個類)
# Forward computation
# 正向計算
def __call__(self, x):
h1 = F.tanh(self.l1(x)) # Forward from x to h1 through activation with tanh function
# 用tanh啟用函式,從輸入x正向算出h1
y = self.l2(h1) # Forward from h1to y
# 從h1正向計算出y
return y
在建構函式(__init__)中,我們分別定義了從輸入單元到隱藏單元,和從隱藏單元到輸出單元的兩個線性變換。要注意的是,這時並沒有定義這些變換之間的連線,這意味著計算圖沒有生成,更不用說固定它了。
跟“先定義後執行”方法不同的是,它們之間的連線關係會在後面的正向計算中通過定義層之間的啟用函式(F.tanh)來定義。一旦對MNIST上的小批量訓練資料集(784維)完成了正向計算,就可以通過從最終節點(損失函式的輸出)回溯到輸入來實時獲得下面的計算圖(注意這裡使用SoftmaxCrossEntropy做為損失函式):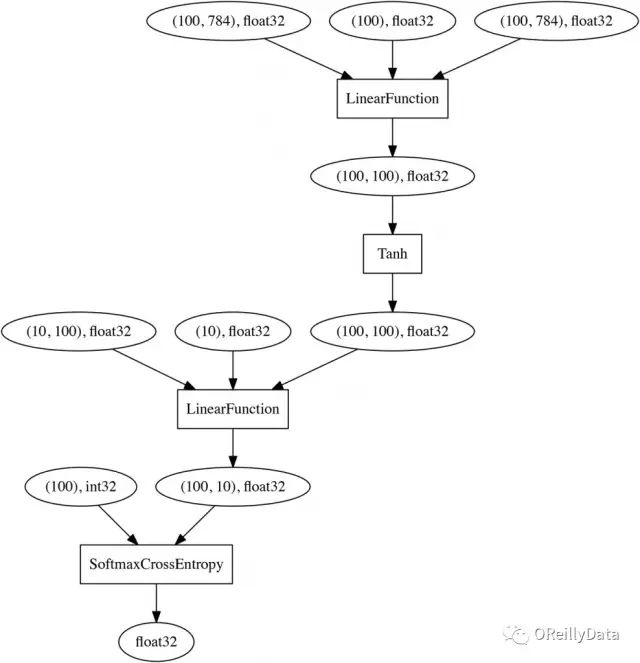
這種神經網路的命令性宣告允許使用者使用標準的Python語法進行網路分支計算,而不用研究任何領域特定語言(DSL)。這跟TensorFlow、 Theano使用的符號方法以及Caffe和CNTK依賴的文字DSL相比是一個優勢。
此外,可以使用標準偵錯程式和分析器來查詢錯誤、重構程式碼以及調整超引數。 另一方面,儘管Torch和MXNet也允許使用者使用神經網路的命令性建模,但是他們仍然使用“先定義後執行”的方法來構建計算圖物件,因此除錯時需要特別小心。
三 chainer安裝
在Anaconda Prompt下執行下邊的程式碼即可:
pip install chainer
參考:https://blog.csdn.net/zkh880loLh3h21AJTH/article/details/78100460