
二、詞法分析器構造原理
一、正則式(regular expression)
1.正則式定義:
ε表示語言{ε},a表示語言{a},(r)|(s)表示語言L(r)並L(s),(r)(s)表示語言L(r)L(s),(r)*表示語言(L(r))*
正則式優先順序為 閉包>連線>或,即((a)(b)*)|(c)寫為ab*|c 。
再給一些例子:(a|b)(a|b)定義的語言為{aa,ab,ba,bb},(a|b)*定義為由a和b表示的所有串集。
2.C語言識別符號的正則定義:
letter_ → A|B|...|Z|a|b|...|z|_
digit→ 0|1|...|9
id→ letter_(letter_ | digit)*
3.正則式和上下文無關文法比較:
任何正則式都可寫出上下文無關文法(更準確地說為正規文法,即3型文法)。
如正則式 (a|b)*ab 一定能給出上下文無關文法(由於可以給出它的NFA,之後會介紹)
A0→ aA0 | bA0 | aA1 狀態0可由a轉換到狀態0,可由b轉換到狀態0,可由a轉換到狀態1。
A1→ bA2 狀態1可由b轉換到狀態2
A2→ε 狀態2為結束因此對應空串
二、有限自動機(finite automata)
1.非確定有限自動機(NFA):
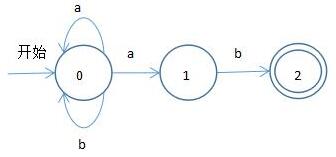
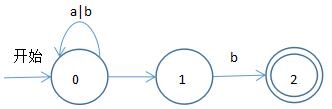
如需要識別語言 (a|b)*ab ,可引出如下非確定有限自動機
非確定有限自動機中,當前狀態與一個輸入能轉換到多個狀態,如狀態0輸入a後既能轉換到狀態0又能轉換到狀態1,上圖中兩個圈(狀態2)表示該狀態為結束狀態(可認為一到該狀態就返回成功識別)。
只要包含如下特徵任意一個就是非確定有限自動機:1.當前狀態與一個輸入對應多個轉換狀態,2.存在ε輸入。
非確定有限自動機用程式實現比較困難,因此需要變換為確定有限自動機。
注:如果結束狀態右邊加一個星號*則表示結束後還要吐出一個字元。
2.根據正規式畫非確定有限自動機:
r=ab: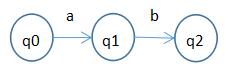
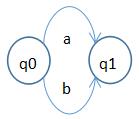

根據以上規則,可一步步得到正規式(a|b)*ab的NFA
->

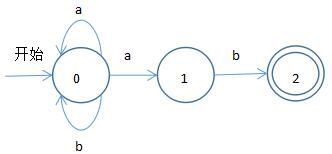
3.確定有限自動機(DFA):
如需要識別語言 (a|b)*ab ,可引出如下確定有限自動機
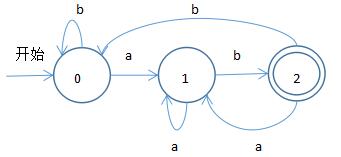
必須滿足如下:1.當前狀態與一個輸入對應最多一個轉換狀態,2.不存在ε輸入。
因此確定有限自動機對應一個二維陣列
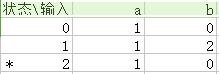
4.非確定有限自動機確定化(子集構造法):
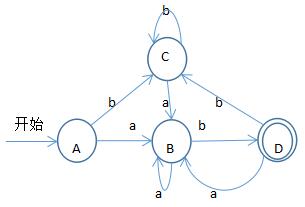
用一個例子說明,有如下非確定有限自動機表示 (a|b)*ab,將其確定化。
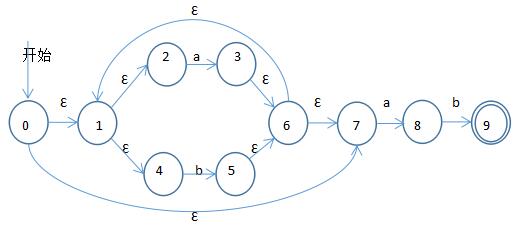
<1>——開始狀態能夠經過空轉換到達的合成一個狀態,即由0的ε閉包構成DFA的開始狀態A
A={0,1,2,4,7}

<2>——由A的a閉包狀態集合構成DFA狀態B
B={1,2,3,4,6,7,8}
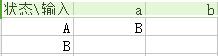
<3>——由A的b閉包狀態集合構成DFA狀態C
C={1,2,4,5,6,7}
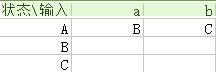
<4>——依次類推,直到沒有新狀態,最後得到
A={0,1,2,4,7},B={1,2,3,4,6,7,8},C={1,2,4,5,6,7},D={1,2,4,5,6,7,9}
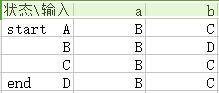
其中包含原NFA結束狀態9的必為現DFA的結束狀態。
例題1:
設有正則式 r = (a|ab) (a|b)* b
1.構造NFA,2.轉化為DFA,3.給出正規文法(3型文法)。
解:
(1)構造NFA比較容易,根據二.2直接給出答案。
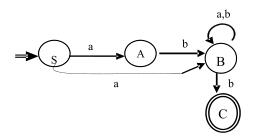
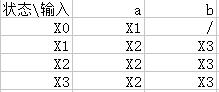
(2)轉化為DFA,運用二.4子集構造法。
<1>——開始狀態空閉包
X0={S}

<2>——X0狀態a閉包
X1={A,B}

<3>——X0狀態b閉包無,再求X1狀態a閉包
X2={B}

<4>——X1狀態b閉包
X3={B,C}

<5>——求X2狀態a閉包(為X2),再求X2狀態b閉包(為X3),再求X3狀態a閉包(為X2),再求X3狀態b閉包(為X3),得到最終狀態轉換圖,即可畫出對應DFA。
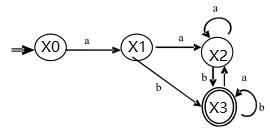
(3)給出正規文法,即3型文法。
X0→ aX1 X0狀態所有指向
X1→ aX2 | bX3 X1狀態所有指向
X2→ aX2 | bX3 X2狀態所有指向
X3→ aX2 | bX3 | ε X3狀態所有指向,結束處要加一個空串