
一、編譯器構造一般原理
一、編譯器概述
1.翻譯器(translator):把一種語言程式翻譯成另一種語言程式。
2.編譯器(compiler):高階語言變成低階語言。
3.直譯器(interpreter):將語句一條一條直接執行,而不生成目的碼。
4.編譯器階段:源程式->詞法分析->語法分析->語義分析->中間程式碼生成器->獨立於機器程式碼優化器->程式碼生成器->依賴於機器程式碼優化器。
5.詞法分析器(lexical analysis,scanner):
將字元序列轉化為單詞序列(token)的過程,如將position=initial+rate*60轉化,通過詞法分析器轉化為如下
<id,1>,<=>,<id,2>,<+>,<id,3>,<*>,<60>,其中符號表為:1.position,2.initial,3.rate ...
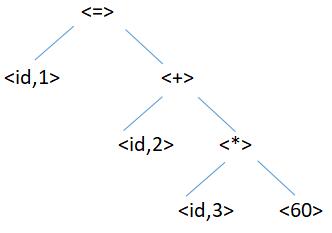
6.語法分析器(syntactic analysis,parser):
將position=initial+rate*60經過詞法分析得到的序列構造成一棵分析樹(parse tree),如下
7.語義分析器(semantic analysis):
輸入語法樹,輸出也是語法樹,收集識別符號種屬、型別、儲存位置長度、值、引數返回等資訊,存到符號表中,並進行語義檢查。
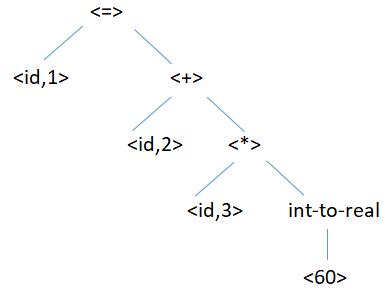
8.中間程式碼生成器(intermediate code generator):將上述語法樹生成中間程式碼如下(三地址指令)
t1=int-to-real(60)
t2=id3*t1
t3=id2+t2
id1=t3
9.程式碼優化器(code optimizer):中間程式碼優化器可得到如下
t1=id3*60.0
id1=id2+t1
10.程式碼生成器(code generator):生成彙編程式碼或機器碼。
11.詞法分析器與語法分析器關係:語法分析器作為主程式,呼叫詞法分析器取下一個token,詞法分析器取好返回給語法分析器,在這個過程期間它們都要訪問符號表。(語法分析器後面還可能會呼叫語義分析器)
二、詞法基本概念
1.字母表(alphabet):表示字母的集合,記號為Σ,若Σ={0,1}則字母表中只有0或1。
2.字母表乘積(product):Σ1Σ2=Σ3,則Σ3中存在兩個字母,前一個字母在Σ1集合中,後一個字母在Σ2集合中。
3.字母表的冪(power):字母表的n次冪表示長度為n的符號串構成的集合,這些符號在字母表集合內。
4.字母表閉包(closure):由字母表中字母構成的所有串(包括空串),若為正(positive)閉包則不包含空串。
5.串(string):符號的有窮序列,空串記為ε,通常用|s|記作串s的長度。
6.串的連線(concatenation):如xy連線aa就等於xyaa,即追加串。
7.串的冪:(ab)^3=ababab,任何串0次冪為ε。
8.串的閉包:(ab)*為{ε,ab,abab,ababab,abababab,......}即(ab)^0並(ab)^1並...,若為正閉包則去掉空串。
9.語言(language):字母表上的一個串集,如{ε,0,00,000}或者Ø。
10.語言的並運算:L∪M=結合了兩種語言的語言。
11.語言的連線運算:LM=每一個句子的前一部分一定屬於L語言,後一部分一定屬於M語言。
12.語言的冪:L^0={ε},L^i為語言所有句子的i次連線。
13.語言的閉包:L*=L^0並L^1並L^2並....,若正閉包則去掉L^0。
三、文法基本概念
1.文法形式化定義:
G=(Vt,Vn,P,S)
Vt為終結符(terminal symbol)集合,終結符也稱token。
Vn為非終結符(nonterminal)集合,非終結符是表示語法成分的符號。
P為產生式(production)集合,描述了將終結符和非終結符組合成串的方,形式為a→ b,讀作a定義為b,這裡要求a必須包含至少一個非終結符。
S為開始符號(start symbol),表示該文法中最大的語法成分。
文法解決了無窮語言的有窮表示問題。
2.文法的例子:
G=( {id,+,*,(,)} , {E} , P , E )
P={ E→ E+E , E→ E*E , E→ (E) , E→ id }
3.產生式簡寫:a→ b1,a → b2,a → b3 可簡寫為 a → b1 | b2 | b3 。
4.推導(derivations):A→ B,B → (id) 推導為 A → (id) ,將最大語法成分推導為終結符組成的串。
5.歸約(reductions):由上例,A → (id) 可歸約為 A→ B ,推導逆操作,將終結符組成的串歸約為最大語法成分。
6.句型(sentential form):一個句型可包含終結符,又可包含非終結符,也可能是空串。
7.句子(sentence):不包含非終結符的句型。
8.文法分類:
0型文法(無限制文法):任意a→ b,a中至少包含1個非終結符,能力相當於圖靈機。
1型文法(上下文有關文法):0型文法基礎上,任意a→ b,|a| <= |b| (b不等於ε),如 aAb→ axb 上下文有關。
2型文法(上下文無關文法,context-free grammar):每個產生式左部必須是非終結符,A→ b 。
3型文法(正則文法,regular grammar):A→ wB或A→ w(右線性),A→ Bw或A→ w(左線性)。
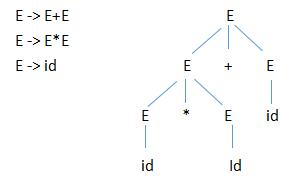
9.上下文無關文法的分析樹:
根為文法開始符號,內部結點為某產生式的左部,一個內部結點和兒子構成了某產生式,分析樹是推導的圖形化表示。
10.最左推導和最後推導(left/right-most derivation):
例如給出如下產生式 E→ E+E | E*E | (E) | -E | id
最左推導:推導過程中每次對最左邊的非終結符展開。
E→ -E → -(E) → -(E+E) → -(id+E) → -(id+id)
最右推導(規範推導):每次對最右邊的非終結符展開。
E→ -E → -(E) → -(E+E) → -(E+id) → -(id+id)
注:最左推導和最右推導的分析樹是一樣的。
11.相同句子分析樹的二義性(同為最左推導):.
對於產生式 E→ E+E | E*E | (E) | -E | id,要得到句子id*id+id,在最左推導的情況下,可以有這兩種分析樹。
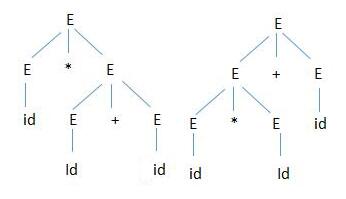
為消除由運算優先順序產生的二義性,可以這樣定義文法
id*id*(id+id) + id*id + id 我們把加式連一塊看作一個expr,把乘式連一塊看作一個term。
id * id * (id+id) 連乘式中每一項看作一個因子factor。
文法就定義為:
expr→ expr+term | term
term→ term*factor | factor
factor→ id | (expr)
例題1:
描述下述語言 L={(a^n) (d^m) (b^n),n,m>=1}
解:
A→ aAb | aBb 前面的aAb表示可一直延伸ab,即為 ...aaAbb... ,後面的aBb表示B可被d換
B→ dB | d 即表示dd...
例題2:
證明下列文法是一個二義文法
A→ B+B | B
B→ B*B | A | a
解:
對於相同句子a+a*a,同是最左推導時,存在以下兩個不同的分析樹,因此為二義文法。
A →B+B→a+B→a+B*B→a+a*B→a+a*a
A→B→B*B→ A*B→ B+B*B→ a+B*B→ a+a*B→ a+a*a