
RabbitMQ訊息佇列入門篇(環境配置+Java例項+基礎概念)
一、訊息佇列使用場景或者其好處
訊息佇列一般是在專案中,將一些無需即時返回且耗時的操作提取出來,進行了非同步處理,而這種非同步處理的方式大大的節省了伺服器的請求響應時間,從而提高了系統的吞吐量。
在專案啟動之初來預測將來專案會碰到什麼需求,是極其困難的。訊息佇列在處理過程中間插入了一個隱含的、基於資料的介面層,兩邊的處理過程都要實現這一介面。這允許你獨立的擴充套件或修改兩邊的處理過程,只要確保它們遵守同樣的介面約束。訊息佇列可以解決這樣一個問題,也就是其解耦性。解耦伴隨的好處就是降低冗餘,靈活,易於擴充套件。
峰值處理能力:當你的應用上了Hacker News的首頁,你將發現訪問流量攀升到一個不同尋常的水平。在訪問量劇增的情況下,你的應用仍然需要繼續發揮作用,但是這樣的突發流量並不常見;如果為以能處理這類峰值訪問為標準來投入資源隨時待命無疑是巨大的浪費。使用訊息佇列能夠使關鍵元件頂住增長的訪問壓力,而不是因為超出負荷的請求而完全崩潰。
訊息佇列還有可恢復性、非同步通訊、緩衝………等各種好處,在此不一一介紹,用到自然理解。
二、RabbitMQ來源
RabbitMQ是用Erlang實現的一個高併發高可靠AMQP訊息佇列伺服器。
顯然,RabbitMQ跟Erlang和AMQP有關。下面簡單介紹一下Erlang和AMQP。
Erlang是一門動態型別的函數語言程式設計語言,它也是一門解釋型語言,由Erlang虛擬機器解釋執行。從語言模型上說,Erlang是基於Actor模型的實現。在Actor模型裡面,萬物皆Actor,每個Actor都封裝著內部狀態,Actor相互之間只能通過訊息傳遞這一種方式來進行通訊。對應到Erlang裡,每個Actor對應著一個Erlang程序,程序之間通過訊息傳遞進行通訊。相比共享記憶體,程序間通過訊息傳遞來通訊帶來的直接好處就是消除了直接的鎖開銷(不考慮Erlang虛擬機器底層實現中的鎖應用)。
AMQP(Advanced Message Queue Protocol)定義了一種訊息系統規範。這個規範描述了在一個分散式的系統中各個子系統如何通過訊息互動。而RabbitMQ則是AMQP的一種基於erlang的實現。AMQP將分散式系統中各個子系統隔離開來,子系統之間不再有依賴。子系統僅依賴於訊息。子系統不關心訊息的傳送者,也不關心訊息的接受者。
這裡不必要對Erlang和AMQP作過於深入介紹,畢竟本文RabbitMQ才是主角哦,哈哈。下面直接看主角表演(例項)啦,至於主角的一些不得不深入介紹的點我們放到最後面。
三、RabbitMQ例項(Java)
3.1、環境配置
cd C:\Program rabbitmq-server start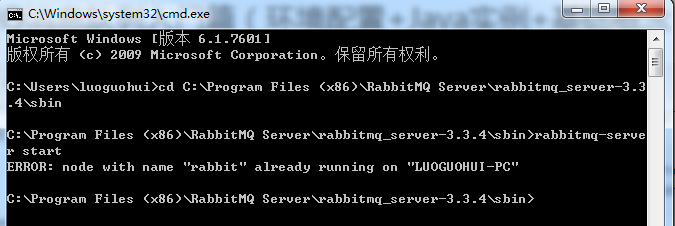
博主的之前啟動過了,所以報錯,如果你的也啟動了就沒問題了。
接下來自然是jar包依賴,本文工程採用eclipse + maven,maven依賴如下:
<!-- rabbitmq相關依賴 -->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>3.0.4</version>
</dependency>
<!-- 序列化相關依賴 -->
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>因為後續例子裡面有用到序列化的,因此加上序列化工具包相關依賴。
3.2、例子一程式碼和效果
新建傳送者Send.java,程式碼如下:
package com.luo.rabbit.test.one;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class Send {
//佇列名稱
private final static String QUEUE_NAME = "queue";
public static void main(String[] argv) throws java.io.IOException
{
/**
* 建立連線連線到MabbitMQ
*/
ConnectionFactory factory = new ConnectionFactory();
//設定MabbitMQ所在主機ip或者主機名
factory.setHost("127.0.0.1");
//建立一個連線
Connection connection = factory.newConnection();
//建立一個頻道
Channel channel = connection.createChannel();
//指定一個佇列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//傳送的訊息
String message = "hello world!";
//往佇列中發出一條訊息
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println("Sent '" + message + "'");
//關閉頻道和連線
channel.close();
connection.close();
}
}
新建接收者Recv.java,程式碼如下:
package com.luo.rabbit.test.one;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.QueueingConsumer;
public class Recv {
//佇列名稱
private final static String QUEUE_NAME = "queue";
public static void main(String[] argv) throws java.io.IOException,
java.lang.InterruptedException
{
//開啟連線和建立頻道,與傳送端一樣
ConnectionFactory factory = new ConnectionFactory();
//設定MabbitMQ所在主機ip或者主機名
factory.setHost("127.0.0.1");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//宣告佇列,主要為了防止訊息接收者先執行此程式,佇列還不存在時建立佇列。
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println("Waiting for messages. To exit press CTRL+C");
//建立佇列消費者
QueueingConsumer consumer = new QueueingConsumer(channel);
//指定消費佇列
channel.basicConsume(QUEUE_NAME, true, consumer);
while (true)
{
//nextDelivery是一個阻塞方法(內部實現其實是阻塞佇列的take方法)
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println("Received '" + message + "'");
}
}
}
分別執行這兩個類,先後順序沒有關係,先執行傳送者再執行接收者,效果如下:
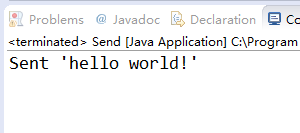
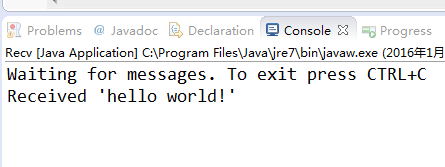
3.3、例子二程式碼和效果
例子一可能通俗易懂,但是並不是很規範,而且有些缺陷,比如我要傳送一個物件過去呢?下面看另外一個例子:
首先建一個連線類,因為傳送者和接收者的連線程式碼都是一樣的,之後讓二者繼承這個連線類即可。連線類程式碼BaseConnector.java:
package com.luo.rabbit.test.two;
import java.io.IOException;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class BaseConnector {
protected Channel channel;
protected Connection connection;
protected String queueName;
public BaseConnector(String queueName) throws IOException{
this.queueName = queueName;
//開啟連線和建立頻道
ConnectionFactory factory = new ConnectionFactory();
//設定MabbitMQ所在主機ip或者主機名 127.0.0.1即localhost
factory.setHost("127.0.0.1");
//建立連線
connection = factory.newConnection();
//建立頻道
channel = connection.createChannel();
//宣告建立佇列
channel.queueDeclare(queueName, false, false, false, null);
}
}
傳送者Sender.java:
package com.luo.rabbit.test.two;
import java.io.IOException;
import java.io.Serializable;
import org.apache.commons.lang.SerializationUtils;
public class Sender extends BaseConnector {
public Sender(String queueName) throws IOException {
super(queueName);
}
public void sendMessage(Serializable object) throws IOException {
channel.basicPublish("",queueName, null, SerializationUtils.serialize(object));
}
}
前面講過,我們想傳送一個物件給接受者,因此,我們先新建一個物件,因為傳送過程需要序列化,因此這裡需要實現java.io.Serializable介面:
package com.luo.rabbit.test.two;
import java.io.Serializable;
public class MessageInfo implements Serializable {
private static final long serialVersionUID = 1L;
//渠道
private String channel;
//來源
private String content;
public String getChannel() {
return channel;
}
public void setChannel(String channel) {
this.channel = channel;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
關於序列化,這裡小寶鴿就再嘮叨兩句,序列化就是將一個物件的狀態(各個屬性量)儲存起來,然後在適當的時候再獲得。序列化分為兩大部分:序列化和反序列化。序列化是這個過程的第一部分,將資料分解成位元組流,以便儲存在檔案中或在網路上傳輸。反序列化就是開啟位元組流並重構物件。物件序列化不僅要將基本資料型別轉換成位元組表示,有時還要恢復資料。恢復資料要求有恢復資料的物件例項。
接收者程式碼Receiver.java:
package com.luo.rabbit.test.two;
import java.io.IOException;
import org.apache.commons.lang.SerializationUtils;
import com.rabbitmq.client.AMQP.BasicProperties;
import com.rabbitmq.client.Envelope;
import com.rabbitmq.client.Consumer;
import com.rabbitmq.client.ShutdownSignalException;
public class Receiver extends BaseConnector implements Runnable, Consumer {
public Receiver(String queueName) throws IOException {
super(queueName);
}
//實現Runnable的run方法
public void run() {
try {
channel.basicConsume(queueName, true,this);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 下面這些方法都是實現Consumer介面的
**/
//當消費者註冊完成自動呼叫
public void handleConsumeOk(String consumerTag) {
System.out.println("Consumer "+consumerTag +" registered");
}
//當消費者接收到訊息會自動呼叫
public void handleDelivery(String consumerTag, Envelope env,
BasicProperties props, byte[] body) throws IOException {
MessageInfo messageInfo = (MessageInfo)SerializationUtils.deserialize(body);
System.out.println("Message ( "
+ "channel : " + messageInfo.getChannel()
+ " , content : " + messageInfo.getContent()
+ " ) received.");
}
//下面這些方法可以暫時不用理會
public void handleCancelOk(String consumerTag) {
}
public void handleCancel(String consumerTag) throws IOException {
}
public void handleShutdownSignal(String consumerTag,
ShutdownSignalException sig) {
}
public void handleRecoverOk(String consumerTag) {
}
}
這裡,接收者實現了,Runnable介面和com.rabbitmq.client.Consumer介面。
實現Runnable介面的目的是為了實現多執行緒,java實現多執行緒的方式有兩種:一種是繼承Thread類,一種是實現Runnable介面。詳情請看這篇文章:http://developer.51cto.com/art/201203/321042.htm。
實現Consumer介面的目的是什麼呢?猿友們應有看到例項一中的接收者程式碼:
//指定消費佇列
channel.basicConsume(QUEUE_NAME, true, consumer);最後一個引數是需要傳遞com.rabbitmq.client.Consumer引數的,實現了Consumer介面之後我們只需要傳遞this就好了。另外,Consumer有很多方法,上面程式碼除了構造方法和run方法(run是實現Runnable介面的),其他都是實現Consumer介面的,這些方法的具體含義,大家可以直接看com.rabbitmq.client.Consumer原始碼。
接下來就是測試類了Test.java:
package com.luo.rabbit.test.two;
public class Test {
public static void main(String[] args) throws Exception{
Receiver receiver = new Receiver("testQueue");
Thread receiverThread = new Thread(receiver);
receiverThread.start();
Sender sender = new Sender("testQueue");
for (int i = 0; i < 5; i++) {
MessageInfo messageInfo = new MessageInfo();
messageInfo.setChannel("test");
messageInfo.setContent("msg" + i);
sender.sendMessage(messageInfo);
}
}
}
執行效果:

記得執行完成之後一定要把程序關掉,不然你每執行一次Test.java就會開啟一個程序,之後會出現什麼問題呢?我是十分建議大家試試,會有驚喜哦,哈哈,驚喜就是,傳送的訊息會平均(數量平均)的出現到各個接收者的控制檯。不妨將傳送的數量改大一點試試。
四、RabbitMQ使用的道具的具體介紹
RabbitMQ是用Erlang實現的一個高併發高可靠AMQP訊息佇列伺服器。
Erlang就是RabbitMQ的一個依賴環境,這裡沒什麼好說的。我們更加關注它的一身表演技巧哪裡來的,這裡就看AMQP吧,看完AMQP之後估計你會對RabbitMQ的理解更加深刻。
開始吧
AMQP當中有四個概念非常重要:虛擬主機(virtual host),交換機(exchange),佇列(queue)和繫結(binding)。一個虛擬主機持有一組交換機、佇列和繫結。為什麼需要多個虛擬主機呢?很簡單,RabbitMQ當中,使用者只能在虛擬主機的粒度進行許可權控制。因此,如果需要禁止A組訪問B組的交換機/佇列/繫結,必須為A和B分別建立一個虛擬主機。每一個RabbitMQ伺服器都有一個預設的虛擬主機“/”。如果這就夠了,那現在就可以開始了。
交換機,佇列,還有繫結……天哪!
剛開始我思維的列車就是在這裡脫軌的…… 這些鬼東西怎麼結合起來的?
佇列(Queues)是你的訊息(messages)的終點,可以理解成裝訊息的容器。訊息就一直在裡面,直到有客戶端(也就是消費者,Consumer)連線到這個佇列並且將其取走為止。不過。你可以將一個佇列配置成這樣的:一旦訊息進入這個佇列,biu~,它就煙消雲散了。這個有點跑題了……
需要記住的是,佇列是由消費者(Consumer)通過程式建立的,不是通過配置檔案或者命令列工具。這沒什麼問題,如果一個消費者試圖建立一個已經存在的佇列,RabbitMQ就會起來拍拍他的腦袋,笑一笑,然後忽略這個請求。因此你可以將訊息佇列的配置寫在應用程式的程式碼裡面。這個概念不錯。
OK,你已經建立並且連線到了你的佇列,你的消費者程式正在百無聊賴的敲著手指等待訊息的到來,敲啊,敲啊…… 沒有訊息。發生了什麼?你當然需要先把一個訊息放進佇列才行。不過要做這個,你需要一個交換機(Exchange)……
交換機可以理解成具有路由表的路由程式,僅此而已。每個訊息都有一個稱為路由鍵(routing key)的屬性,就是一個簡單的字串。交換機當中有一系列的繫結(binding),即路由規則(routes),例如,指明具有路由鍵 “X” 的訊息要到名為timbuku的隊列當中去。先不討論這個,我們有點超前了。
你的消費者程式要負責建立你的交換機們(複數)。啥?你是說你可以有多個交換機?是的,這個可以有,不過為啥?很簡單,每個交換機在自己獨立的程序當中執行,因此增加多個交換機就是增加多個程序,可以充分利用伺服器上的CPU核以便達到更高的效率。例如,在一個8核的伺服器上,可以建立5個交換機來用5個核,另外3個核留下來做訊息處理。類似的,在RabbitMQ的叢集當中,你可以用類似的思路來擴充套件交換機一邊獲取更高的吞吐量。
OK,你已經建立了一個交換機。但是他並不知道要把訊息送到哪個佇列。你需要路由規則,即繫結(binding)。一個繫結就是一個類似這樣的規則:將交換機“desert(沙漠)”當中具有路由鍵“阿里巴巴”的訊息送到佇列“hideout(山洞)”裡面去。換句話說,一個繫結就是一個基於路由鍵將交換機和佇列連線起來的路由規則。例如,具有路由鍵“audit”的訊息需要被送到兩個佇列,“log-forever”和“alert-the-big-dude”。要做到這個,就需要建立兩個繫結,每個都連線一個交換機和一個佇列,兩者都是由“audit”路由鍵觸發。在這種情況下,交換機會複製一份訊息並且把它們分別傳送到兩個隊列當中。交換機不過就是一個由繫結構成的路由表。
現在複雜的東西來了:交換機有多種型別。他們都是做路由的,不過接受不同型別的繫結。為什麼不建立一種交換機來處理所有型別的路由規則呢?因為每種規則用來做匹配分子的CPU開銷是不同的。例如,一個“topic”型別的交換機試圖將訊息的路由鍵與類似“dogs.*”的模式進行匹配。匹配這種末端的萬用字元比直接將路由鍵與“dogs”比較(“direct”型別的交換機)要消耗更多的CPU。如果你不需要“topic”型別的交換機帶來的靈活性,你可以通過使用“direct”型別的交換機獲取更高的處理效率。那麼有哪些型別,他們又是怎麼處理的呢?
五、原始碼工程下載
小寶鴿向來有個壞習慣,即便部落格裡面已經將全部程式碼貼出來了,還是會提供原始碼工程供大家下載,哈哈。
有些時候有些猿友經常會問,寫一篇部落格很花時間吧,我不能假裝跟你說不花時間。雖然花時間,但是當你看到方向,看到了目標,可以將自己學習的東西分享出來,你就會很有動力了,根本停不下來。
本部落格自己查資料,建例項驗證,動手寫部落格,約花了8個小時左右吧。不過當我瞭解到RabbitMQ的博大精深,這些時間都不是事,歡迎關注,雖然剛畢業半年,但小寶鴿會繼續將工作中遇到的技術點分享給大家。