
ElasticSearch的match和match_phrase查詢
阿新 • • 發佈:2018-12-25
問題:
索引中有『第十人民醫院』這個欄位,使用IK分詞結果如下 :
POST http://localhost:9200/development_hospitals/_analyze?pretty&field=hospital.names&analyzer=ik
{ "tokens": [ { "token": "第十", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 }, { "token": "十人", "start_offset": 1, "end_offset": 3, "type": "CN_WORD", "position": 1 }, { "token": "十", "start_offset": 1, "end_offset": 2, "type": "TYPE_CNUM", "position": 2 }, { "token": "人民醫院", "start_offset": 2, "end_offset": 6, "type": "CN_WORD", "position": 3 }, { "token": "人民", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 4 }, { "token": "人", "start_offset": 2, "end_offset": 3, "type": "COUNT", "position": 5 }, { "token": "民醫院", "start_offset": 3, "end_offset": 6, "type": "CN_WORD", "position": 6 }, { "token": "醫院", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 7 } ] }
使用Postman構建match查詢:
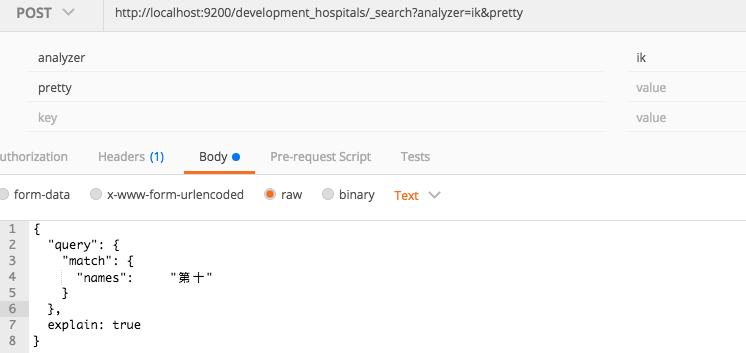 可以得到結果,但是使用match_phrase查詢『第十』卻沒有任何結果
可以得到結果,但是使用match_phrase查詢『第十』卻沒有任何結果
問題分析:
參考文件 The Definitive Guide [2.x] | Elastic
phrase搜尋跟關鍵字的位置有關, 『第十』採用ik_max_word分詞結果如下
雖然『第十』和『十』都可以命中,但是match_phrase的特點是分詞後的相對位置也必須要精準匹配,『第十人民醫院』採用id_max_word分詞後,『第十』和『十』之間有一個『十人』,所以無法命中。{ "tokens": [ { "token": "第十", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 }, { "token": "十", "start_offset": 1, "end_offset": 2, "type": "TYPE_CNUM", "position": 1 } ] }
解決方案:
採用ik_smart分詞可以避免這樣的問題,對『第十人民醫院』和『第十』採用ik_smart分詞的結果分別是:
{ "tokens": [ { "token": "第十", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 }, { "token": "人民醫院", "start_offset": 2, "end_offset": 6, "type": "CN_WORD", "position": 1 } ] }
{
"tokens": [
{
"token": "第十",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
}
]
}
穩穩命中
最佳實踐:
採用match_phrase匹配,結果會非常嚴格,但是也會漏掉相關的結果,個人覺得混合兩種方式進行bool查詢比較好,並且對match_phrase匹配採用boost加權,比如對name進行2種分詞並索引,ik_smart分詞采用match_phrase匹配,ik_max_word分詞采用match匹配,如:
{
"query": {
"bool": {
"should": [
{"match_phrase": {"name1": {"query": "第十", "boost": 2}}},
{"match": {"name2": "第十"}}
]
}
},
explain: true
}