
mysql galera 叢集常見問題處理
解決方案1:
1、等三臺機器恢復網路通訊後,因為此時的mysql已經異常無法加入叢集,因此需要先保證所有的mysql都是down的,再上臺執行/usr/libexec/mysqld --wsrep-new-cluster --wsrep-cluster-address='gcomm://' & 這條命令,並進入mysql(只有一臺機器能夠成功執行,其他機器執行了過幾秒鐘都會異常退出這個程序,我們這裡把能夠成功執行的機器稱為master)
2、此時三臺只有一臺能夠成功進入mysql(即執行mysql這條命令),在非master上的兩臺上一臺一臺的執行systemctl start mysqld,必須等一臺成功了,另一臺才能執行。
3、在mysql中執行show status like "wsrep%";結果如下圖:
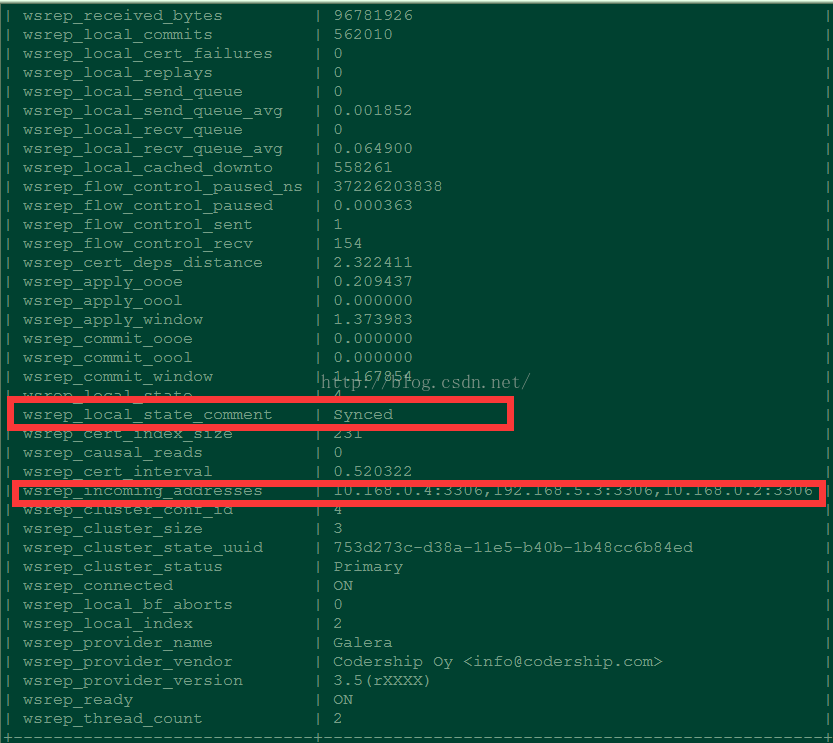
4、保證3的結果是想要的說明叢集已經恢復了,此時需要將master機器上面的/usr/libexec/mysqld --wsrep-new-cluster --wsrep-cluster-address='gcomm://'這個程序kill掉,然後再執行systemctl start mysqld即可
二、mysql HA叢集某個節點無故down了並且有一段時間處於down的情況通過以下方式恢復:
1、若日誌裡面出現以下日誌
160119 14:11:05 [Warning] WSREP: Failed to prepare for incremental state transfer: Local state UUID (00000000-0000-0000-0000-000000000000) does not match group state UUID (eb9f50c6-bc95-11e5-a735-9f48e437dc03): 1 (Operation not permitted)
解決方法:刪除/var/lib/mysql/grastate.dat 檔案(若還存在無法同步的情況則刪除galera.cache檔案)
2、若那個down了的節點出現以下日誌
(異常情況叢集掛了)[ERROR] Found 1 prepared transactions! It means that mysqld was not shut down properly last time and critical recovery information (last binlog or tc.log file) was manually deleted after a crash. You have to start mysqld with --tc-heuristic-recover switch to commit or rollback pending transactions
1、/usr/libexec/mysqld start --innodb_force_recovery=6
1. (SRV_FORCE_IGNORE_CORRUPT):忽略檢查到的corrupt頁。
2. (SRV_FORCE_NO_BACKGROUND):阻止主執行緒的執行,如主執行緒需要執行full purge操作,會導致crash。
3. (SRV_FORCE_NO_TRX_UNDO):不執行事務回滾操作。
4. (SRV_FORCE_NO_IBUF_MERGE):不執行插入緩衝的合併操作。
5. (SRV_FORCE_NO_UNDO_LOG_SCAN):不檢視重做日誌,InnoDB儲存引擎會將未提交的事務視為已提交。
6. (SRV_FORCE_NO_LOG_REDO):不執行前滾的操作。
如果配置後出現以下情況:
130507 14:14:01 InnoDB: Waiting for the background threads to start
130507 14:14:02 InnoDB: Waiting for the background threads to start
130507 14:14:03 InnoDB: Waiting for the background threads to start
130507 14:14:04 InnoDB: Waiting for the background threads to start
130507 14:14:05 InnoDB: Waiting for the background threads to start
130507 14:14:06 InnoDB: Waiting for the background threads to start
130507 14:14:07 InnoDB: Waiting for the background threads to start
130507 14:14:08 InnoDB: Waiting for the background threads to start
130507 14:14:09 InnoDB: Waiting for the background threads to start
需要在galera.cfg中新增這一下:
如果在設定 innodb_force_recovery >2 的同時innodb_purge_thread = 0
2、mysqld --tc-heuristic-recover=ROLLBACK
3、刪除/var/lib/mysql/ib_logfile*
4、當某個mysql節點掛了,並且存在三個mysql所在host有不同的網段,當mysql想重新加入需要一個sst的過程,sst時會需要知道叢集中某個節點的ip因此需要制定引數--wsrep-sst-receive-address否則可能出現同步的ip不在三臺機器所共有的網段
解決參考:
http://blog.itpub.net/22664653/viewspace-1441389/
三、一個mysql節點若down了一段時間。重新啟動的時候需要一些時間去同步資料,服務的啟動超時時間不夠,導致服務無法啟動,解決方法如下:
The correct way to adjust systemd settings so they don't get overwritten is to create a directory and file as such:
/etc/systemd/system/mariadb.service.d/timeout.conf
[Service]
TimeoutStartSec=12min
或者直接修改/usr/lib/systemd/system/mariadb.service
[Service]
TimeoutStartSec=12min
這裡的時間最少要大於90s,預設是90s之後執行 systemctl daemon-reload再重啟服務即可
四、日誌中出現類似如下錯誤:
160428 13:54:49 [ERROR] Slave SQL: Error 'Table 'manage_operations' already exists' on query. Default database: 'horizon'. Query: 'CREATE TABLE `manage_operations` (
`id` integer AUTO_INCREMENT NOT NULL PRIMARY KEY,
`name` varchar(50) NOT NULL,
`type` varchar(20) NOT NULL,
`operation` varchar(20) NOT NULL,
`status` varchar(20) NOT NULL,
`time` date NOT NULL,
`operator` varchar(50) NOT NULL
) default charset=utf8', Error_code: 1050
160428 13:54:49 [Warning] WSREP: RBR event 1 Query apply warning: 1, 28585
160428 13:54:49 [Warning] WSREP: Ignoring error for TO isolated action: source: 752eecd1-0ce0-11e6-83fc-3e0502d0bdd2 version: 3 local: 0 state: APPLYING flags: 65 conn_id: 24053 trx_id: -1 seqnos (l: 28668, g: 28585, s: 28584, d: 28584, ts: 80224119986850)
導致程序異常關閉,
此時可以通過執行mysqladmin flush-tables來重新整理表項,這個問題的原因是三個節點之間的表同步存在問題,重新整理一下表即可
五、日誌出現以下錯誤:
160520 10:48:23 [Note] WSREP: COMMIT failed, MDL released: 367194
160520 10:48:23 [Note] WSREP: cert failure, thd: 358780 is_AC: 0, retry: 0 - 1 SQL: commit
160520 10:48:23 [Note] WSREP: cert failure, thd: 358784 is_AC: 0, retry: 0 - 1 SQL: commit
160520 10:48:23 [Note] WSREP: COMMIT failed, MDL released: 367188
160520 10:48:23 [Note] WSREP: cert failure, thd: 359683 is_AC: 0, retry: 0 - 1 SQL: commit
160520 10:48:23 [Note] WSREP: cert failure, thd: 358808 is_AC: 0, retry: 0 - 1 SQL: commit
160520 10:48:23 [Note] WSREP: cert failure, thd: 367191 is_AC: 0, retry: 0 - 1 SQL: commit
160520 10:48:23 [Note] WSREP: cert failure, thd: 367196 is_AC: 0, retry: 0 - 1 SQL: commit
160520 10:48:23 [Note] WSREP: cert failure, thd: 367194 is_AC: 0, retry: 0 - 1 SQL: commit
160520 10:48:23 [Note] WSREP: cert failure, thd: 367188 is_AC: 0, retry: 0 - 1 SQL: commit
8、日誌出現以下錯誤:
160820 3:13:41 [ERROR] Error in accept: Too many open files
160820 3:19:42 [ERROR] Error in accept: Too many open files
160827 3:16:24 [ERROR] Error in accept: Too many open files
160831 17:20:52 [ERROR] Error in accept: Too many open files
160831 19:54:29 [ERROR] Error in accept: Too many open files
160831 20:21:53 [ERROR] Error in accept: Too many open files
160901 11:25:57 [ERROR] Error in accept: Too many open files
解決方法
vim /usr/lib/systemd/system/mariadb.service
[Service]
LimitNOFILE=10000
預設的mysql的open_file_limits是1024將該項增大,並且修改vim /etc/my.cnf.d/server.cnf該檔案的open_files_limit值
systemctl daemon-reload
systemctl restart mysqld
檢視mysql的open_file_limits值是否調整成功
cat /proc/$pid/limit
其中$pid為mysql程序的pid看看值是否調整成功,並看看日誌是否還會出現上述錯誤