
實戰體驗幾種MySQL Cluster方案
1.背景
MySQL的cluster方案有很多官方和第三方的選擇,選擇多就是一種煩惱,因此,我們考慮MySQL資料庫滿足下三點需求,考察市面上可行的解決方案:
- 高可用性:主伺服器故障後可自動切換到後備伺服器
- 可伸縮性:可方便通過指令碼增加DB伺服器
- 負載均衡:支援手動把某公司的資料請求切換到另外的伺服器,可配置哪些公司的資料服務訪問哪個伺服器
需要選用一種方案滿足以上需求。在MySQL官方網站上參考了幾種解決方案的優缺點:
綜合考慮,決定採用MySQL Fabric和MySQL Cluster方案,以及另外一種較成熟的叢集方案Galera Cluster進行預研。
2.MySQLCluster
簡介:
MySQL Cluster 是MySQL 官方叢集部署方案,它的歷史較久。支援通過自動分片支援讀寫擴充套件,通過實時備份冗餘資料,是可用性最高的方案,聲稱可做到99.999%的可用性。
架構及實現原理:
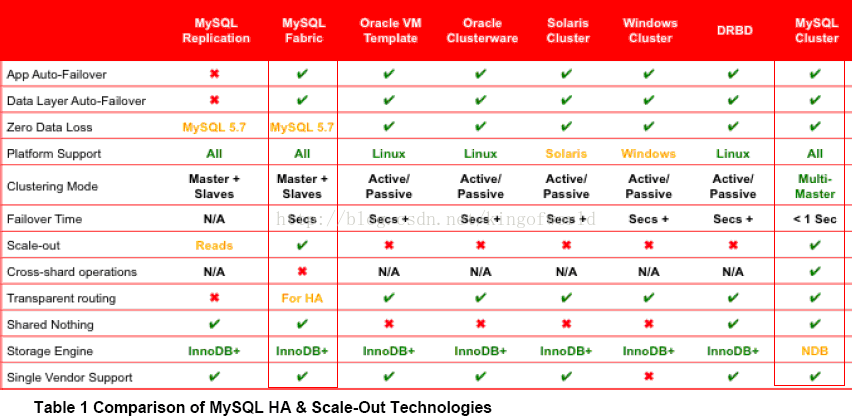
MySQL cluster主要由三種類型的服務組成:
- NDB Management Server:管理伺服器主要用於管理cluster中的其他型別節點(Data Node和SQL Node),通過它可以配置Node資訊,啟動和停止Node。
- SQL Node:在MySQL Cluster中,一個SQL Node就是一個使用NDB引擎的mysql server程序,用於供外部應用提供叢集資料的訪問入口。
- Data Node:用於儲存叢集資料;系統會盡量將資料放在記憶體中。
缺點及限制:
- 對需要進行分片的表需要修改引擎Innodb為NDB,不需要分片的可以不修改。
- NDB的事務隔離級別只支援Read Committed,即一個事務在提交前,查詢不到在事務內所做的修改;而Innodb支援所有的事務隔離級別,預設使用Repeatable Read,不存在這個問題。
- 外來鍵支援:雖然最新的Cluster版本已經支援外來鍵,但效能有問題(因為外來鍵所關聯的記錄可能在別的分片節點中),所以建議去掉所有外來鍵。
- Data Node節點資料會被儘量放在記憶體中,對記憶體要求大。
資料庫系統提供了四種事務隔離級別:
A.Serializable(序列化):一個事務在執行過程中完全看不到其他事務對資料庫所做的更新(事務執行的時候不允許別的事務併發執行。事務序列化執行,事務只能一個接著一個地執行,而不能併發執行。)。
B.Repeatable Read(可重複讀):一個事務在執行過程中可以看到其他事務已經提交的新插入的記錄,但是不能看到其他其他事務對已有記錄的更新。
C.Read Commited(讀已提交資料):一個事務在執行過程中可以看到其他事務已經提交的新插入的記錄,而且能看到其他事務已經提交的對已有記錄的更新。
D.Read Uncommitted(讀未提交資料):一個事務在執行過程中可以看到其他事務沒有提交的新插入的記錄,而且能看到其他事務沒有提交的對已有記錄的更新。
3.MySQL Fabric
簡介:
為了實現和方便管理MySQL 分片以及實現高可用部署,Oracle在2014年5月推出了一套為各方寄予厚望的MySQL產品 -- MySQL Fabric, 用來管理MySQL 服務,提供擴充套件性和容易使用的系統,Fabric當前實現了兩個特性:高可用和使用資料分片實現可擴充套件性和負載均衡,這兩個特效能單獨使用或結合使用。
MySQL Fabric 使用了一系列的python指令碼實現。
應用案例:由於該方案在去年才推出,目前在網上暫時沒搜尋到有大公司的應用案例。
架構及實現原理:
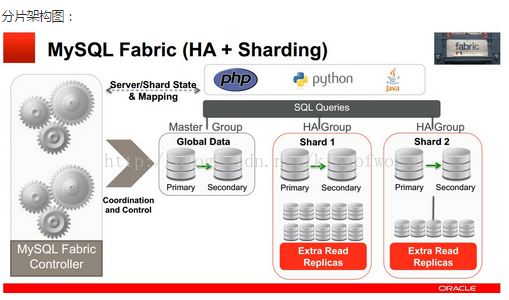
Fabric支援實現高可用性的架構圖如下:
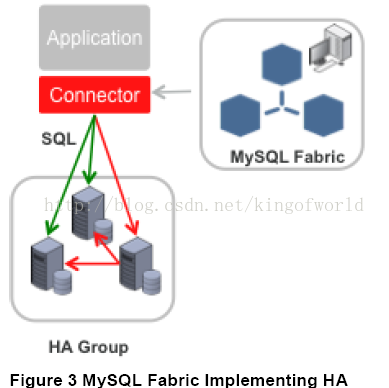
Fabric使用HA組實現高可用性,其中一臺是主伺服器,其他是備份伺服器, 備份伺服器通過同步複製實現資料冗餘。應用程式使用特定的驅動,連線到Fabric 的Connector元件,當主伺服器發生故障後,Connector自動升級其中一個備份伺服器為主伺服器,應用程式無需修改。
Fabric支援可擴充套件性及負載均衡的架構如下:
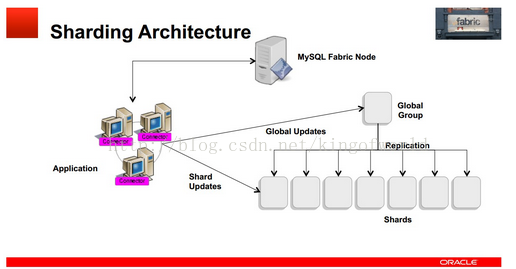
使用多個HA 組實現分片,每個組之間分擔不同的分片資料(組內的資料是冗餘的,這個在高可用性中已經提到)
應用程式只需向connector傳送query和insert等語句,Connector通過MasterGroup自動分配這些資料到各個組,或從各個組中組合符合條件的資料,返回給應用程式。
缺點及限制:
影響比較大的兩個限制是:
- 自增長鍵不能作為分片的鍵;
- 事務及查詢只支援在同一個分片內,事務中更新的資料不能跨分片,查詢語句返回的資料也不能跨分片。

測試高可用性
伺服器架構:
功能 | IP | Port |
Backing store(儲存各伺服器配置資訊) | 200.200.168.24 | 3306 |
Fabric 管理程序(Connector) | 200.200.168.24 | 32274 |
HA Group 1 -- Master | 200.200.168.23 | 3306 |
HA Group 1 -- Slave | 200.200.168.25 | 3306 |
安裝過程省略,下面講述如何設定高可用組、新增備份伺服器等過程
首先,建立高可用組,例如組名group_id-1,命令:
mysqlfabric group create group_id-1
往組內group_id-1新增機器200.200.168.25和200.200.168.23:
mysqlfabric group add group_id-1 200.200.168.25:3306
mysqlfabric group add group_id-1 200.200.168.23:3306
然後檢視組內機器狀態:
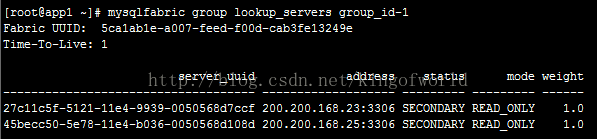
由於未設定主伺服器,兩個服務的狀態都是SECONDARY
提升其中一個為主伺服器:
mysqlfabric group promote group_id-1 --slave_id 00f9831f-d602-11e3-b65e-0800271119cb
然後再檢視狀態:

設定成主伺服器的服務已經變成Primary。
另外,mode屬性表示該伺服器是可讀寫(READ_WRITE),或只讀(READ_ONLY),只讀表示可以分攤查詢資料的壓力;只有主伺服器能設定成可讀寫(READ_WRITE)。
這時檢查25伺服器的slave狀態:
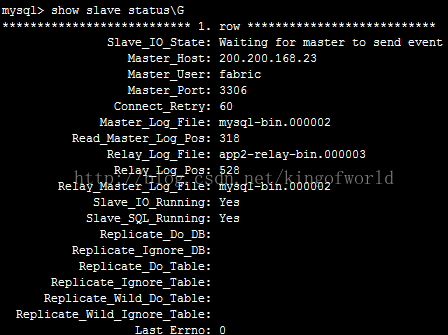
可以看到它的主伺服器已經指向23
然後啟用故障自動切換功能:
mysqlfabric group activate group_id-1
啟用後即可測試服務的高可以性
首先,進行狀態測試:
停止主伺服器23

然後檢視狀態:
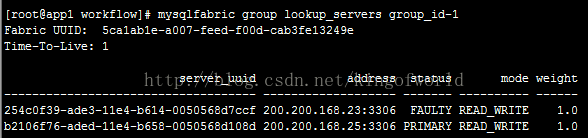
可以看到,這時將25自動提升為主伺服器。
但如果將23恢復起來後,需要手動重新設定23為主伺服器。
實時性測試:
目的:測試在主服務更新資料後,備份伺服器多久才顯示這些資料
測試案例:使用java程式碼建連線,往某張表插入100條記錄,看備份伺服器多久才能同步這100條資料
測試結果:
表中原來有101條資料,執行程式後,檢視主伺服器的資料條數:
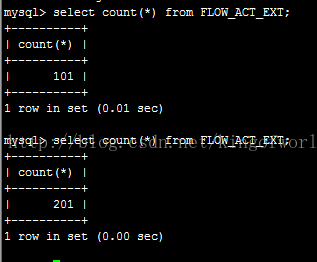
可見主伺服器當然立即得到更新。
檢視備份伺服器的資料條數:
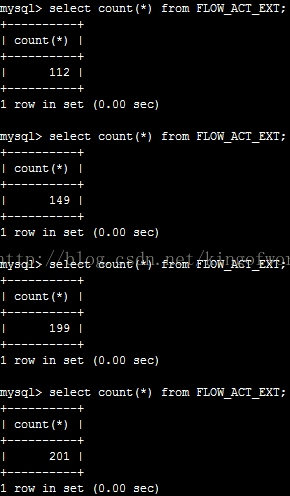
但備份伺服器等待了1-2分鐘才同步完成(可以看到fabric使用的是非同步複製,這是預設方式,效能較好,主伺服器不用等待備份伺服器返回,但同步速度較慢)
對於從伺服器同步資料穩定性問題,有以下解決方案:
- 使用半同步加強資料一致性:非同步複製能提供較好的效能,但主庫只是把binlog日誌傳送給從庫,動作就結束了,不會驗證從庫是否接收完畢,風險較高。半同步複製會在傳送給從庫後,等待從庫傳送確認資訊後才返回。
- 可以設定從庫中同步日誌的更新方式,從而減少從庫同步的延遲,加快同步速度。
在mysql中執行
install plugin rpl_semi_sync_master soname 'semisync_master.so';
install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
SET GLOBAL rpl_semi_sync_master_enabled=ON;
SET GLOBAL rpl_semi_sync_slave_enabled=ON;
修改my.cnf :
rpl_semi_sync_master_enabled=1
rpl_semi_sync_slave_enabled=1
sync_relay_log=1
sync_relay_log_info=1
sync_master_info=1
穩定性測試:
測試案例:使用java程式碼建連線,往某張表插入1w條記錄,插入過程中將其中的master伺服器停了,看備份伺服器是否有這1w筆記錄
測試結果,停止主伺服器後,java程式丟擲異常:

但這時再次傳送sql命令,可以成功返回。證明只是當時的事務失敗了。連線切換到了備份伺服器,仍然可用。
翻閱了mysql文件,有章節說明了這個問題:

裡面提到:當主伺服器當機時,我們的應用程式雖然是不需做任何修改的,但在主伺服器被備份伺服器替換前,某些事務會丟失,這些可以作為正常的mysql錯誤來處理。
資料完整性校驗:
測試主伺服器停止後,備份伺服器是否能夠同步所有資料。
重啟了剛才停止主伺服器後,檢視記錄數

可以看到在插入1059條記錄後被停止了。
現在看看備份伺服器的記錄數是多少,看看在主伺服器當機後是否所有資料都能同步過來
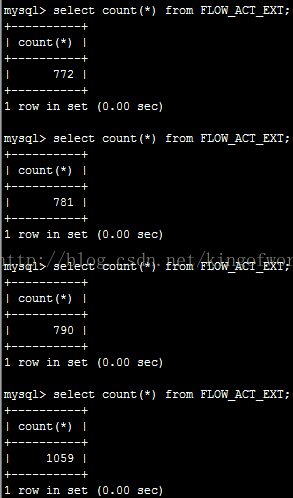
大約經過了幾十秒,才同步完,資料雖然不是立即同步過來,但沒有丟失。
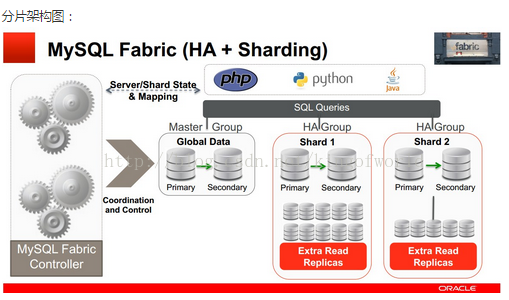
1.2、分片:如何支援可擴充套件性和負載均衡
fabric分片簡介:當一臺機器或一個組承受不了服務壓力後,可以新增伺服器分攤讀寫壓力,通過Fabirc的分片功能可以將某些表中資料分散儲存到不同伺服器。我們可以設定分配資料儲存的規則,通過在表中設定分片key設定分配的規則。另外,有些表的資料可能並不需要分片儲存,需要將整張表儲存在同一個伺服器中,可以將設定一個全域性組(Global Group)用於儲存這些資料,儲存到全域性組的資料會自動拷貝到其他所有的分片組中。
4.Galera Cluster
簡介:
Galera Cluster號稱是世界上最先進的開源資料庫叢集方案

主要優點及特性:
- 真正的多主服務模式:多個服務能同時被讀寫,不像Fabric那樣某些服務只能作備份用
- 同步複製:無延遲複製,不會產生資料丟失
- 熱備用:當某臺伺服器當機後,備用伺服器會自動接管,不會產生任何當機時間
- 自動擴充套件節點:新增伺服器時,不需手工複製資料庫到新的節點
- 支援InnoDB引擎
- 對應用程式透明:應用程式不需作修改

架構及實現原理:
首先,我們看看傳統的基於mysql Replication(複製)的架構圖:
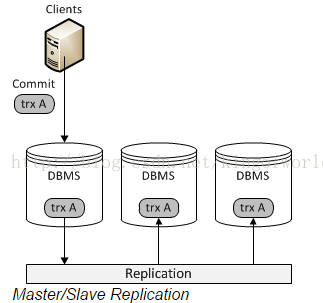
Replication方式是通過啟動複製執行緒從主伺服器上拷貝更新日誌,讓後傳送到備份伺服器上執行,這種方式存在事務丟失及同步不及時的風險。Fabric以及傳統的主從複製都是使用這種實現方式。
而Galera則採用以下架構保證事務在所有機器的一致性:
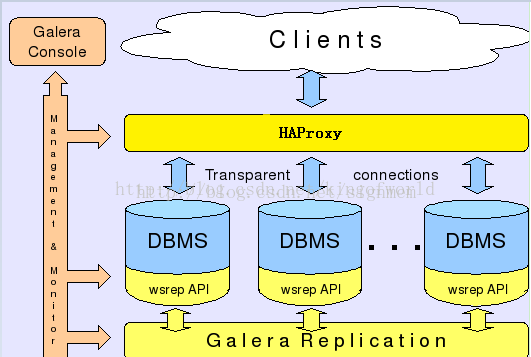
客戶端通過Galera Load Balancer訪問資料庫,提交的每個事務都會通過wsrep API 在所有伺服器中執行,要不所有伺服器都執行成功,要不就所有都回滾,保證所有服務的資料一致性,而且所有伺服器同步實時更新。
缺點及限制:
- 由於同一個事務需要在叢集的多臺機器上執行,因此網路傳輸及併發執行會導致效能上有一定的消耗。
- 所有機器上都儲存著相同的資料,全冗餘。
- 若一臺機器既作為主伺服器,又作為備份伺服器,出現樂觀鎖導致rollback的概率會增大,編寫程式時要小心。
- 不支援的SQL:LOCK / UNLOCK TABLES / GET_LOCK(), RELEASE_LOCK()…
- 不支援XA Transaction
目前基於Galera Cluster的實現方案有三種:Galera Cluster for MySQL、Percona XtraDB Cluster、MariaDB Galera Cluster。
我們採用較成熟、應用案例較多的Percona XtraDB Cluster。
應用案例:
超過2000多家外國企業使用:
包括:

叢集部署架構:
功能 | IP | Port |
Backing store(儲存各伺服器配置資訊) | 200.200.168.24 | 3306 |
Fabric 管理程序(Connector) | 200.200.168.24 | 32274 |
HA Master 1 | 200.200.168.24 | 3306 |
HA Master 2 | 200.200.168.25 | 3306 |
HA Master 3 | 200.200.168.23 | 3306 |
4.1、測試資料同步
在機器24上建立一個表:
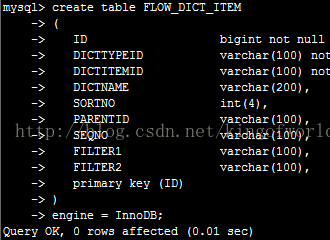
立即在25 中檢視,可見已被同步建立
使用Java程式碼在24伺服器上插入100條記錄
立即在25伺服器上檢視記錄數
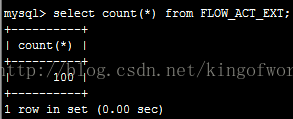
可見資料同步是立即生效的。
4.2、測試新增叢集節點
新增一個叢集節點的步驟很簡單,只要在新加入的機器上部署好Percona XtraDB Cluster,然後啟動,系統將自動將現存叢集中的資料同步到新的機器上。
現在為了測試,先將其中一個節點服務停止:

然後使用java程式碼在叢集上插入100W資料
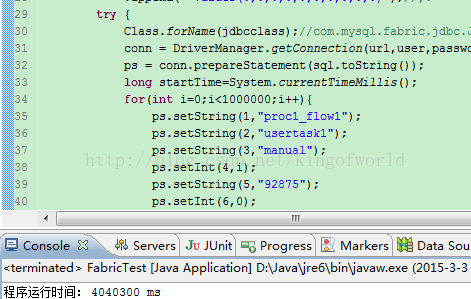
檢視100w資料的資料庫大小:

這時啟動另外一個節點,啟動時即會自動同步叢集的資料:
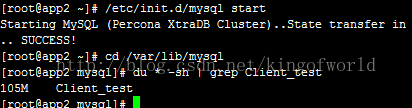
啟動只需20秒左右,檢視資料大小一致,查看錶記錄數,也已經同步過來
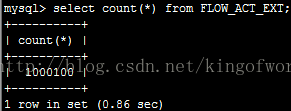
5.對比總結
MySQL Fabric | Galera Cluster | |
使用案例 | 2014年5月才推出,目前在網上暫時沒搜尋到有大公司的應用案例 | 方案較成熟,外國多家網際網路公司使用 |
資料備份的實時性 | 由於使用非同步複製,一般延時幾十秒,但資料不會丟失。 | 實時同步,資料不會丟失 |
資料冗餘 | 使用分片,通過設定分片key規則可以將同一張表的不同資料分散在多臺機器中 | 每個節點全冗餘,沒有分片 |
高可用性 | 通過Fabric Connector實現主伺服器當機後的自動切換,但由於備份延遲,切換後可能不能立即查詢資料 | 使用HAProxy實現。由於實時同步,切換的可用性更高。 |
可伸縮性 | 新增節點後,需要先手工複製叢集資料 | 擴充套件節點十分方便,啟動節點時自動同步叢集資料,100w資料(100M)只需20秒左右 |
負載均衡 | 通過HASharding實現 | 使用HAProxy實現負載均衡 |
程式修改 | 需要切換成jdbc:mysql:fabric的jdbc類和url | 程式無需修改 |
效能對比 | 使用java直接用jdbc插入100條記錄,大概2000+ms | 跟直接操作mysql一樣,直接用jdbc插入100條記錄,大概600ms |
6.實踐應用
綜合考慮上面方案的優缺點,我們比較偏向選擇Galera 如果只有兩臺資料庫伺服器,考慮採用以下資料庫架構實現高可用性、負載均衡和動態擴充套件:
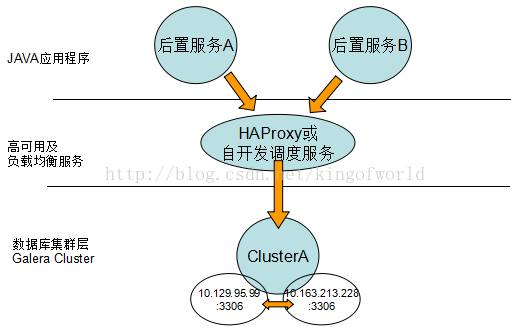
如果三臺機器可以考慮:
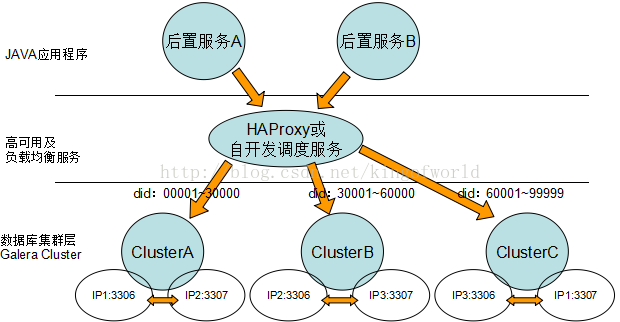
7.參考文件
======================================
前言
高可用架構對於網際網路服務基本是標配,無論是應用服務還是資料庫服務都需要做到高可用。對於一個系統而言,可能包含很多模組,比如前端應用,快取,資料庫,搜尋,訊息佇列等,每個模組都需要做到高可用,才能保證整個系統的高可用。對於資料庫服務而言,高可用可能更復雜,對使用者的服務可用,不僅僅是能訪問,還需要有正確性保證,因此資料庫的高可用方案是一直以來的討論熱點,今天就各種的高可用方案,談一下個人的一些看法,如有錯誤,還請指正!!
一、MySQL主從架構
此種架構,一般初創企業比較常用,也便於後面步步的擴充套件
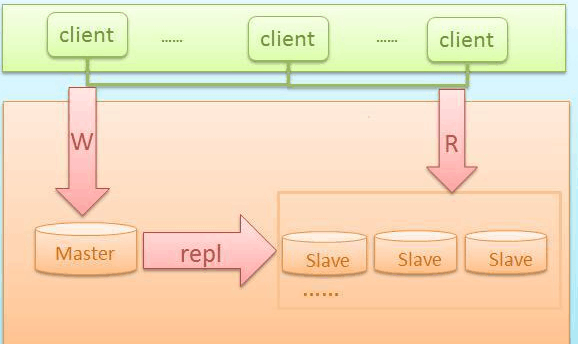 此架構特點:
此架構特點:1、成本低,佈署快速、方便
2、讀寫分離
3、還能通過及時增加從庫來減少讀庫壓力
4、主庫單點故障
5、資料一致性問題(同步延遲造成)
二、MySQL+DRDB架構
通過 DRBD 基於 block 塊的複製模式,快速進行雙主故障切換,很大程度上解決主庫單點故障問題
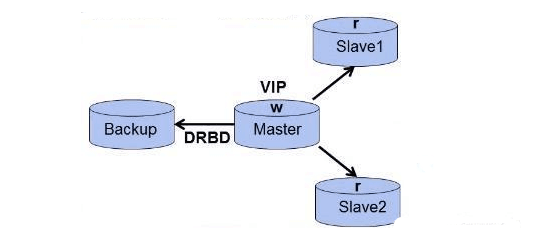 此架構特點:
此架構特點:1、高可用軟體可使用 Heartbeat, 全面負責 VIP、資料與 DRBD 服務的管理
2、主故障後可自動快速切換,並且從庫仍然能通過 VIP 與新主庫進行資料同步
3、從庫也支援讀寫分離,可使用中介軟體或程式實現
三、MySQL+MHA架構
MHA 目前在 Mysql 高可用方案中應該也是比較成熟和常見的方案,它由日本人開發出來,在 mysql 故障切換過程中,MHA 能做到快速自動切換操作,而且還能最大限度保持資料的一致性
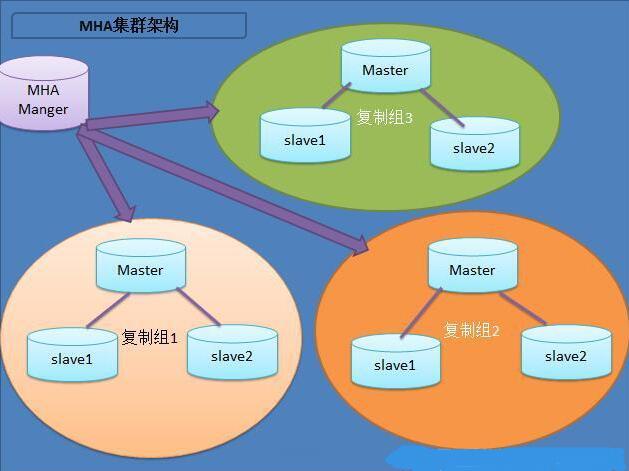 此架構特點:
此架構特點:1、安裝佈署簡單,不影響現有架構
2、自動監控和故障轉移
3、保障資料一致性
4、故障切換方式可使用手動或自動多向選擇
5、適應範圍大(適用任何儲存引擎)
四、MySQL+MMM架構
MMM 即 Master-Master Replication Manager for MySQL(mysql 主主複製管理器),是關於 mysql 主主複製配置的監控、故障轉移和管理的一套可伸縮的指令碼套件(在任何時候只有一個節點可以被寫入),這個套件也能基於標準的主從配置的任意數量的從伺服器進行讀負載均衡,所以你可以用它來在一組居於複製的伺服器啟動虛擬 ip,除此之外,它還有實現資料備份、節點之間重新同步功能的指令碼。
MySQL 本身沒有提供 replication failover 的解決方案,通過 MMM 方案能實現伺服器的故障轉移,從而實現 mysql 的高可用。
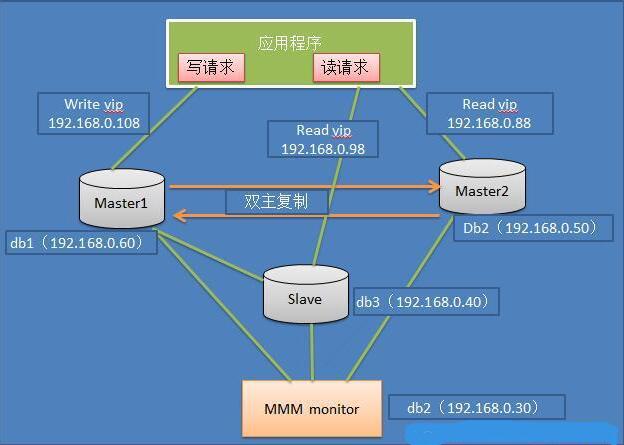 此方案特點:
此方案特點:1、安全、穩定性較高,可擴充套件性好
2、 對伺服器數量要求至少三臺及以上
3、 對雙主(主從複製性要求較高)
4、 同樣可實現讀寫分離
=============================
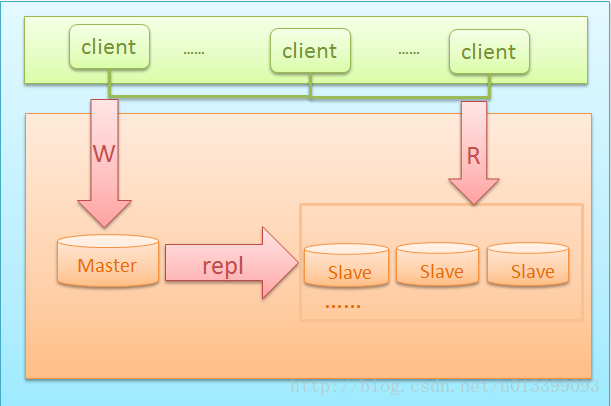
第一種:主從複製+讀寫分離
客戶端通過Master對資料庫進行寫操作,slave端進行讀操作,並可進行備份。Master出現問題後,可以手動將應用切換到slave端。
對於資料實時性要求不是特別嚴格的應用,只需要通過廉價的pc server來擴充套件Slave的數量,將讀壓力分散到多臺Slave的機器上面,即可通過分散單臺數據庫伺服器的讀壓力來解決資料庫端的讀效能瓶頸,畢竟在大多數資料庫應用系統中的讀壓力要比寫壓力大的多。這在很大程度上解決了目前很多中小型網站的資料庫壓力瓶頸問題,甚至有些大型網站也在使用類似的方案解決資料庫瓶頸問題。
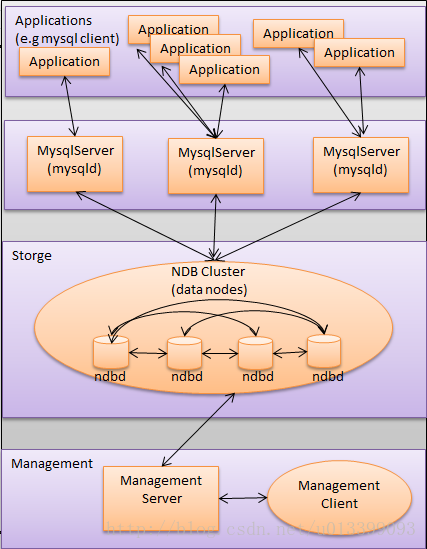
第二種:Mysql Cluster
MySQL Cluster 由一組計算機構成,每臺計算機上均執行著多種程序,包括 MySQL 伺服器,NDB Cluster的資料節點,管理伺服器,以及(可能)專門的資料訪問程式。
由於MySQL Cluster架構複雜,部署費時(通常需要DBA幾個小時的時間才能完成搭建),而依靠 MySQL Cluster Manager 只需一個命令即可完成,但 MySQL Cluster Manager 是收費的。並且業內資深人士認為NDB 不適合大多數業務場景,而且有安全問題。因此,使用的人數較少。
第三種:Heartbeat+雙主從複製
heartbeat 是 Linux-HA 工程的一個元件,heartbeat 最核心的包括兩個部分:心跳監測和資源接管。在指定的時間內未收到對方傳送的報文,那麼就認為對方失效,這時需啟動資源接管模組來接管運 行在對方主機上的資源或者服務
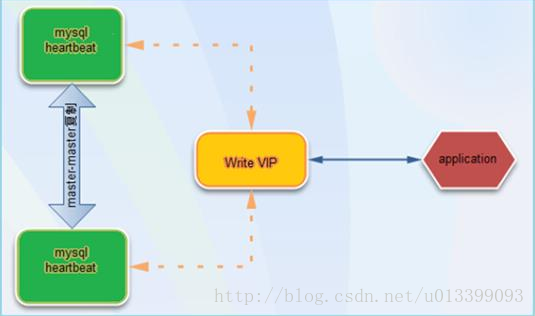
第四種:HeartBeat+DRBD+Mysql
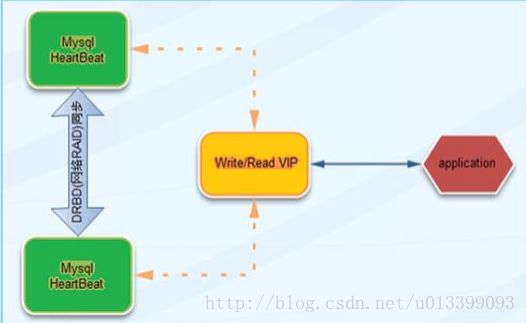
DRBD 是通過網路來實現塊裝置的資料映象同步的一款開源 Cluster 軟體,它自動完成網路中兩個不同服務
器上的磁碟同步,相對於 binlog 日誌同步,它是更底層的磁碟同步,理論上 DRDB 適合很多檔案型系統的高可
用。
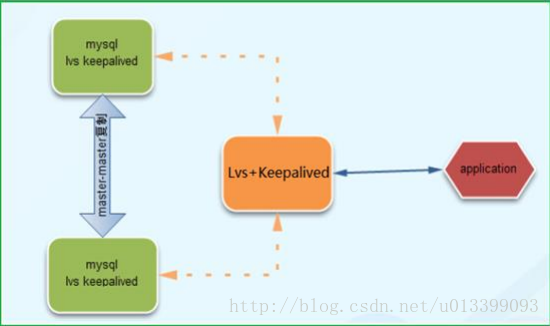
第五種:Lvs+keepalived+雙主複製
Lvs 是一個虛擬的伺服器集群系統,可以實現 LINUX 平臺下的簡單負載均衡。keepalived 是一個類似於
layer3, 4 & 5 交換機制的軟體,主要用於主機與備機的故障轉移,這是一種適用面很廣的負載均衡和高可用方
案,最常用於 Web 系統。
第六種:MariaDB Galera
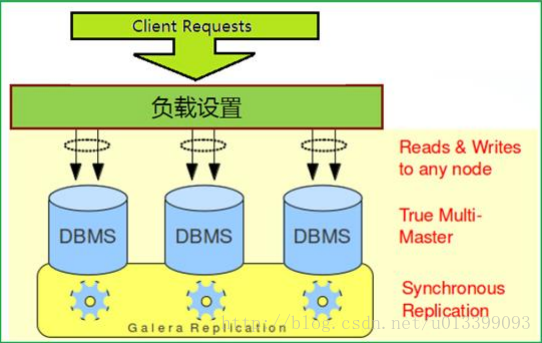
MariaDB Galera Cluster 是一套在mysql innodb儲存引擎上面實現multi-master及資料實時同步的系統架構,業務層面無需做讀寫分離工作,資料庫讀寫壓力都能按照既定的規則分發到 各個節點上去。在資料方面完全相容 MariaDB 和 MySQL。
該架構主要有以下幾種特性:
(1).同步複製 Synchronous replication
(2).Active-active multi-master 拓撲邏輯
(3).可對叢集中任一節點進行資料讀寫
(4).自動成員控制,故障節點自動從叢集中移除
(5).自動節點加入
(6).真正並行的複製,基於行級
(7).直接客戶端連線,原生的 MySQL 介面
(8).每個節點都包含完整的資料副本
(9).多臺資料庫中資料同步由 wsrep 介面實現
其侷限性體現在以下幾點:
(1).目前的複製僅僅支援InnoDB儲存引擎,任何寫入其他引擎的表,包括mysql.*表將不會複製,但是DDL語句會被複制的,因此建立使用者將會被複制,但是insert into mysql.user…將不會被複制的.
(2).DELETE操作不支援沒有主鍵的表,沒有主鍵的表在不同的節點順序將不同,如果執行SELECT…LIMIT… 將出現不同的結果集.
(3).在多主環境下LOCK/UNLOCK TABLES不支援,以及鎖函式GET_LOCK(), RELEASE_LOCK()…
(4).查詢日誌不能儲存在表中。如果開啟查詢日誌,只能儲存到檔案中。
(5).允許最大的事務大小由wsrep_max_ws_rows和wsrep_max_ws_size定義。任何大型操作將被拒絕。如大型的LOAD DATA操作。
(6).由於叢集是樂觀的併發控制,事務commit可能在該階段中止。如果有兩個事務向在叢集中不同的節點向同一行寫入並提交,失敗的節點將中止。對 於叢集級別的中止,叢集返回死鎖錯誤程式碼(Error: 1213 SQLSTATE: 40001 (ER_LOCK_DEADLOCK)).
(7).XA事務不支援,由於在提交上可能回滾。
(8).整個叢集的寫入吞吐量是由最弱的節點限制,如果有一個節點變得緩慢,那麼整個叢集將是緩慢的。為了穩定的高效能要求,所有的節點應使用統一的硬體。
(9).叢集節點建議最少3個。
(10).如果DDL語句有問題將破壞叢集。
==========================================
在這篇文章中,我們將看到不同的MySQL高可用性解決方案,並且檢查它們的優勢與不足。
高可用性環境為資料庫必須保持可用性提供大量的好處。高可用性資料庫環境是跨多臺機器共同部署的一個數據庫,其中任何一個都可以假定資料庫的功能。通過這種方式,資料庫將不會有“單點故障”。
這兒有很多HA策略和解決方案,那麼如何在無數選項中選擇最好的解決方案。首先你要考慮的第一個問題是:你要解決的問題是什麼?答案歸結為冗餘、擴充套件和高可用性,這些並不一定都一樣!
- 在災難事件中需要資料的多個副本
- 需要增加讀/寫的吞吐量
必須儘量減少停機時間
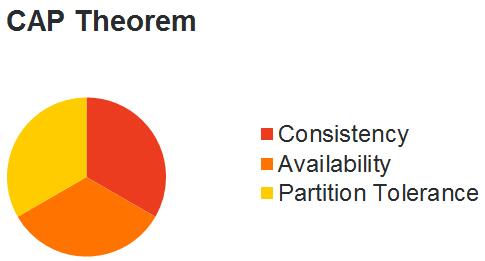
當你規劃你的資料庫環境時,你重要的是要記住CAP定理的應用。CAP定理將問題分成三個類別:一致性、可用性和分割槽容忍性。從這三個中,你可以選擇任意兩個,並犧牲第三個。
- 一致性。所有節點同時看到相同的資料。
- 可用性。每個請求不管成功或者失敗都有響應。
- 分割槽容忍性。儘管任意分割槽會導致網路故障,但系統仍繼續運作。
無論你選擇何種解決方案,它應該最大限度的保持一致性。問題是,雖然MySQL複製是偉大的,它本身並不能保證所有節點的一致性。總有潛在的資料不同步,因為事務可能會在故障轉移中丟失或由於其他原因。Galera-based叢集如Percona XtraDB叢集是以認證為基礎,來防止這種情況發生!
相關推薦
實戰體驗幾種MySQL Cluster方案
1.背景MySQL的cluster方案有很多官方和第三方的選擇,選擇多就是一種煩惱,因此,我們考慮MySQL資料庫滿足下三點需求,考察市面上可行的解決方案:高可用性:主伺服器故障後可自動切換到後備伺服器可伸縮性:可方便通過指令碼增加DB伺服器負載均衡:支援手動把某公司的資料請
什麼是跨域以及幾種簡單解決方案
要明白什麼是跨域之前,首先要明白什麼是同源策略?同源策略就是用來限制從一個源載入的文件或指令碼與來自另一個源的資源進行互動。那怎樣判斷是否是同源呢?如果協議,埠(如果指定了)和主機對於兩個頁面是相同的,則兩個頁面具有相同的源,也就是同源。也就是說,要同時滿足以下3個條件,才能
[python]json.loads 幾種錯誤 解決方案
1、 json.loads Python錯誤: 'utf8' codec can't decode byte ... 由於需求,要用python讀取網頁返回json,並取得其中的資料但是卻遇到以上編碼的問題。 終於找到了解決方案: 我們只需要對字串進行unico
vue中使用echarts圖表自適應的幾種基本解決方案
1.使用window.onresize let myChart = echarts.init(document.getElementById(dom)) window.onresize = function () { myChat.resize() } 優點:可以根據視窗
幾種Dalvik Hook方案研究
Dalvik Hook的基本原理 如上一篇文章所述,每個java方法在虛擬機器內部都對應一個Method結構體(可以將JNI的jmethodID強轉為指向此Method結構體首地址的指標得到),Dalvik Hook通常通過修改Method結構體內容實現.常見
rsync的幾種優化應用方案
rsync是用來做檔案同步的一個很好的工具,傳統的rsync就是使兩個目錄的檔案保持一致,但隨著檔案數量增多,rsync會造成同步緩慢,系統負載比較高,直至系統宕機。 為了解決檔案增多導致rsync變慢的問題,方案是很多的。 1、使源目錄儲存較少檔案
Kubernetes-5-2:Harbor倉庫的幾種高可用方案與搭建
高可用Harbor搭建 思路及介紹 Harbor官方有推出主從架構和雙主架構來實現Harbor的高可用及資料備份。 一、主從架構: 說白了,就是往一臺Harbor倉庫中push映象,然後再通過這臺Harbor分散下發至所有的從Harbor,類似下圖: 這個方法保證了資
MySQL叢集的幾種方案
組建MySQL叢集的幾種方案 LVS+Keepalived+MySQL(有腦裂問題?但似乎很多人推薦這個) DRBD+Heartbeat+MySQL(有一臺機器空餘?Heartbeat切換時間較長?有腦裂問題?) MySQL Proxy(不夠成熟與穩定?使用了Lua?是不是用了他做分表則可以不用更改
Mysql學習總結(54)——MySQL 叢集常用的幾種高可用架構方案
前言高可用架構對於網際網路服務基本是標配,無論是應用服務還是資料庫服務都需要做到高可用。對於一個系統而言,可能包含很多模組,比如前端應用,快取,資料庫,搜尋,訊息佇列等,每個模組都需要做到高可用,才能保
MySQL 快速刪除大量資料(千萬級別)的幾種實踐方案
筆者最近工作中遇見一個性能瓶頸問題,MySQL表,每天大概新增776萬條記錄,儲存週期為7天,超過7天的資料需要在新增記錄前老化。連續執行9天以後,刪除一天的資料大概需要3個半小時(環境:128G, 32核,4T硬碟),而這是不能接受的。當然如果要整個表刪除,毋庸置疑用 TRUNCA
502的幾種解決方案
限制 文件中 tps 運行 pro https pac time 文件 1.FastCGI進程是否已經啟動2.FastCGI worker進程數是否不夠運行 netstat -anpo | grep “php-cgi” | wc -l 判斷是否接近FastCGI進程,接近配
mysql幾種性能測試的工具使用
following files engines 數據庫 連接線 mysql幾種性能測試的工具使用近期由於要比較mysql及其分支mariadb, percona的性能,了解了幾個這方面的工具,包括:mysqlslap sysbench tpcc-mysql,做一個整理,備忘,分享1、mys
mysql的幾種啟動方式
sta allow status option 客戶端連接 mini all res 5.1 mysql的四種啟動方式: 1、mysqld 啟動mysql服務器:./mysqld --defaults-file=/etc/my.cnf --user=root 客戶端連接:
清除float浮動造成影響的幾種解決方案
cor 解決 元素 height blog con ext style oat 1. “清除浮動” ??準確的描述應該是“清除浮動造成的影響” 學習浮動推薦的視頻教程《CSS深入理解之float浮動》 2.如何清除浮動造成
關閉MySQL數據庫的幾種方法
cnblogs shutdown admin min 推薦 pwd port -s stop #1.使用mysqldadmin mysqladmin -uroot -p shutdown mysqladmin -u ${mysql_user} -p${mysql_pw
類成員函數不能作為普通函數地址傳遞給普通函數指針,幾種解決方案
設置 函數指針 glut idle llb .sh c函數 open 百度 代碼如下 #include <iostream> using namespace std; class A { public: int i; public: void
MySql避免重復插入記錄的幾種方法
ble campaign 插入記錄 uniq 文章 select 應用 提高 朋友 本文章來給大家提供三種在mysql中避免重復插入記錄方法,主要是講到了ignore,Replace,ON DUPLICATE KEY UPDATE三種方法,有需要的朋友可以參考一下 方案
Java常見的幾種內存溢出及解決方案
-xmx 系列 lba pan fff 特征 聚類算法 聲明 space 1.JVM Heap(堆)溢出:java.lang.OutOfMemoryError: Java heap space JVM在啟動的時候會自動設置JVM Heap的值, 可以利用JVM提
MySQL 5.6.26幾種安裝包的區別
for 重命名 所有 命令 com hive pass har connect http://downloads.mysql.com/archives/community/ 一、MySQL Installer 5.6.26 mysql-installer-comm
Mysql索引會失效的幾種情況分析
status 過程 ges 此外 ont 其中 like hand ext 轉自:http://www.jb51.net/article/50649.htm 在做項目的過程中,難免會遇到明明給mysql建立了索引,可是查詢還是很緩慢的情況出現,下面我們來具體分析下這種