shell的簡單文字處理命令
阿新 • • 發佈:2018-12-25
########################
6.文字處理
#######################
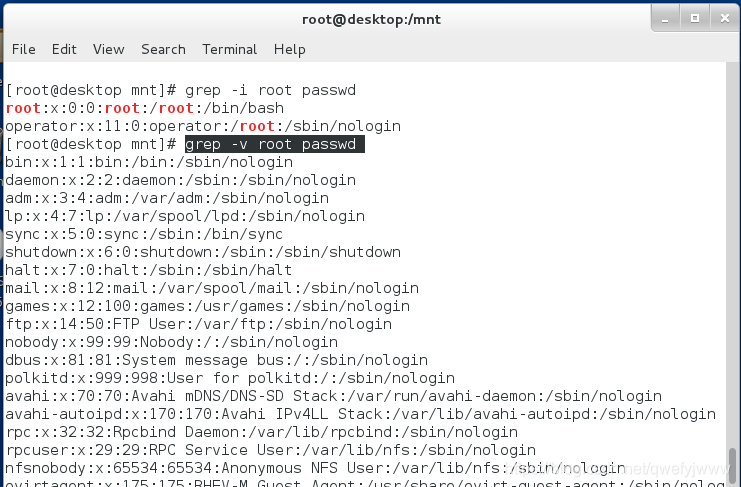
(1)grep
-i (條件)##忽略大小寫
-v ##條件取反
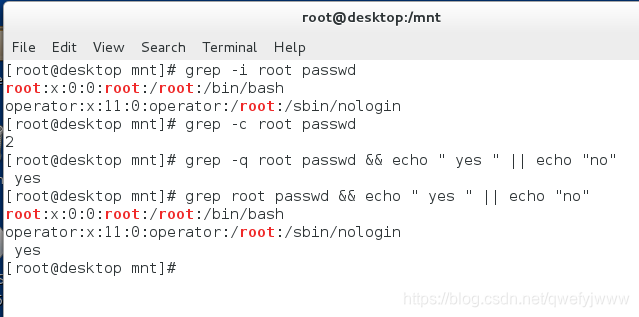
-c ##統計匹配行數
-q ##靜默,無輸出成功就是yes失敗就是no
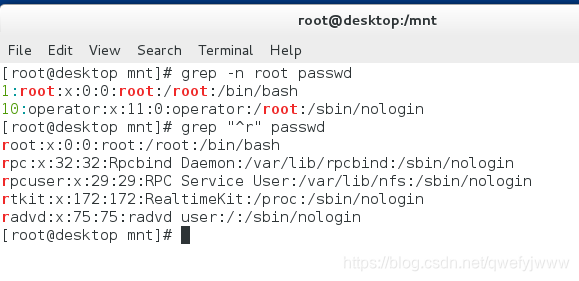
-n ##顯示匹配結果所在的行號
'^r' ##顯示某個檔案內容裡包含r開頭的行
(2)egrep
'^root|^daemon' ##匹配root或daemon開頭的行
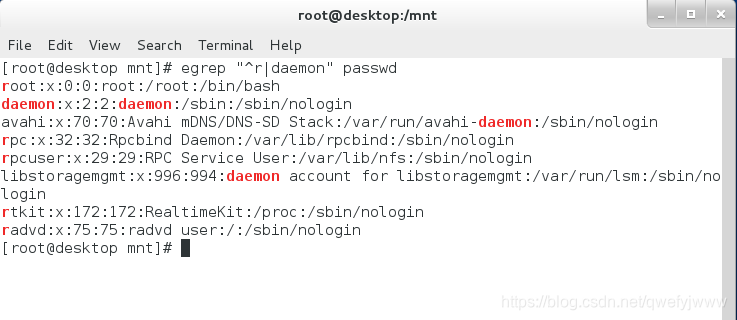
-m10 ‘/sbin/nologin’ ##-m後接行數表示從上到下看匹配所有結果前10行
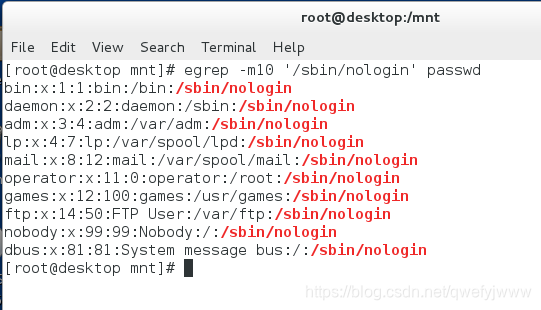
-c '/sbin/nologin' /etc/passwd ##看檔案內包含引號內容的行數
'.' ##匹配所有不包括空行
-v ##條件取反
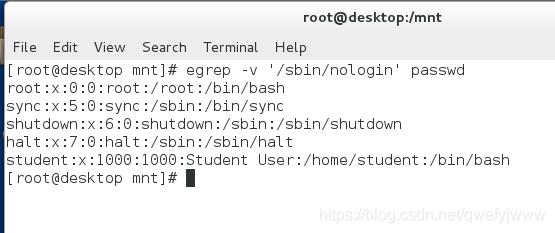
'^$' ##^表示開頭$表示結尾,一開頭就結尾就是匹配空行
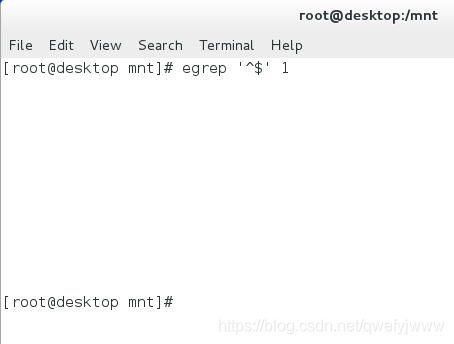
'f+' ##匹配至少有一個f的行
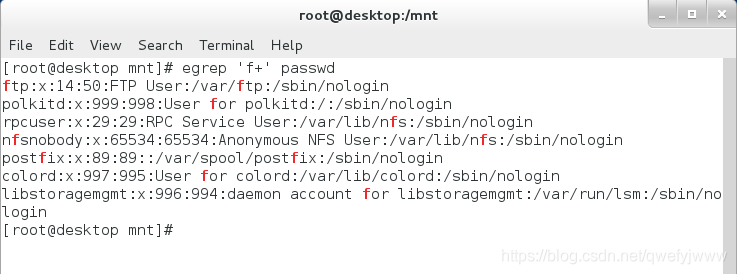
'color(ful)?' ##匹配color或colorful
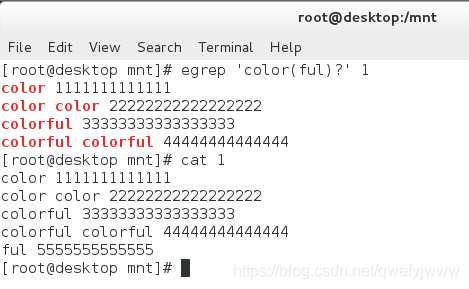
'(we){3}' ##匹配we只匹配三次
'(we){2,4}' ##最少2最多4次
'(we){3,}' ##最少匹配3次無上限
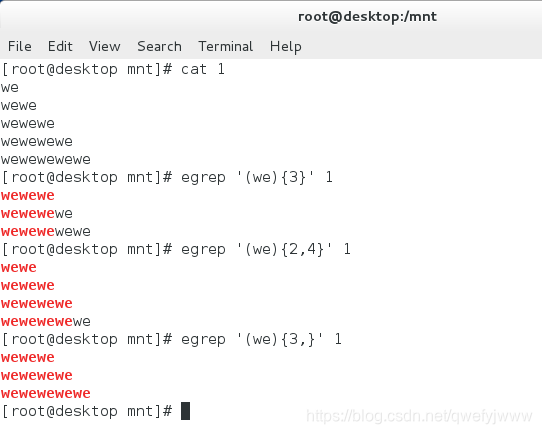
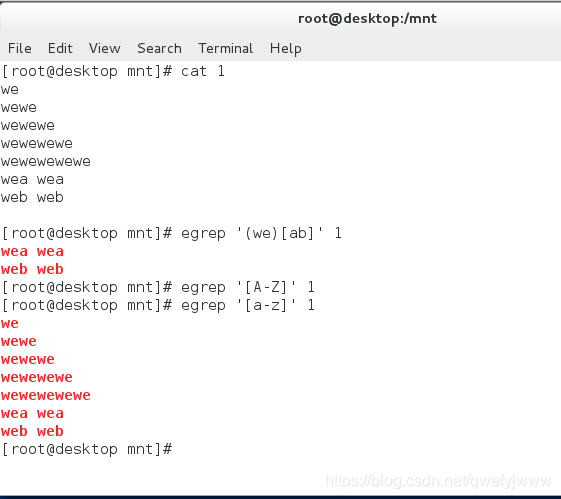
'(we)[ab]' ##匹配we後有a或b
'[A-Z]' ##匹配包含大寫字母A到Z任意一個字母的行
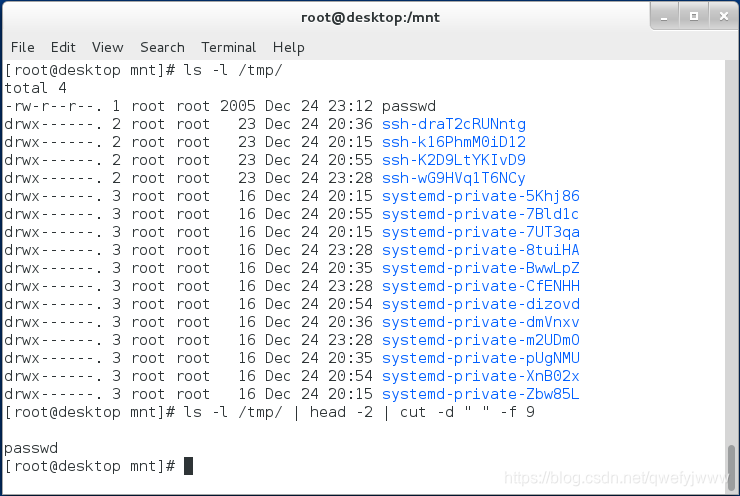
(3)cut
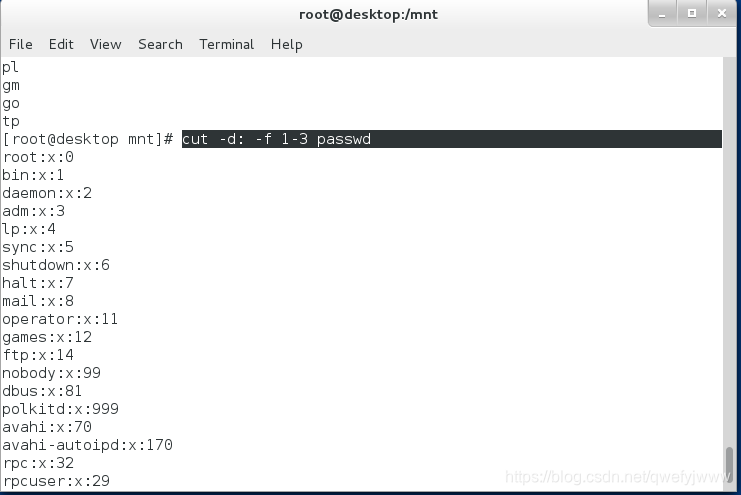
-d : -f 1-3 /etc/passwd ##-d指定分隔符號為:-f指定符號左邊的內容 (1,3為1和3),(1-3為1到3)
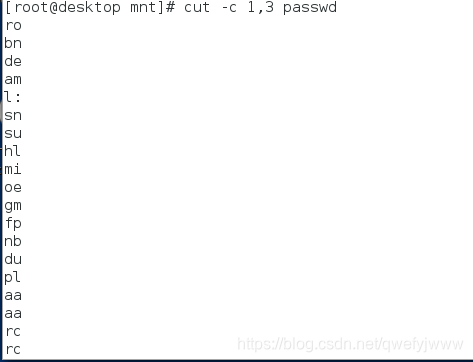
cut -c 1,4 passwd ####顯示第一和第四個字元
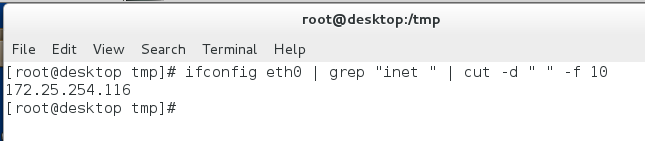
找出主機ip
ifconfig eth0 | grep "inet " | cut -d " " -f 10
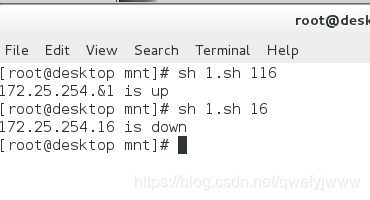
指令碼檢測ip是否在工作
#!/bin/bash
ping -c1 -w1 172.25.254.$1 &> /dev/null && echo "172.25.254.$1 is up" || echo "172.25.254.$1 is down"
###############
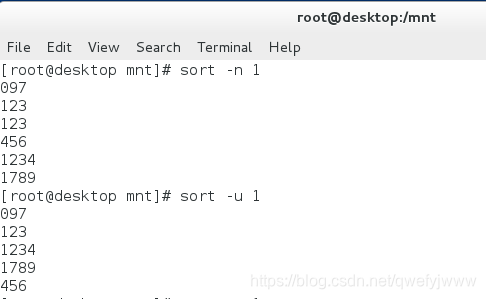
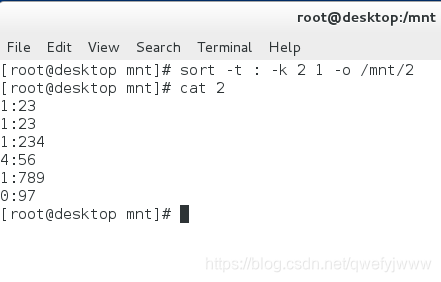
8.sort
################
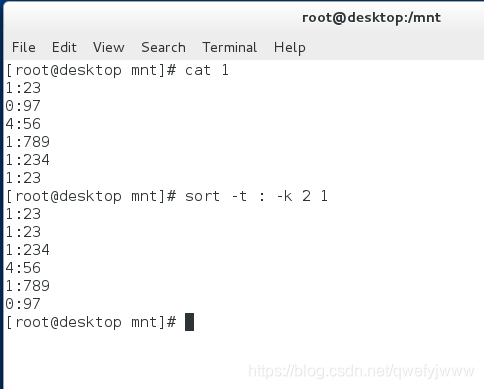
sort (檔案) ##按第一個數字大小排序 -n ##按整體數字大小排序 -u ##去掉重複數字
-t ##指定分隔符
-k ##指定排序的列
-o ##輸出到指定檔案中,可以把排序的結果儲存下來
###############################
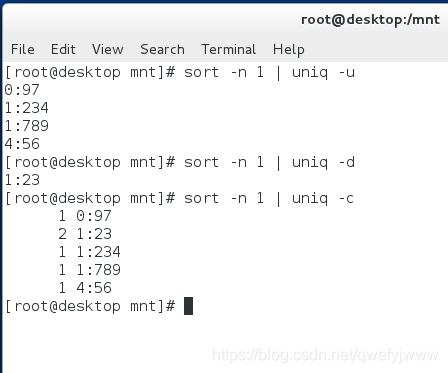
9.uniq命令處理重複字元
###############################
uniq
-u ##顯示唯一的行
-d ##顯示重複的行
-c ##每行顯示一次並統計重複次數
練習:將/tmp目錄中的檔案取出最大的
ls -Sl /tmp/ | head -2 | cut -d " " -f 9