
Python+OpenCV+pytesseract 識別 銀行卡號
首先給大家看下什麼是OCR-A字型:

儘管現代OCR系統不需要專門的字型(如OCR-A),但仍被廣泛應用於身份證,報表和信用卡。
下面給出具體的教程:
1. OCR通過模板匹配與OpenCV結合
在本節中,我們將使用Python + OpenCV實現我們的模板匹配演算法,以自動識別信用卡數字。
為了實現這一點,我們需要應用一些影象處理操作,包括閾值,計算梯度幅度表示,形態運算和輪廓提取。
由於應用了許多影象處理操作來幫助我們檢測和提取信用卡數字,因此當輸入影象通過我們的影象處理流程時,我已經包含了大量的輸入影象中間截圖。
首先,開啟新建一個檔案,命名為:ocr_template_match.py

要安裝/升級imutils,只需使用pip:
$ pip install --upgrade imutils
現在我們已經安裝並匯入了包,我們可以解析我們的命令列引數:
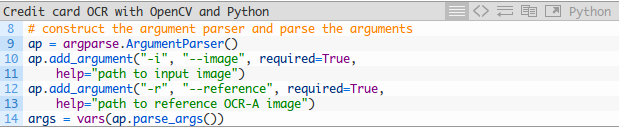
兩個必需的命令列引數是:
- 影象:影象的路徑為OCR'd。
- 參考:參考OCR-A影象的路徑。 該影象包含OCR-A字型中的數字0-9,從而允許我們稍後在管道中執行模板匹配。
接下來我們來定義信用卡型別:

我們通過載入參考OCR-A影象開始我們的影象處理流水線:
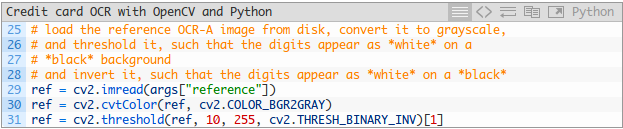
圖4顯示了這些步驟的結果。
現在我們在OCR-A字型影象上找到輪廓:
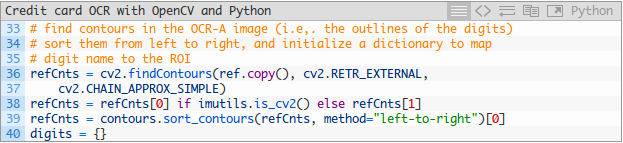
現在,我們應該迴圈瀏覽輪廓,提取ROI並將其與相應的數字相關聯:
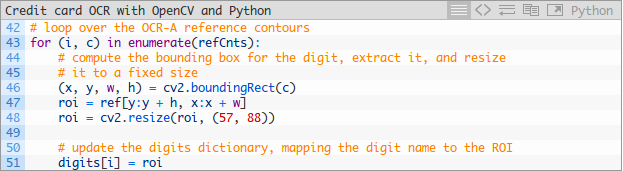
在這一點上,我們完成了從參考影象中提取數字,並將它們與相應的數字名稱相關聯。

我們的下一個目標是在輸入影象中隔離16位數的信用卡號。 我們需要找到並隔離數字,才能啟動模板匹配來識別每個數字。 這些影象處理步驟是非常有趣和有見地的。

我們繼續初始化幾個構造核函式的結構:

現在讓我們準備我們要去OCR的影象:

我們來看看我們的輸入影象:

隨後我們調整大小和灰度級操作:

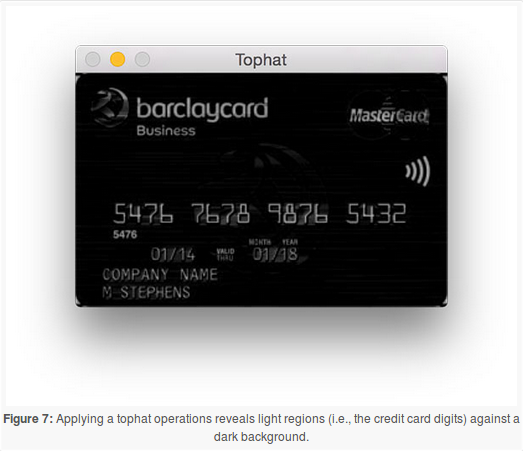
現在我們的形象是灰色的,大小一致,我們來進行一個形態的操作:

頂帽操作可以在下面的結果圖中看到黑暗背景下的亮區(即信用卡號)。
給定我們的tophat影象,我們來計算沿x方向的漸變:
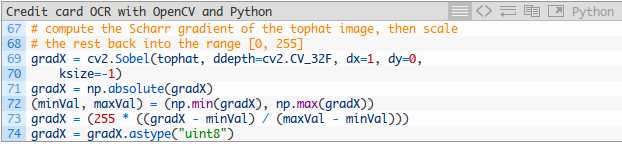
結果如下圖所示:
讓我們繼續改進信用卡數位查詢演算法:
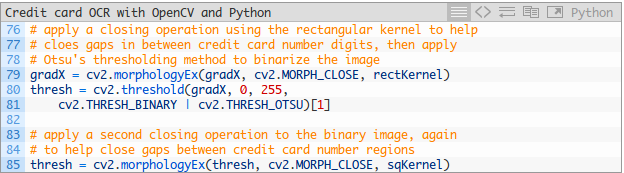
這些步驟的結果如下所示:

接下來,我們找到輪廓並初始化數字分組位置列表。

現在讓我們迴圈瀏覽輪廓,同時根據每個輪廓的寬高比進行過濾,從而使我們從信用卡的其他不相關的區域修剪數字組的位置:
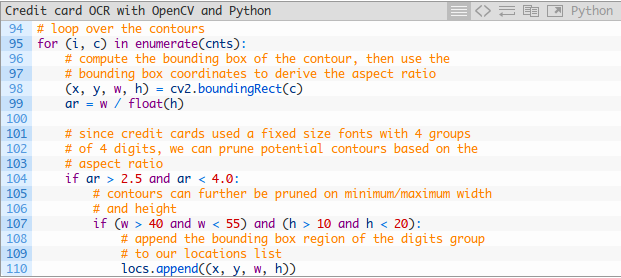
以下圖片顯示了我們發現的分組 - 為了演示的目的,我讓OpenCV在每個組周圍繪製一個邊框:

接下來,我們將從左到右對分組進行排序,並初始化信用卡數位列表:

現在我們知道每個四位數字的位置,讓我們迴圈四個排序的分組,並確定其中的數字。
這個迴圈很長,被分解成三個程式碼塊 - 這是第一個塊:

以下顯示的是一組已被提取的組:
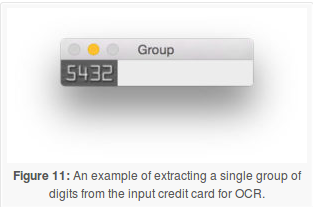
讓我們用一個巢狀迴圈繼續迴圈來做模板匹配和相似性分數提取:
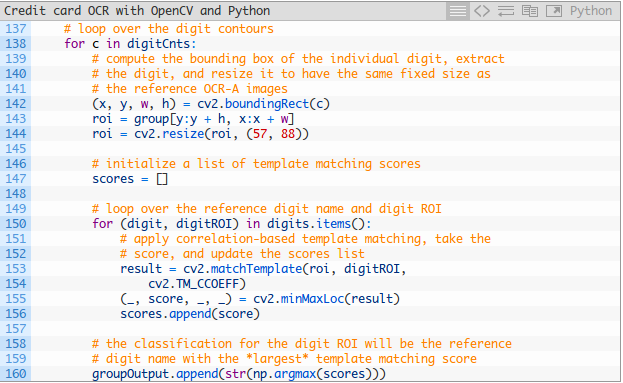
最後,我們圍繞每個組繪製一個矩形,並以紅色文字檢視影象上的信用卡號碼:

要了解指令碼操作是如何的,我們將結果輸出到終端,並在螢幕上顯示我們的影象。

花一點時間來祝賀你 - 你做到了最後。 要重寫(在高級別),這個指令碼:
1)在字典中儲存信用卡型別。
2)獲取參考影象並提取數字。
3)在字典中儲存數字模板。
4)本地化四個信用卡號碼組,每個號碼組分為四位數字(共十六位數字)。
5)提取要匹配的數字。
6)對每個數字執行模板匹配,將每個單獨的ROI與每個數字模板0-9進行比較,同時儲存每次嘗試匹配的分數。
7)找到每個候選人數字的最高分數,並構建一個名為output的列表,其中包含信用卡號碼。
8)將信用卡號和信用卡型別輸出到我們的終端,並將輸出影象顯示在我們的螢幕上。
現在是時候看到指令碼執行,並檢查我們的結果。
2. 信用卡OCR系統展示結果
現在我們已經實現了我們的信用卡OCR系統,讓我們來看一下。(原始碼在下文的原文連結中,直接到“Downloads”模組下填入郵箱後獲取)
我們顯然不能使用真實的信用卡號碼,所以我收集了一些使用Google的信用卡示例圖。 這些信用卡顯然是假的,僅供演示用途。
但是,您可以在此部落格中應用相同的技術來識別實際的真實信用卡上的數字。
要檢視我們的信用卡OCR系統的操作,開啟一個終端並執行以下命令:
$ python ocr_template_match.py --reference ocr_a_reference.png \
--image images/credit_card_05.png我們的第一個結果影象,100%正確:


請注意,只需通過檢查信用卡號碼中的第一位數字即可將信用卡正確標記為萬事達卡。
現在,你已經完成了OCR識別信用卡了,是不是很激動。
最後我們來總結一下:
在本教程中,我們學習瞭如何使用OpenCV和Python使用模板匹配來執行光學字元識別(OCR)。
具體來說,我們應用了我們的模板匹配OCR方法來識別信用卡的型別以及16個信用卡數字。
為了實現這一點,我們將影象處理流程分為四個步驟:
1)通過各種影象處理技術檢測信用卡上的四組數字,包括形態運算,閾值和輪廓提取。
2)從四個分組中提取每個單個數字,導致需要分類的16位數字。
3)通過將模板匹配與OCR-A字型進行比較,以獲得我們的數字分類,將模板匹配應用於每個數字。
4)檢查信用卡號碼的第一位,以確定發行公司。
在評估我們的信用卡OCR系統後,我們發現它是100%準確的,只要髮卡信用卡公司使用OCR-A字型的數字。
要擴充套件此應用程式,您將需要在野外收集信用卡的真實影象,並可能通過標準特徵提取或訓練或卷積神經網路來訓練機器學習模型,以進一步提高該系統的準確性。
附上原文連結:https://www.pyimagesearch.com/2017/07/17/credit-card-ocr-with-opencv-and-python/