
大規模 codis 叢集的治理與實踐
作者介紹:唐聰,後臺開發,目前主要負責部門內公共元件建設、超級會員等產品基礎系統開發等。
一、背景和概況
在2015年末,為了解決各類業務大量的排行榜的需求,我們基於redis實現了一個通用的排行榜服務,良好解決了各類業務的痛點,但是隨著業務發展到2016年中,其中一個業務就申請了數百萬排行榜,並隨著增長趨勢,破千萬指日可待,同時各業務也希望能直接使用redis豐富資料結構來解決更多問題(如儲存關關係鏈、地理位置等)。
當時面臨的問題與挑戰如下:
排行榜服務無法支撐千萬級排行榜數(排行榜到redis例項對映關係儲存在zookeeper,zookeeper容量瓶頸)
單機容量無法滿足關係鏈等業務需求
排行榜和關係鏈大部分大於1M,同時存在超大key(>512M),需支援超大key遷移
SNG的Grocery儲存元件,支援redis協議,但又存在單key value大小1M的限制
高可用,需要支援redis主備自動切換
SNG資料運維組未提供redis叢集版接入服務,在零運維的支援下如何高效治理眾多業務叢集?
面對以上挑戰,經過多維度的方案選型對比,最終選擇了基於codis(3.x版本),結合內部需求和運營環境進行了定製化改造,截止到目前,初步實現了一個支援單機/分散式儲存、平滑擴縮容、超大key遷移、高可用、業務自動化接入排程部署、多維度監控、配置管理、容量管理、運營統計的redis服務平臺,在CMEM、Grocery不能滿足業務需求的場景下,接入了SNG增值產品部等五大部門近30+業務叢集(圖一),350+例項, 2T+容量。
下文將從方案選型、整體架構、自動化接入、資料遷移、高可用、運營實踐等方面詳細介紹我們在生產環境中的實踐情況。
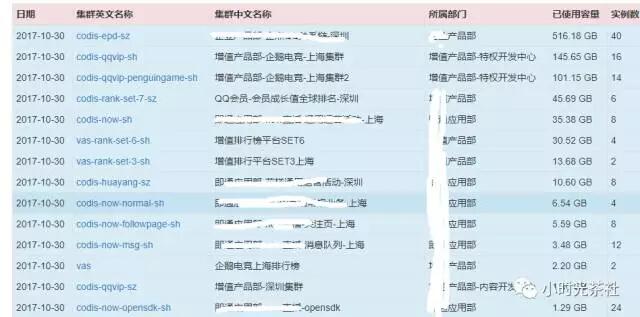
圖一 部分接入業務列表
二、方案選型
Redis因其豐富的資料結構、易用性越來越受到廣大開發者歡迎,根據DB-Engines的最新統計,已經是穩居資料庫產品的top10(見圖一)。雲端計算服務產商AWS、AZURE、阿里雲、騰訊雲都提供了Redis產品,各雲端計算產商主流方案都是基於開源Redis核心做定製化優化,解決Redis不足之處,在提升Redis穩定性、效能的同時最大程度相容開源Redis。單機主備版各廠商差異不大,都是基於原生Redis核心,但是叢集版,AWS使用的原生的Redis自帶的Cluster Mode模式(加強版),,阿里雲基於Proxy、原生Redis核心實現,路由等元儲存資料儲存在RDS,架構類似Codis, 騰訊雲集群版是基於內部Grocery。瞭解完雲端計算產商解決方案,再看業界開源、公司內部,上文提到我們面臨問題之一就是單機容量瓶頸,因此需要一款叢集版產品,目前業界開源的主流的Redis叢集解決方案有Codis,Redis Cluster,Twemproxy,公司內部的有SNG Grocery、IEG的TRedis,從以下幾個維度進行對比,詳細結果如表一所示(2016年10月時資料):
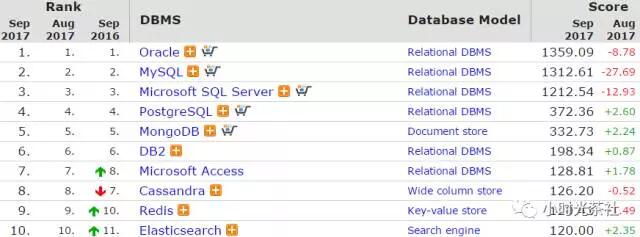
圖二 資料庫流行度排名
| Feature | Codis | Redis Cluster | TwemProxy | Grocery Redis | TRedis |
|---|---|---|---|---|---|
| 儲存引擎 | 基於原生Redis擴充套件增加遷移相關指令 | 原生Redis | 原生Redis | 多階雜湊+LinkTable | Rocksdb/LSM |
| 資料分佈演算法 | 雜湊槽crc16(key) % 1024 | 雜湊槽crc16(key) % 16384 | ketama/modula/random | 一致性hash | 雜湊槽 |
| 平滑擴縮容 | 支援 | 支援 | 不支援 | 支援 | 支援 |
| Value大小限制 | 無 | 無 | 無 | 1M | 無 |
| ZSET實現 | Skiplist + Hash | Skiplist + Hash | Skiplist + Hash | Skiplist + Hash | Skiplist+Hash(記憶體),key-value(磁碟) |
| 開發語言(Proxy) | Go | 採用無中心節點設計,無Proxy | C | C++ | C/C++(基於TwemProxy) |
| 單執行緒/多執行緒/多程序(Proxy) | 多執行緒 | 無 | 單執行緒 | 多程序 | 單執行緒/多執行緒 |
| 超大key遷移(>512M) | 不支援 | 不支援 | 不支援 | - | - |
| 機型 | 記憶體型 | 記憶體型 | 記憶體型 | 記憶體型或SSD IO型 | SSD IO型 |
| Client | 任意 | 需要支援cluster語義 | 任意 | 提供SDK | 任意 |
| Pipeline | 支援 | 不支援 | 支援 | 支援 | 支援 |
| 運維成本 | 低 | 高 | 高 | 無 | 無 |
| 定製開發成本 | 低 | 高 | 高 | 無 | 無 |
表一 Redis叢集產品對比
雲端計算產商和業界開源、公司內部的解決方案從整體架構分類,分別是基於Proxy中心節點和無中心節點,在這點上我們更偏愛基於Proxy中心節點架構設計,運維成本更低、更加可控,從儲存引擎分類,分別是基於原生Redis核心和第三方儲存引擎(如Grocery的多階HASH+LinkTable、TRedis的Rocksdb),在這點上我們更偏愛基於原生Redis核心,因為我們要解決業務場景就是Grocery和CMem無法滿足的地方,我們業務大部分使用的資料結構是ZSET且Key一般超過1M,幾十萬級元素的ZSET Key是常態,Grocery的Value 1M大小限制無法滿足我們的需求,同時我們需要ZSET的ZRank的時間複雜度是O(LogN),基於RocksDb的儲存引擎時間複雜度是O(N),因此這也是無法接受的。隨著業務發展,容量勢必會發生變化,因此擴縮容是常態,而TwemProxy並不支援平滑擴縮容,因此也無法滿足要求。最後,我們需要結合內部運營環境和需求做定製化改造,在零運維的支援下,通過技術手段,最大程度自動化治理、運營眾多多業務叢集,而Codis程式碼結構清晰,開發語言又是現在比較流行的Go,無論是執行效能、還是開發效率都較高效,因此我們最終選擇了Codis.
三、整體架構
基於Codis定製開發而成的Redis服務平臺整體架構如圖二所示,其包含以下元件:
Proxy:實現了Redis協議,除少數命令不支援外,對外表現和原生Redis一樣。解析請求時,計算key對應的雜湊槽,將請求分發到對應的Redis,業務通過L5/CMLB進行定址。
Redis: Redis在記憶體中實現了string/list/hash/set/zset等資料結構,對外提供資料讀寫服務、持久化等,預設一主一備部署。
Dashboard:提供管理叢集的API和訪問元資料儲存的通用API(CURD操作,遮蔽後端元資料儲存差異)。
Zk/Etcd/Mysql:第三方元資料儲存,儲存叢集的proxy、redis、各雜湊槽對應的redis 地址等資訊。
HA:基於Redis Sentinel實現Redis主備高可用,部署在多個IDC,採用Quorum機制、狀態機進行主備自動切換。
Scheduler:排程服務,負責對業務接入申請單進行自動排程部署、叢集自動化擴容、各叢集運營資料統計等。
運維管理系統: Web視覺化管理叢集,提供業務接入、叢集管理、容量管理、配置管理等功能。
CDB:儲存業務申請單、各節點容量等資訊。
Agent:負責定時監控和採集Redis、Proxy、Dashboard執行統計資訊,上報到米格監控系統和CDB。
HDFS:冷備叢集,Redis冷備檔案每天會定時上傳到HDFS,提供給業務下載和在主備皆故障的情況下做資料恢復使用。

圖三 整體架構
四、自動化接入
當面對成百上千乃至上萬個Redis例項時,人工根據業務申請單去過濾無效節點、篩選符合業務要求的節點、再從候選節點中找出最優節點等執行一些列繁瑣枯燥流程,這不僅會導致工作乏味、效率低,而且更會大大提升系統的不穩定性,引發運營事故。當繁瑣、複雜的流程變成自動化後,工作就會變得充滿樂趣,圖三是業務接入排程流程,使用者在運維管理系統提單接入後,排程器會定時從CDB中讀取待排程的業務申請單,首先是篩選過濾流程,此流程包含一系列模組,在設計上是可以動態擴充套件,目前實現的篩選模組如下:
Health: 健康探測模組,過濾宕機、裁測下線的節點IP
Lable:標籤模組,根據業務申請單匹配部署環境(測試、現網)、部署城市、業務模組、Redis儲存型別(單機版、分散式儲存版)
Instance: 檢查當前節點上是否有空餘的Redis例項(篩選Redis例項時)
Capacity: 檢查當前節點CPU、Memory是否超過安全閥值
Role:檢查當前節點角色是否滿足要求(如Redis例項所屬節點機器必須是Redis Node),角色分為三類Proxy Node,Redis Node,Dashboard Node
以上篩選模組,適用Proxy、Redis、Dashboard節點的篩選,在完成以上篩選模組後,返回的是符合要求的候選節點,對候選節點我們又需要對其評分,從中評出最優節點,目前實現的評分模組有最小記憶體排程、最大記憶體排程、最小CPU排程、隨機排程等。

圖四 業務接入排程流程
通過執行以上一系列篩選和評分模組後,就可以準確、快速的獲取到新叢集的Dashboard、Proxy、Redis的部署節點地址,但是離自動化交付給業務使用還差一個重要環節(部署)。目前主要是通過以下三個方面來解決自動化部署,其一,Codis本身是基於配置檔案部署的,每新增一個業務叢集必須在配置檔案指定叢集名字,新建一個PKG包,維護成本非常高,我們通過監聽指定網絡卡+核心配置項遷移到ZooKeeper,實現配置管理API化,同時部署包標準統一化。其二,在各節點上都會部署Agent,Agent會定時採集上報各節點資訊入庫到容量表,無需人工干預,容量管理自動化,未使用的例項形成一個小型資源buffer池。其三,部署是個多階段的流程,需要分解成各狀態,並保證每個狀態都是可重入、冪等性的,當所有狀態完成後,則排程結束,某狀態失敗時,下次排程檢查到申請單非完成狀態,會自動重試失敗的流程,直至完成,拆分後的部署狀態流程圖如圖四所示。
通過以上兩個核心流程,自動化排程分配例項+自動化部署,我們可以將部署時間從最開始的15min+,優化到秒級,在大大提升工作效率的同時,提升了系統穩定性、避免了人為操作錯誤引起的運營事故。
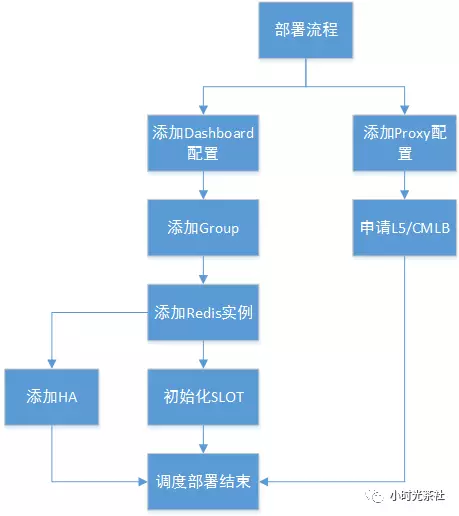
圖五 自動化部署流程
五、資料遷移
擴縮容是儲存系統的常歸化操作,理想中的資料遷移應該是儘量不影響線上業務正常讀寫訪問、支援任意大小的Key、優異的遷移效能、保證遷移前後的資料一致性,但是Codis在2016年末的時候資料遷移功能差強人意。首先是遷移速度慢,其次是隻支援同步遷移,較大的Key遷移會阻塞Redis主執行緒,影響線上業務正常讀寫,最後是不支援超大Key遷移(>512M)。雖然各種最佳實踐不斷強調需要避免大Key,的確大Key可能會是系統潛在的一個風險點(如大key刪除、遷移、熱點訪問等),但是在不少業務場景下,業務層是無法高效、簡單的完成分Key的,Redis本身也在不斷的優化,降低大Key風險,比如4.0版本提供了非同步刪除Key功能,倘若儲存層能快速完成大Key遷移,這不僅會大大簡化業務端的複雜度,更會提升Redis穩定性、可用性,但是記憶體型儲存系統在大Key遷移的上覆雜度比非記憶體型儲存系統多一個數量級,這也是為什麼Redis到現在還未實現大Key遷移和非同步遷移的功能。
大Key若能拆分成小Key分批次非同步遷移、並在遷移過程中該Key可讀、不可寫,只要遷移速度夠快,這對業務而言是可以接受的,在2016年末的時候我跟Codis核心作者spinlock交流了大key遷移的想法,令人驚喜膜拜的是,他在農曆春節期間就快馬加鞭實現了非同步遷移原型,在這過程中我們協助其測試、反饋BUG和瓶頸、不斷改進、優化遷移效能,最終非同步遷移不僅支援任意大小Key遷移,而且遷移效能相比同步遷移要快5-6倍,我們也是第一個在線上大規模應用實踐Redis非同步遷移的,更令人可喜的是此非同步遷移方案擊敗了Redis作者antirez之前計劃的多執行緒方案,將正式合入Redis 4.2版本。
在介紹非同步遷移方案實現前,先介紹下Codis是如何保證過程中資料一致性和為什麼同步遷移慢。如何保證遷移過程中各Proxy讀取到的資料一致性?Codis主要遷移流程如圖五所示,其採用了多階段狀態機實現,類似分散式事務中的多階段提交協議,其核心流程如下。
在運維管理系統上,提交遷移指令,Dashboard更新ZooKeeper上雜湊槽狀態為待遷移,即返回(時序圖1,2,3步驟)。
Dashboard非同步定時檢查ZooKeeper上是否有待遷移狀態的雜湊槽,若有則首先進入準備中狀態,Dashboard將此狀態同時分發到所有Proxy,若有異常Proxy應答失敗,則無法進入遷移,狀態回退(時序圖4,5,6,7步驟)。
若所有Proxy應答成功,則進入準備就緒狀態,Dashboard將此狀態同時分發到所有Proxy,Proxy收到此狀態後,訪問此雜湊槽中的Key的業務請求將被阻塞等待,若有Proxy應答失敗,則會立刻回退到上個狀態(時序圖8,9,10步驟)。
若所有Proxy應答成功,則進入遷移狀態,Dashboard將此狀態同時分發到所有Proxy,Proxy收到此狀態後,不再阻塞對遷移雜湊槽中的Key訪問,若業務請求Key屬於待遷移雜湊,首先會從遷移源Redis中讀取資料,寫到目的端Redis中去,然後再獲取/修改資料返回,這是其中一種遷移方式,被動遷移,Dashboard也會發起主動遷移,直至資料遷移結束(時序圖11,12,13,14,15步驟)。
通過多階段的狀態提交和細粒度、ms級別的鎖,Codis優雅的解決了遷移過程中的資料一致性。
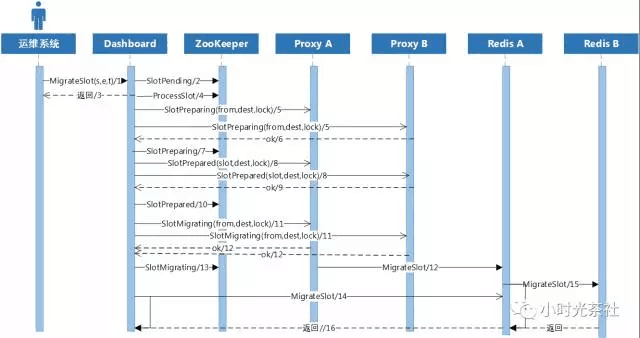
圖六 Codis遷移狀態流程圖

圖七 Redis同步遷移流程
再看為什麼同步遷移慢,圖七是遷移一個1000萬元素的ZSET耗時分析,當Client發起遷移指令後,源端將整個ZSET序列化成payload花費了10.27s,通過網路傳輸給目的端Redis花費1.65s,目的端Redis收到資料後,將其反序列化成記憶體中的資料結構,花費了36.65s,最後源端Redis刪除遷移完成的Key又花費了6.11s,而整個遷移過程中,源端Redis是完全阻塞的,不能提供任何讀寫訪問。因此,非同步遷移方案若要提升遷移效能,必須在以上四個流程上面做優化。
非同步遷移的流程如圖八所示,面對同步遷移的四個核心點,非同步遷移的解決方案如下:
拆分rdbSave(encoding)過程,解決同步序列化開銷。對於大key,不再使用rdbSave對資料進行encoding,而是通過指令拆解, redis中的資料結構(list,set,hash,zset)都可以等價的拆分成若干個新增指令,比如含有1000萬元素的zset,可以拆分成10萬個zadd指令,每個zadd指令新增100個數據
拆分Restore(network)過程,解決同步IO開銷。非同步IO實現,傳送資料不再阻塞。
拆分rdbLoad(decoding)過程,解決反序列號開銷。因源端傳送過來的資料不再是rdb二進位制資料,目的端redis無需再使用rdbLoad,只需將收到的新增指令資料直接更新到對應的記憶體資料結構即可,同時使用了一些trick,比如記憶體預分配,避免頻繁申請記憶體,double轉換成long long,提高遷移效能等。
非同步刪除Key,解決同步刪除Key耗時問題。通過額外的工作執行緒非同步刪除key,不再阻塞redis主執行緒。
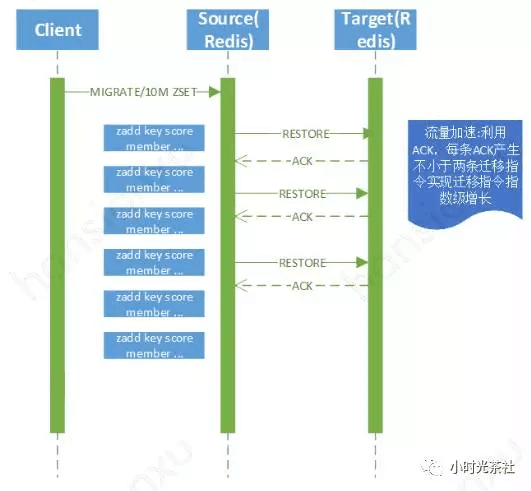
圖八 Redis非同步遷移流程
1000萬的ZSET,同步遷移需要54.87s,而非同步遷移只需要8.3s,在不阻塞線上業務的前提下,效能提升6倍多,以我們生產環境某全球9000w排行榜為例,之前單機主備版載入到記憶體都需要20分鐘,而用非同步跨機器遷移只需要180s左右, 更詳細的遷移介紹可參看附錄spinlock的Codis新版本特性介紹。
六、高可用
各元件中跟使用者請求相關性很強的元件分別是Proxy、Redis、元資料儲存(ZooKeeper),相關性較弱的是Dashboard。
Proxy:多機多IDC部署,排程服務會根據IDC ID,自動打散相同proxy,儘量保證同一叢集proxy部署在不同IDC,通過L5和CMLB進行容災。
Redis:基於Redis Sentinel進行主備自動化切換。
ZooKeeper:高可用分散式協調服務,一半以上節點存活即可提供服務,同時只有在Proxy啟動時和執行過程中發生資料遷移才會依賴ZooKeeper,絕大部分正常請求不受ZooKeeper 叢集狀態影響。
Dashboard: 負責協調叢集狀態變更及一致性,目前在設計上是個單點,但是隻有在就叢集執行過程中發生資料遷移才會依賴它,因此是弱相關性, 後續還可以優化成多節點部署,通過ZooKeeper的分散式鎖來保證只有一個節點能提供服務,當提供服務的節點故障時,通過一系列流程(如需通知Proxy,Dashboard變更等)實現Dashboard自動化故障切換。
重點介紹redis的主備自動切換流程,常見的Master-Slave儲存系統自動切換方案一般有如下三種:
基於ZooKeeper來做主備自動切換,如公司內部的TDSQL,在Mysql主備節點上部署Agent,在ZooKeeper叢集上註冊臨時節點,當主機宕機時,Scheduler在檢測到臨時節點消失超過閥值後發起容災流程。
基於相互獨立的探測Agent實現,如MIG的DCache,IEG的TRedis。IEG TRedis將主備自動切換流程拆分成故障決策模組(探測Redis存活)、故障同步模組、故障監控模組(double check)、故障切換表同步模組(將待切換的例項放入佇列)、故障核心模組( 切換路由)。
基於Quorum的分散式探測Agent,如Redis的Sentinel,Sentinel在新浪微博等公司已經進行了較大規模應用,Codis也是基於此實現主備自動切換,我們在此基礎上增加了告警和當網路出現分割槽時,增加了一個降級操作,避免腦裂,其詳細流程圖八所示。

圖九 Redis主備自動切換流程
圖九流程簡要分析如下:
圖中三個Sentinel部署在不同的可用區,實際現網我們是部署了五個,覆蓋各大運營商IDC等,各Sentinel會定時向master/slave傳送ping等請求探測master/slave存活,並通過gossip協議相互交流資訊,同時各Proxy實時監聽Sentinel的狀態訊息。(圖八1,2流程)
當master出現異常,Sentinel在一定時間(可配置,如2min,避免網路抖動,誤切)內都持續無法訪問Master時,Sentinel就會認為此節點為主觀故障(S_DOWN),Sentinel會彼此通過gossip協議相互交換資訊,當一半以上(可配置)的sentinel認為此master都故障後,此節點會被判斷為客觀故障(O_DOWN),各Sentinel會選舉出一個Leader來執行主備切換,Leader首先從各備機中選擇一個最佳節點,演算法是首選過濾掉與master斷線時間超過閥值的slave,其次優先選擇slave_priority較小的,若priority一樣,則選擇replication offset最大的,若offset也一致,則按字典順序排序選擇最小的runid.選擇出最佳候選master後,Leader會將其提升為master,同時向訂閱者發出+switch-master 事件,通過tnm2/uwork發出L0告警通知開發運維,然後更改其他備機主從關係,從新主機同步資料(圖八3,4,5流程)。
各個Proxy收到Sentinel的+switch-master event後,會遍歷所有sentinel查詢故障組最新master,當一半以上的sentinel返回了故障組新的master,Proxy則會切換路由,路由到組的請求,將發到新的master,主備自動切換完成。(圖八6流程)
但是在極端情況下若網路出現分割槽,業務服務、個別Proxy跟Redis Master在同一個可用區,則會出現腦裂,為了避免此種情況,部署在Redis機器上的Agent會定時持續檢測與ZooKeeper連線是否通暢,若連線不上則會向Redis傳送降級指令,不可讀寫(圖八7流程)。
七、運營實踐
多維度監控
Proxy/Dashboard/Redis機器上的Agent定時採集proxy、redis的qps、connection、memory_used等10幾個指標,上報到米格監控系統,針對核心監控指標配置閥值和波動告警。監控系統在線上數次捕捉到叢集異常(如連線數超過閥值、某redis例項無備機等),及時發出有效告警,提前發現問題、解決問題。同時,也不連VPN的情況下也可以便捷地通過手機快速檢視監控曲線、定位問題等,大大提高工作效率。
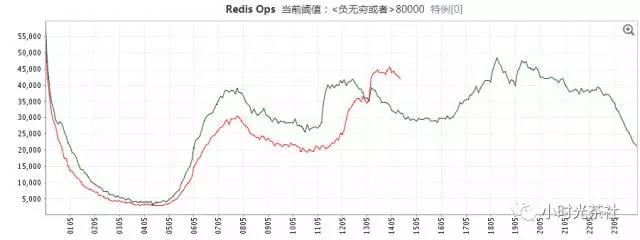
圖十 Redis Ops曲線

圖十一 master/slave offset差異曲線
2 . 低負載優化
叢集縮容和相同業務複用同叢集
儲存機多例項部署,現在預設8個例項
通過Agent順序觸發個例項aof rewrite和rdb save,避免多個例項同時fork,從而提高儲存機記憶體使用率至最高80%
Proxy機器多例項部署(進行中)
3 .多租戶
小業務通過在key字首增加業務標識,複用相同叢集
大業務使用獨立叢集,獨立機器
4.資料安全及備份
訪問所有Redis例項都需要鑑權
Proxy層可統計彙總所有寫請求指令
預設開啟AOF日誌
定時上報Redis AOF、RDB檔案到HDFS叢集
八、總結
基於Codis為核心的Redis服務平臺高效解決了SNG大量業務的痛點(不限制Key大小,原生的Redis核心,高效能),提高了開發效率,助力產品更快發展,但是因人力有限(半個開發投入,在業務專案人力緊張的時候,零投入),還有若干待完善的地方,如不支援冷熱分離等。 在千呼萬喚中,目前公司內的儲存組自研的CKV+(基於共享記憶體實現Redis各類資料結構)的單機主從版也終於上線,叢集版也在緊鑼密鼓的開發中,CKV+較好的解決了Redis記憶體使用率、跨IDC部署、資料備份及同步機制的一些不足之處,後續業務也將有更多的選擇!最後感謝antirez,spinlock的無私貢獻!
九、參考資料
Redis Documentation
Github Codis
Github Redis
Codis新版本特性介紹(spinlock)