
推薦系統三十六式:矩陣分解 學習筆記
-
作者:jliang
1.重點歸納
1)評分預測問題只是很典型,其實並不大眾,畢竟在實際的應用中,評分資料很難收集到;與之相對的另一類問題是行為預測才是平民級推薦問題。在真正的推薦系統的實際應用中,評分預測實際上場景很少,而且資料很少,相比預測評分,預測“使用者會對物品幹出什麼事”會更加有效。
2)矩陣分解
(1)矩陣分解常用的方法是SVD(奇異值分解)把使用者和物品都對映到一個k維空間中,分解後的矩陣實質上就是得到了每個使用者和每個物品的隱因子向量,拿著物品和使用者兩個向量計算點積就是推薦分數了。
(2)為了解決不同使用者的評分標準不一樣,以及某些物品存在一些鐵粉這樣的問題,引入了偏置資訊,包括:全域性評分、物品評分偏置、使用者評分偏置:![]()
(3)為了解決使用者顯式反饋比較少,引入使用者隱式反饋以及使用者屬性等資訊,SVD中結合使用者隱式反饋行為和屬性的模型叫SVD++。![]()
(4)考慮時間因素
- 對評分按照時間加權,讓久遠的評分更趨近平均值
- 對評分時間劃分區間,不同時間區間內分別學習隱因子向量,使用時按照區間使用對應的因因子向量來計算
- 對特殊的期間,如節日、週末等訓練對應的隱因子向量
3)矩陣分解要將使用者物品評分矩陣分解成兩個小矩陣,一個代表使用者偏好的使用者隱因子向量組成,另一個矩陣代表物品語義主題的隱因子向量組成,兩者是一一對應的,使用者的興趣就表現在物品的語義維度上
(1)矩陣分解時經常使用交替最小二乘進行求解,先固定其中一個矩陣,利用線性代數對另外一個矩陣進行求解;然後再反過來另一個矩陣,再對第一個矩陣求解;反覆求解直至誤差很小。
(2)在對隱式反饋進行預測時,只有明確的某類已經幹過的正類(One-Class問題),負類資料靠取樣獲取(隨機均勻取樣或按照熱門程度取樣),使用加權交替最小二乘(Weighted-ALS)進行求解
- 如果使用者對物品無隱式反饋則認為評分是0
- 如果使用者對物品有至少一次隱式反饋則認為評分為1,次數作為該評分的置信度
- 目標函式:
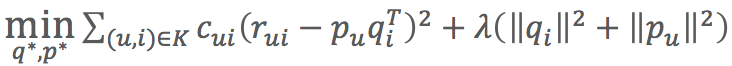
- 相對原來的目標函式多了cui引數
- cui=1+αC,超引數α預設值為40可以得到差不多的效果,C就是次數
(3)讓使用者和物品的隱因子向量兩兩相乘,計算點積就可以得到所有推薦的結果。但是在資料量巨大時實際複雜度很高,一般採取以下兩種方式來解決
- 利用一些專門設計的資料結構儲存所有物品的隱因子向量,從而實現通過一個使用者向量可以反饋最相似的K個物品。
- 拿物品的隱因子向量做聚類,海量的物品會減少為少量的聚類。然後再逐一計算使用者和每個聚類中心的推薦分數,給使用者推薦物品就變成了給使用者推薦聚類。
4)貝葉斯個性化排序(Bayesian Personalized Ranking,BPR)直接預測物品兩兩之間的相對順序(pair-wise問題)
(1)BPR構造樣本
BPR提出要關心物品之間對於使用者的相對順序,構造的樣本是:使用者、物品1、物品2、兩個物品相對順序
- 如果物品1消費過的,而物品不是,那麼相對順序取值1,是正樣本
- 如果物品1和物品2剛好相反,則是負樣本
- 樣本中不包含其他情況:物品1和物品2都是消費過的,或者都是沒消費過的
(2)最大化交叉熵就是BPR目標函式,最大化目標函式就能得到分解後的矩陣引數。
(3)訓練方法
BPR使用了一個介於批量下降法和隨機梯度下降法的訓練方法,結合重複抽樣的梯度下降:
- 從全量樣本中有放回地隨機一部分樣本
- 用這部分樣本,採用隨機梯度下降優化目標函式,更新模型引數
- 重複步驟,直到滿足停止條件

2.那些在Netflix Prize中大放異彩的推薦演算法
1)近鄰模型的問題
(1)物品之間存在相關性,資訊量並不隨著向量維度增加而線性增加。
(2)矩陣元素係數,計算結果不穩定,增減一個向量維度,導致近鄰結果差異很大的情況存在。
矩陣分解可以解決這兩個問題。矩陣分解就是把原來的大矩陣,近似分解成兩個小矩陣的乘積,在實際推薦計算時直接使用兩個小矩陣。
2)基礎的SVD演算法
(1)矩陣分解常用的方法是SVD(奇異值分解),由於向量是稀疏的,無法直接進行奇異值分解,在推薦演算法中使用的並不是正統的奇異值分解,而是一個偽奇異值分解。
(2)矩陣分解就是把使用者和物品都對映到一個k維空間中,這個k維空間不是我們直接看到的,也不具有很好的解釋性,每個維度也沒有名字,所以常常稱為隱因子,代表隱藏在直觀的矩陣資料下面。
(3)損失函式:![]()
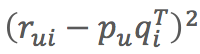 控制模型的偏差。用分解後的矩陣預測分數,要和實際的使用者評分之間誤差越小越好。
控制模型的偏差。用分解後的矩陣預測分數,要和實際的使用者評分之間誤差越小越好。 控制模型的方差。得到的隱因子向量要越簡單越好,以控制模型的方差。
控制模型的方差。得到的隱因子向量要越簡單越好,以控制模型的方差。
(4)得到分解後的矩陣實質上就是得到了每個使用者和每個物品的隱因子向量,拿著物品和使用者兩個向量計算點積就是推薦分數了。
3)SVD演算法增加偏置資訊
(1)原因:有一些使用者給出偏高的評分(比如標準寬鬆的使用者),有些物品也會收到偏高的評分(如目標觀眾為鐵粉的電影),甚至有可能整個平臺的全域性評分就偏高。
(2)增加偏置:一個使用者給一個物品的評分由四部分相加
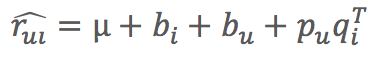
- μ:全域性平均分
- bi:物品評分偏置,即:物品的評分-全域性評分
- bu:使用者評分偏置,即:使用者平均評分-全域性評分
 :使用者和物品之間的興趣偏好
:使用者和物品之間的興趣偏好
(3)損失函式:![]()
- 與基本的SVD相比,增加了兩個引數要學習:使用者偏置和物品偏置
4)SVD演算法增加歷史行為
(1)原因:使用者評分比較少,顯示反饋比隱式反饋少,使用隱式反饋彌補這個問題;另外再考慮一些使用者的個人屬性(如性別等)加入模型來彌補冷啟動的不足。SVD中結合使用者隱式反饋行為和屬性的模型叫SVD++。
(2)隱式反饋加入
- 除了加速評分矩陣中的物品有一個隱因子向量外,使用者有過行為的物品集合也都有一個隱因子向量,維度時一樣的。
- 使用者操作過的物品隱因子向量加起來,用來表達使用者的興趣偏好。
(3)使用者屬性加入
- 全都轉成0-1型的特徵後,對每個特徵也假設都存在一個同樣維度的隱因子向量。
- 一個使用者的所有屬性對應的隱因子向量相加,也代表了他的一些偏好。
(4)使用者向量:![]()
- 與之前的SVD相比,只是增加了兩個學習引數:x和y。一個是隱式反饋的物品向量,另外一個使用者屬性的向量。
5)考慮時間因素
(1)對評分按照時間加權,讓久遠的評分更趨近平均值
(2)對評分時間劃分區間,不同時間區間內分別學習隱因子向量,使用時按照區間使用對應的因因子向量來計算
(3)對特殊的期間,如節日、週末等訓練對應的隱因子向量
3.Facebook是怎麼為十億人互相推薦好友的
1)矩陣分解要將使用者物品評分矩陣分解成兩個小矩陣,一個代表使用者偏好的使用者隱因子向量組成,另一個矩陣代表物品語義主題的隱因子向量組成,兩者是一一對應的,使用者的興趣就表現在物品的語義維度上。兩個小矩陣相乘得到的矩陣的維度與使用者物品評分矩陣一模一樣。
(1)這兩個矩陣的特點:
- 每個使用者對應一個k維向量,每個物品也對應一個k維向量
- 兩個矩陣相乘後,就得到了任何一個使用者對任何一個物品的預測評分
(2)目標函式的優化方法常用有兩個:隨機梯度下降(SGD)和交替最小二乘法(ALS)。實際應用中交替最小二乘法更常用一些。
2)交替最小二乘原理
(1)我們的任務是找到兩個矩陣P和Q,讓它們相乘後約等於原矩陣R:![]()
(2)最小二乘的步驟:
- 初始化隨機矩陣Q裡面的所有元素
- 把Q矩陣當做已知,直接用線性代數的方法求得矩陣P
- 得到矩陣P後,把P當做已知,求解矩陣Q
- 上面兩個步驟交替進行,一直到誤差可以接受為止
(3)ALS好處
- 在假設已知其中一個矩陣求解另一個時,要優化的引數很容易並行化
- 在不那麼稀疏的資料集合上,ALS通常比隨機梯度下降更快
3)隱式反饋
(1)矩陣分解演算法是為解決評分預測問題而生的,然而實際應用中使用者的隱式反饋資料更多。
One-Class問題:如果把預測使用者行為看成二分類問題,猜使用者會不會做某件事實際上收集到的資料只有明確的一類(使用者幹了某事),而使用者“不幹”某件事的資料沒有明確表達。
(2)交替最小二乘法改進版:加權交替最小二乘(Weighted-ALS)
行為的次數是對行為的置信度反應,也就是所謂的加權。
(3)加權交替最小二乘法對待隱式反饋的方式
- 如果使用者對物品無隱式反饋則認為評分是0
- 如果使用者對物品有至少一次隱式反饋則認為評分為1,次數作為該評分的置信度
- 目標函式:
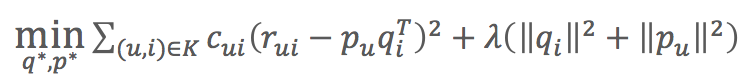
- 相對原來的目標函式多了cui引數
- cui=1+αC,超引數α預設值為40可以得到差不多的效果,C就是次數
(4)取值為0的資料非常多,不能一股腦使用所有缺失值(評分為0的資料)作為負類,矩陣分解的初心是要填充這些值。解決這個問題的方法是負樣本取樣,挑一部分缺失值作為負類樣本。挑選方法:
- 隨機均勻取樣和正類別一樣多(不是很靠譜)
- 按照物品的熱門程度取樣(在實踐中經過了檢驗),一個越熱門的物品,使用者越可能知道它的存在,這時候還沒有反饋,可能它才是真正的負樣本。
4)推薦計算
讓使用者和物品的隱因子向量兩兩相乘,計算點積就可以得到所有推薦的結果。但是在資料量巨大時實際複雜度很高,Fackbook提出兩個辦法來得到真正的推薦結果:
- 利用一些專門設計的資料結構儲存所有物品的隱因子向量,從而實現通過一個使用者向量可以反饋最相似的K個物品。
- Facebook開源的Faiss,類似開源實現還有Annoy、KGraph、NMSLIB。
- 如果需要動態增加新的物品向量到索引中,推薦使用Faiss,否則推薦使用KGraph或NMSLIB
- 拿物品的隱因子向量做聚類,海量的物品會減少為少量的聚類。然後再逐一計算使用者和每個聚類中心的推薦分數,給使用者推薦物品就變成了給使用者推薦聚類。
4.如果關注排序效果,那麼這個模型可以幫到你
1)矩陣分解本質上是在預測使用者對一個物品的偏好程度。針對單個使用者對單個物品的偏好程度進行預測,得到結果後再排序的問題叫point-wise。直接預測物品兩兩之間的相對順序問題叫pair-wise。
(1)point-wise模型的問題:只能收集到正樣本,沒有負樣本,於是認為缺失值就是負樣本,再以預測誤差為評判標準去逼近這些樣本。
(2)更直接的推薦模型是能夠較好地為使用者排列出更好的物品相對順序,而非精確評分。
2)貝葉斯個性化排序(Bayesian Personalized Ranking,BPR)
(1)評價模型預測精準程度可以使用AUC,ACU這個值在數學上等價於:模型把關心的那一類樣本排在其他樣本前面的概率。最大是1,0.5就是隨機排序,0就是全部排錯。
(2)AUC計算
- 用模型給樣本計算推薦分數。樣本都是使用者和物品的一對一,同時還包含了有無反饋的標識
- 得到打過分的樣本,每條樣本保留兩個資訊:分數和是否消費過(1為消費過的正樣本,0為沒有消費過的負樣本)
- 按照分數對樣本重新排序,降序排序
- 給每一個樣本賦一個排序值,第一位r1=n,第二位r2=n-1;如果幾個樣本分數一樣,需要將其排序值調整為他們的平均值
- 按照下面公式計算得到的AUC值

- 正樣本M個,其他樣本N個,M×N為兩類樣本相對排序總的組合可能性
- 分子:第一名排序值r1,它在排序上不但比過了所有負樣本,而且比過了自己以外的正樣本。
3)BPR做法
(1)樣本構造方法
(2)模型目標函式
(3)模型學習框架
4)BPR構造樣本
(1)BPR提出要關心物品之間對於使用者的相對順序,構造的樣本是:使用者、物品1、物品2、兩個物品相對順序
(2)兩個物品的相對順序
- 如果物品1消費過的,而物品不是,那麼相對順序取值1,是正樣本
- 如果物品1和物品2剛好相反,則是負樣本
- 樣本中不包含其他情況:物品1和物品2都是消費過的,或者都是沒消費過的
5)BPR目標函式
(1)物品1和物品2的似然概率是最大化交叉熵:![]()
Xu12表示使用者u,物品1和物品2的矩陣分解預測分數差,然後再用sigmoid把分數壓縮到0-1之間。
(2)通常還要加入L2正則項,正則項其實認為模型引數還有個先驗概率,所以BPR名字中的貝葉斯的由來。BPR認為模型的先驗概率符合正態分佈。
(3)目標函式:![]()
- 最大化目標函式就能得到分解後的矩陣引數,其中θ是分解後的矩陣引數
- 這個目標函式化簡和變形後就和AUC當初目標函式非常相似了,所以BPR模型作者宣稱該模型是為AUC而生的。
6)訓練方法
(1)BPR使用了一個介於批量下降法和隨機梯度下降法的訓練方法,結合重複抽樣的梯度下降:
- 從全量樣本中有放回地隨機一部分樣本
- 用這部分樣本,採用隨機梯度下降優化目標函式,更新模型引數
- 重複步驟,直到滿足停止條件