
46.Scrapy框架結構
Scrapy的介紹:
Scrapy是基於Twisted的非同步處理框架,是純python語言實現的爬蟲框架,特點是架構清晰,模組間耦合度低、擴充套件性強較為靈活。
框架結構如圖所示:
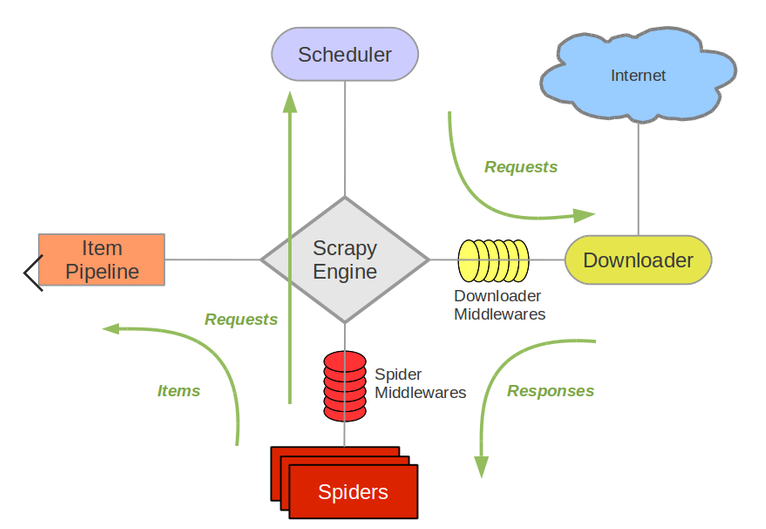
Engine:引擎,處理整個系統的資料流處理、觸發事務,是整個框架的核心。
Item:專案,定義爬蟲結果的資料結構,爬去的資料被賦值為該item物件。
Scheduler:排程器,接受引擎發過來的請求並將其加入佇列中,在引擎再次請求時將請求提供給引擎。
Downloader:下載器,下載網頁內容,並將內容返還給蜘蛛。
Spiders:蜘蛛,定義爬取的邏輯和網頁的解析規則,主要負責解析響應並生成提取結果和新的請求。
Item Pipline:專案管道,負責處理由蜘蛛從網頁抽取的專案,主要任務是清洗、驗證和儲存資料。
Downloader Middlerwares:下載中介軟體,位於引擎和下載器之間的鉤子框架,主要處理引擎與下載器之間的請求及響應。
Spider Middlewares:蜘蛛中介軟體,位於引擎和蜘蛛之間的鉤子框架,主要處理蜘蛛輸入的響應和輸出的結果及新的請求。
---恢復內容結束---
相關推薦
46.Scrapy框架結構
Scrapy的介紹:Scrapy是基於Twisted的非同步處理框架,是純python語言實現的爬蟲框架,特點是架構清晰,模組間耦合度低、擴充套件性強較為靈活。框架結構如圖所示: Engine:引擎,處理整個系統的資料流處理、觸發事務,是整個框架的核心。
Scrapy基礎 第三節:Scrapy框架結構和元件介紹
前置知識: 掌握Python的基礎知識 對爬蟲基礎有一定了解 說明: 執行環境 Win10,Python3 64位 目錄: 1 Scrapy框架組成結構 2 Scapry資料流程 Scrap
Python爬蟲:Scrapy框架基礎框架結構及騰訊爬取
Scrapy終端是一個互動終端,我們可以在未啟動spider的情況下嘗試及除錯程式碼,也可以用來測試XPath或CSS表示式,檢視他們的工作方式,方便我們爬取的網頁中提取的資料。 如果安裝了 IPython ,Scrapy終端將使用 IPython (替代標準Python終端)。 IPytho
python Scrapy框架1—框架流程、結構和一個簡單的例子
python爬蟲學習_Scrapy框架1—框架流程、結構和一個簡單的例子 框架圖 Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,訊號、資料傳遞等。 Scheduler(排程器)
scrapy框架設置代理
ase param his utf-8 httpproxy down json eth head 網易音樂在單ip請求下經常會遇到網頁返回碼503的情況經查詢,503為單個ip請求流量超限,猜測是網易音樂的一種反扒方式因原音樂下載程序采用scrapy框架,所以需要在scra
初次接觸scrapy框架
self 文件夾 內容 bsp mil 分享 response 記事本 寫入 初次接觸這個框架,先訂個小目標,抓取QQ首頁,然後存入記事本。 安裝框架(http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.htm
Python爬蟲從入門到放棄(十一)之 Scrapy框架整體的一個了解
object 定義 roc encoding eth obi pipe pos 等等 這裏是通過爬取伯樂在線的全部文章為例子,讓自己先對scrapy進行一個整理的理解 該例子中的詳細代碼會放到我的github地址:https://github.com/pythonsite/
Python爬蟲從入門到放棄(十三)之 Scrapy框架的命令行詳解
directory xpath idf 成了 spider i386 名稱 4.2 不同的 這篇文章主要是對的scrapy命令行使用的一個介紹 創建爬蟲項目 scrapy startproject 項目名例子如下: localhost:spider zhaofan$ sc
Spring MVC 框架結構介紹(二)
指定 let url 16px () isp -s 一個 ping Spring MVC框架結構 Spring MVC是圍繞DispatcherServlet設計的,DispatcherServlet向處理程序分發各種請求。處理程序[email prot
第三百三十三節,web爬蟲講解2—Scrapy框架爬蟲—Scrapy模擬瀏覽器登錄—獲取Scrapy框架Cookies
pid 設置 ade form 需要 span coo decode firefox 第三百三十三節,web爬蟲講解2—Scrapy框架爬蟲—Scrapy模擬瀏覽器登錄 模擬瀏覽器登錄 start_requests()方法,可以返回一個請求給爬蟲的起始網站,這個返回的請求相
爬蟲——Scrapy框架案例一:手機APP抓包
debug domain hone targe allow topic document more ebs 以爬取鬥魚直播上的信息為例: URL地址:http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&of
爬蟲——Scrapy框架案例二:陽光問政平臺
web url地址 blog rem idt xpath disable ora ole 陽光熱線問政平臺 URL地址:http://wz.sun0769.com/index.php/question/questionType?type=4&page= 爬取字段:帖
mac os安裝scrapy框架
true ins 是否 bre 顯示 light cnblogs class 只需要 因為Mac 自帶了python 2.7 所以只需要安裝pip包管理工具安裝scrapy就可以了 sudo easy_install pip 然後 pip install Scrap
安裝scrapy框架
pat 接口 rip path 2.7 win nload 令行 easy 前提安裝好python、setuptools。 1.安裝Python 安裝完了記得配置環境,將python目錄和python目錄下的Scripts目錄添加到系統環境變量的Path裏。在
用scrapy框架爬取映客直播用戶頭像
xpath print main back int open for pri nbsp 1. 創建項目 scrapy startproject yingke cd yingke 2. 創建爬蟲 scrapy genspider live 3. 分析http://www.i
創建框架結構的頁面
細節 一個 height logs 不能 根據 樣式 展示 使用 框架指的是一種布局 1.創建窗口框架頁面:有的網頁,像論壇,就左側是導航欄,右側是論壇主體,單擊左側導航欄,則在右側顯示鏈接頁面。這個布局是將瀏覽器分為左右兩部分。 創建窗口框架的<frames
Python3.6下scrapy框架的安裝
twisted 方法安裝 get ont 下載地址 .whl files link 解決問題 首先考慮使用最簡單的方法安裝 pip install scrapy 命令安裝,提示 Failed building wheel for Twisted Microsof
初識 scrapy 框架 - 安裝
pac twisted pin 離線 con generate val images mark 前面豆子學習了基本的urllib的模塊,通過這個模塊可以寫一些簡單的爬蟲文件。如果要處理大中型的爬蟲項目,urllib就顯得比較low了,這個時候可以使用scrapy框架來實現,
jQuery源碼逐行分析學習01(jQuery的框架結構簡化)
col 定義 源碼 來看 三方 spa 技術博客 功能 編寫 最近在學習jQuery源碼,在此,特別做一個分享,把所涉及的內容都記錄下來,其中有不妥之處還望大家指出,我會及時改正。望各位大神不吝賜教!同時,這也是我的第一篇前端技術博客,對博客編寫還不是很熟悉,美化工作可能不
滲透測試框架結構
操作系統 acl post ola pytho nom sybase for ase 一、滲透測試的目標分類 1、主機操作系統,Windows、Solaris、AIX、Linux、SCO、SGI等操作系統本身進行滲透測試 2、數據庫系統,MS-SQL、O