
高可用服務設計概述[1]
1 負載均衡與反向代理
當我們的應用單例項不能支撐使用者請求時,就需要擴容,從一天伺服器擴容到兩臺、幾十臺、幾百臺。然而使用者訪問時是通過如http://www.jd.com的方式訪問,在請求時,瀏覽器首先會查詢DNS伺服器獲取對應的IP,然後通過此IP訪問對應的服務。
對於負載均衡需要關心的幾個方面如下:
- 上游伺服器配置:使用upstream server配置上游伺服器。
- 負載均衡演算法:配置多個上游伺服器時的負載均衡機制。
- 失敗重試機制:配置當超時或上游伺服器不存活時,是否需要重試其他上游伺服器。
- 伺服器心跳檢查:上游伺服器的健康檢查/心跳檢查。
Nginx提供的負載均衡機制可以實現伺服器的負載均衡、故障轉移、失敗重試、容錯、健康檢查等,當某些上游伺服器出現問題時可以將請求轉到其他上游伺服器以保障高可用,並通過OpenResty實現更智慧的負載均衡,如將熱點與非熱點流量分離、正常流量與爬蟲流量分離等。Nginx負載均衡器本身也是一臺反向代理伺服器,將使用者請求通過Ningx代理到內網中的某臺上遊伺服器處理,反向代理伺服器可以對響應結果進行快取、壓縮等處理以提升效能。
負載均衡演算法
負載均衡演算法用來解決使用者請求到來時如何選擇upstream server進行處理,預設採用的是round-robin(輪詢),同時支援其他幾種演算法。
- round-robin:輪詢,預設負載均衡演算法,即以輪詢的方式將請求轉發到上游伺服器,通過配合weight配置可以實現基於權重的輪詢。
- ip-hash:根據客戶IP進行負載均衡,即相同的IP將負載均衡到同一個upstream server。
- hash key [consistent]:對某一個key進行雜湊或者使用一致性雜湊演算法進行負載均衡。使用Hash演算法那存在的問題是,當新增/刪除一臺伺服器時,將導致很多key被重新負載均衡到不同的伺服器(從而導致後端肯可能出現問題);因此,建議考慮使用一致性hash演算法,這樣當新增/刪除一臺伺服器時,只有少數key將被重新負載均衡到不同的伺服器。
- 雜湊演算法:此處是根據請求uri進行負載均衡,可以使用Nginx變數,因此可以實現複雜的演算法。
失敗重試
當fail_timeout時間內失敗了max_fails次請求,則認為該上游伺服器不可用/不存活,然後將摘掉該上游伺服器,fail_timeout時間後會再次將該伺服器加入到存活上游伺服器列表進行重試。
健康檢查
Nginx對上游伺服器的健康檢查預設採用的是惰性策略,Nginx商業版提供了health_check進行主動健康檢查。也可以整合nginx_upstream_check_module模組進行主動健康檢查,它支援TCP心跳和HTTP心跳來實現健康檢查。
HTTP動態負載均衡
Consul是一款開源的分散式服務註冊與發現系統,通過HTTP API可以使得服務註冊、發現實現起來非常簡單,它支援以下特性:
- 服務註冊:服務註冊者可以通過HTTP API或DNS方式,將服務註冊到Consul。
- 服務發現:服務消費者可以通過HTTP API或DNS方式,從Consul獲取服務的IP和PORT。
- 故障檢測:支援如TCP、HTTP等方式的健康檢查機制,從而當服務有故障時自動摘除。
- K/V儲存:使用K/V儲存實現動態配置中心,其使用HTTP長輪詢方式實現變更觸發和配置更改。
- 多資料中心:支援多資料中心,可以按照資料中心註冊和發現服務,即支援只消費本地機房服務,使用多資料中心叢集還可以避免單資料中心的單點故障。
- Raft演算法:Consul使用Raft演算法實現叢集資料一致性。
2 隔離術
隔離是指將系統或資源分隔開。系統隔離是為了在系統發生故障時能限定傳播範圍和影響範圍,即發生故障後不會出現滾雪球效應,從而保證只有出問題的服務不可用,其他服務還是可用的。資源隔離是通過隔離來減少資源競爭,保障服務間的相互不影響和可用性。
執行緒隔離
執行緒隔離主要是指執行緒池隔離,在實際使用時,我們會把請求分類,然後交給不同的執行緒池處理。當一種業務的請求處理髮生問題時,不會將故障擴散到其他執行緒池,從而保證其他服務可用。
程序隔離
在公司發展初期,一般是先進行從零到一,不會一上來就進行系統拆分,這樣就會開發出一些大而全的系統,系統中的一個模組/功能出現問題,整個系統就不可用了。首先想到的解決方案是通過部署多個例項,通過負載均衡進行路由轉發。但是這種情況無法避免某個模組因為BUG而出現如OOM導致整個系統不可用的風險。因此這種解決方案只能是一個過渡,較好的解決方案是通過將系統拆分為多個子系統來實現物理隔離。通過程序隔離使得某一個子系統出現問題時不會影響到其他子系統。
叢集隔離
隨著系統的發展,單例項服務無法滿足需求,此時需要服務化技術,通過部署多個服務形成服務叢集,以提升系統容量。
隨著呼叫方的增多,當秒殺服務被刷會影響到其他服務的穩定性時,應該考慮為秒殺提供單獨的服務叢集,即為服務分組,這樣當某一個分組出現問題時,不會影響到其他分組,從而實現了故障隔離。
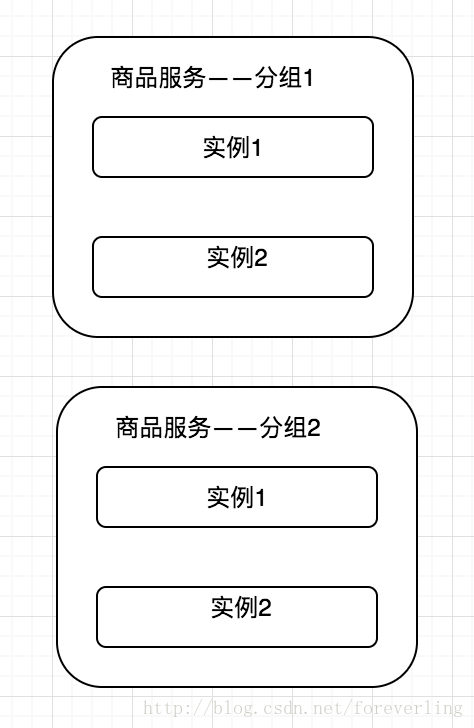
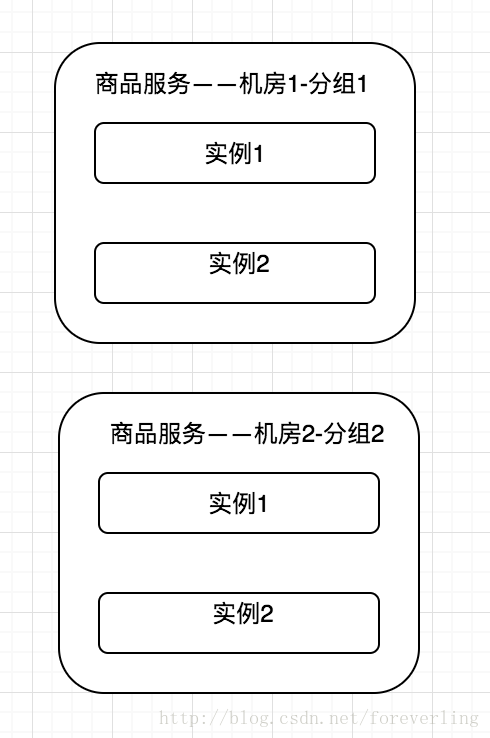
機房隔離
隨著對系統可用性的要求,會進行多機房部署,每個機房的服務都有自己的服務分組,本機房的服務應該只調用本機房的服務,不進行跨機房呼叫。其中,一個機房服務發生問題時,可以通過DNS/負載均衡將請求全部切到另一個機房,或者考慮服務能自動重試其他機房的服務,從而提供系統可用性。
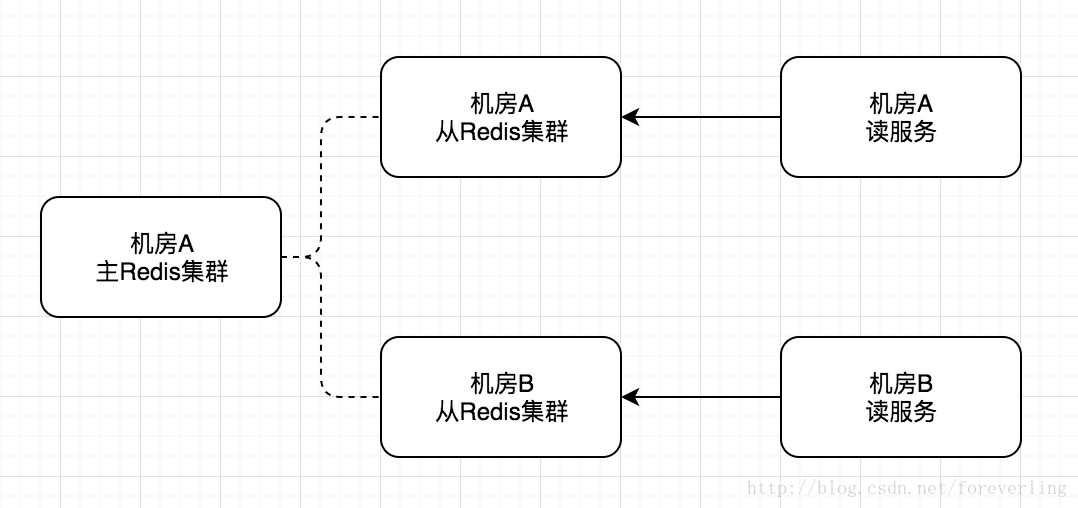
讀寫隔離
通過主從模式將讀和寫叢集隔離,讀服務只從Rdis叢集獲取資料,當主Redis叢集出現問題時,從Redis叢集還是可用的,從而不影響使用者訪問。而當從叢集出現問題時,可以進行其他叢集的重試。
動靜隔離
當用戶訪問如結算頁時,如果JS/CSS等靜態資源也在結算頁系統中,很可能因為訪問量太大導致頻寬被打滿,從而導致服務不可用。因此,應該將動態內容和靜態資源分離,一般應該將靜態資源放在CDN上。
爬蟲隔離
通過負載均衡將爬蟲路由到單獨叢集,從而保證正常流量可用,爬蟲流量儘量可用。
熱點隔離
秒殺、搶購屬於非常合適的熱點例子,對於這種熱點,是能提前知道的,所以可以將秒殺和搶購做成獨立系統或服務進行隔離,從而保證秒殺/搶購流程出現問題時不影響主流程。
資源隔離
如磁碟、CPU、網路等的隔離。
還有一些其他類似的隔離術,如環境隔離(測試環境、預釋出環境/灰度環境、正式環境)、壓測隔離(真實資料、壓測資料隔離)、AB測試(為不同的使用者提供不同版本的服務)、快取隔離(有些系統混用快取,而有些系統會扔大位元組值到Redis,造成Redis慢查詢)、查詢隔離(簡單、批量、複雜查詢條件分別路由到不同的叢集)等。通過隔離,可以將風險降到最低,將效能提升至最優。
使用Hystrix實現隔離
Hystrix是Netflix開源的一款針對分散式系統的延遲和容錯庫,目的是用來隔離分散式服務故障。它提供執行緒隔離和訊號量隔離,以減少不同服務之間資源競爭帶來的相互影響;提供優雅降級機制;提供熔斷機制使得服務可以快速失敗,而不是一直阻塞等待服務響應,從能從中快速恢復。Hystrix通過這些機制來阻止級聯失敗並保證系統彈性、可用。
更多關於降級、限流的內容,請閱讀文章:高可用服務設計概述[2]
參考來源:
[1] 億級流量網站架構核心技術.張開濤著