
死磕Netty原始碼之記憶體分配詳解(二)PoolArena記憶體分配結構分析
前言
在應用層通過設定PooledByteBufAllocator來執行ByteBuf的分配,但是最終的記憶體分配工作被委託給PoolArena。由於Netty通常用於高併發系統所以各個執行緒進行記憶體分配時競爭不可避免,這可能會極大的影響記憶體分配的效率,為了緩解高併發時的執行緒競爭,Netty允許使用者建立多個分配器(Arena)來分離鎖提高記憶體分配效率
PoolArena原始碼分析
PoolArena類是邏輯意義上一塊連續的記憶體,之所以說它是邏輯的因為該類不涉及到具體的記憶體儲存。PoolArena是由多個Chunk組成的大塊記憶體區域,而每個Chunk則由一個或者多個Page組成。PoolArena的內部結構如下圖
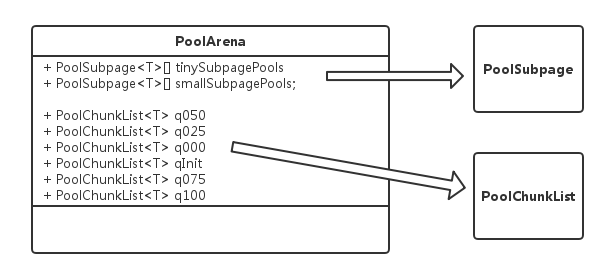
成員變數
以下是PoolArena中一些比較重要的成員變數
// 分配PoolArena的類
final PooledByteBufAllocator parent;
// 以下屬性來自parent
final int pageSize;
final int pageShifts;
final int chunkSize;
private final int maxOrder;
// 陣列預設長度為32(512 >>4)
// Netty認為小於512子節的記憶體為小記憶體即tiny tiny按照16位元組遞增 比如16,32,48
private final PoolSubpage<T>[] tinySubpagePools;
// 陣列預設長度為4 pageShifts-4 構造方法
在PoolArena的構造方法中,主要是對以上成員變數進行初始化操作
protected PoolArena(PooledByteBufAllocator parent, int pageSize, int maxOrder, int pageShifts, int chunkSize, int cacheAlignment) {
// 初始化引數
this.parent = parent;
this.pageSize = pageSize;
this.maxOrder = maxOrder;
this.pageShifts = pageShifts;
this.chunkSize = chunkSize;
directMemoryCacheAlignment = cacheAlignment;
directMemoryCacheAlignmentMask = cacheAlignment - 1;
subpageOverflowMask = ~(pageSize - 1);
// 初始化tinySubpagePools
tinySubpagePools = newSubpagePoolArray(numTinySubpagePools);
for (int i = 0; i < tinySubpagePools.length; i ++) {
tinySubpagePools[i] = newSubpagePoolHead(pageSize);
}
// 初始化smallSubpagePools
numSmallSubpagePools = pageShifts - 9;
smallSubpagePools = newSubpagePoolArray(numSmallSubpagePools);
for (int i = 0; i < smallSubpagePools.length; i ++) {
smallSubpagePools[i] = newSubpagePoolHead(pageSize);
}
// 建立6個不同使用率的PoolChunkList
q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize);
q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize);
q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize);
q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize);
q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize);
qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize);
// 使用連結串列維護PoolChunkList
q100.prevList(q075);
q075.prevList(q050);
q050.prevList(q025);
q025.prevList(q000);
q000.prevList(null);
qInit.prevList(qInit);
List<PoolChunkListMetric> metrics = new ArrayList<PoolChunkListMetric>(6);
metrics.add(qInit);
metrics.add(q000);
metrics.add(q025);
metrics.add(q050);
metrics.add(q075);
metrics.add(q100);
chunkListMetrics = Collections.unmodifiableList(metrics);
}PoolArena中的六個PoolChunkList通過連結串列串聯,結構如下圖所示
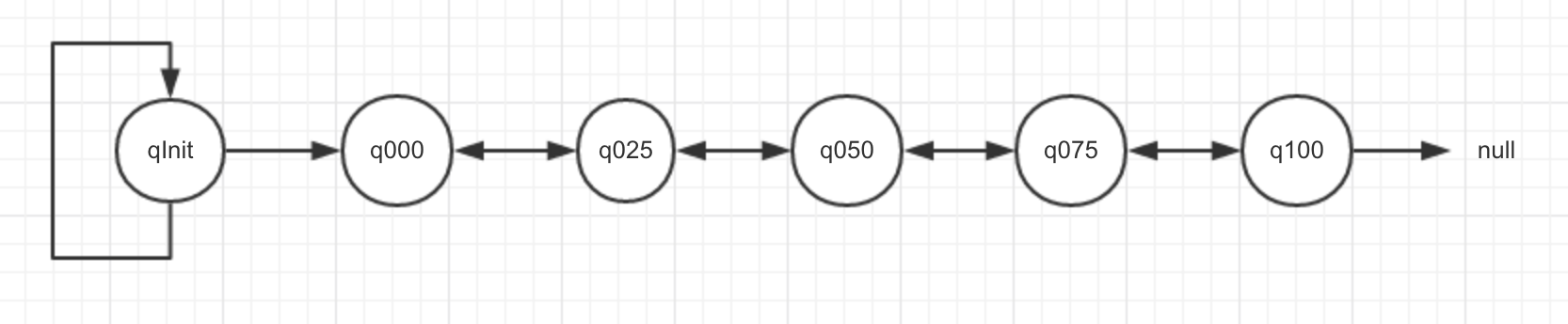
為什麼連結串列是這樣的順序排列的
qInit前置節點為自己且minUsage=Integer.MIN_VALUE,這意味著一個初始分配的chunk在最開始的記憶體分配過程中(記憶體使用率<25%),即使完全釋放也不會被回收會始終保留在記憶體中,q000沒有前置節點,當一個chunk進入到q000列表,如果其記憶體被完全釋放則不再保留在記憶體中,其分配的記憶體被完全回收。並且隨著chunk中page的不斷分配和釋放會導致很多碎片記憶體段,大大增加了之後分配一段連續記憶體的失敗率,針對這種情況可以把記憶體使用量較大的chunk放到PoolChunkList連結串列更後面,這樣就便於記憶體的成功分配記憶體分配
PoolArena的記憶體分配是由allocate()完成的,它的大致流程如下
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
// 1.建立一個純淨的PooledByteBuf物件
PooledByteBuf<T> buf = newByteBuf(maxCapacity);
// 2.對PooledByteBuf進行記憶體分配
allocate(cache, buf, reqCapacity);
return buf;
}PooledByteBuf初始化
protected PooledByteBuf<byte[]> newByteBuf(int maxCapacity) {
return HAS_UNSAFE ? PooledUnsafeHeapByteBuf.newUnsafeInstance(maxCapacity) : PooledHeapByteBuf.newInstance(maxCapacity);
}
static PooledHeapByteBuf newInstance(int maxCapacity) {
// 從RECYCLER獲取PooledHeapByteBuf例項
PooledHeapByteBuf buf = RECYCLER.get();
// 重新設定PooledHeapByteBuf屬性
buf.reuse(maxCapacity);
return buf;
}到目前為止我們建立的PooledHeapByteBuf還只是一個空殼,我們還需要確定這個PooledHeapByteBuf在Chunk的底層儲存所處在的位置。(關於RECYCLER後續的部落格中會詳細介紹)
PooledByteBuf記憶體分配
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 1.將需要分配的記憶體規格化
final int normCapacity = normalizeCapacity(reqCapacity);
// 2.判斷需要申請的記憶體是否小於pageSize
if (isTinyOrSmall(normCapacity)) {
int tableIdx;
PoolSubpage<T>[] table;
// 3.判斷記憶體是否屬於tiny
boolean tiny = isTiny(normCapacity);
if (tiny) {
// 4.嘗試從本地執行緒申請tiny 如果申請成功則直接返回
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
return;
}
// 5.根據需要申請的記憶體 計算出tinyIdx
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
// 6.嘗試從本地執行緒申請small 如果申請成功則直接返回
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
return;
}
// 7.根據需要申請的記憶體 計算出smallIdx
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
final PoolSubpage<T> head = table[tableIdx];
// 8.走到這裡說明嘗試在poolThreadCache中分配失敗
// 開始嘗試借用tinySubpagePools或smallSubpagePools快取中的Page來進行分配
synchronized (head) {
final PoolSubpage<T> s = head.next;
// 9.第一次在此位置申請記憶體的時候 s==head會呼叫allocateNormal方法來分配
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
incTinySmallAllocation(tiny);
return;
}
}
synchronized (this) {
// 10.使用全域性allocateNormal進行分配記憶體
allocateNormal(buf, reqCapacity, normCapacity);
}
incTinySmallAllocation(tiny);
return;
}
// 11.判斷需要申請的記憶體是否小於chunkSize
if (normCapacity <= chunkSize) {
12.嘗試從本地執行緒allocateNormal方法進行記憶體分配
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
return;
}
synchronized (this) {
13.使用全域性allocateNormal進行分配記憶體
allocateNormal(buf, reqCapacity, normCapacity);
++allocationsNormal;
}
} else {
// 14.如果申請記憶體大於chunkSize 直接建立非池化的Chunk來分配 並且該Chunk不會放在記憶體池中重用
allocateHuge(buf, reqCapacity);
}
}記憶體規格化
int normalizeCapacity(int reqCapacity) {
if (reqCapacity < 0) {
throw new IllegalArgumentException("capacity: " + reqCapacity + " (expected: 0+)");
}
// 請求的記憶體大小是否超過了chunkSize
if (reqCapacity >= chunkSize) {
// 如果已超出說明一個該記憶體已經超出了一個chunk能分配的範圍 這種記憶體記憶體池無法分配應由JVM分配 直接返回原始大小
return directMemoryCacheAlignment == 0 ? reqCapacity : alignCapacity(reqCapacity);
}
// 請求大小大於等於512
if (!isTiny(reqCapacity)) {
// 返回一個512的2次冪倍數當做最終的記憶體大小
// 當原始大小是512時返回512 當原始大小在(512,1024]區間返回1024 當在(1024,2048]區間,返回2048等等
int normalizedCapacity = reqCapacity;
normalizedCapacity --;
normalizedCapacity |= normalizedCapacity >>> 1;
normalizedCapacity |= normalizedCapacity >>> 2;
normalizedCapacity |= normalizedCapacity >>> 4;
normalizedCapacity |= normalizedCapacity >>> 8;
normalizedCapacity |= normalizedCapacity >>> 16;
normalizedCapacity ++;
if (normalizedCapacity < 0) {
normalizedCapacity >>>= 1;
}
assert directMemoryCacheAlignment == 0 || (normalizedCapacity & directMemoryCacheAlignmentMask) == 0;
return normalizedCapacity;
}
if (directMemoryCacheAlignment > 0) {
return alignCapacity(reqCapacity);
}
// Tiny且已經是16的整數倍 直接返回
if ((reqCapacity & 15) == 0) {
return reqCapacity;
}
// 請求大小小於512返回一個16的整數倍 這些大小的記憶體塊在記憶體池中叫tiny塊
// 原始大小(0,16]區間返回16 (16,32]區間返回32 (32,48]區間返回48等等
return (reqCapacity & ~15) + 16;
}總結:記憶體池包含兩層分配區:執行緒私有分配區和記憶體池公有分配區。當記憶體被分配給某個執行緒之後在釋放記憶體時釋放的記憶體不會直接返回給公有分配區,而是直接線上程私有分配區中快取,當執行緒頻繁的申請記憶體時會提高分配效率。同時當執行緒申請記憶體的動作不活躍時可能會造成記憶體浪費的情況,這時候記憶體池會對執行緒私有分配區中的情況進行監控,當發現執行緒的分配活動並不活躍時會把執行緒快取的記憶體塊釋放返回給公有區。在整個記憶體分配時可能會出現分配的記憶體過大導致記憶體池無法分配的情況,這時候就需要JVM堆直接分配,所以嚴格的講有三層分配區
分配記憶體時預設先嚐試從PoolThreadCache中分配記憶體,PoolThreadCache利用ThreadLocal的特性消除了多執行緒競爭,提高記憶體分配效率。首次分配時PoolThreadCache中並沒有可用記憶體進行分配,當上一次分配的記憶體使用完並釋放時,會將其加入到PoolThreadCache中,提供該執行緒下次申請時使用。分配的記憶體大小小於512時記憶體池分配Tiny塊,大小在[512,PageSize]區間時分配Small塊,Tiny塊和Small塊基於Page分配,分配的大小在(PageSize,ChunkSize]區間時分配Normal塊,Normal塊基於Chunk分配,記憶體大小超過Chunk記憶體池無法分配這種大記憶體,直接由JVM堆分配並且記憶體池也不會快取這種記憶體
關於記憶體執行緒私有分配和記憶體公有分配將在下一篇部落格中進行詳細介紹