
Redis Cluster叢集使用與原理
為什麼需要叢集
- 併發量QPS較大
- 資料量較大
高併發和大資料量時, 單機無法滿足,這個時候就需要使用分散式
資料分佈
分散式資料庫-資料分割槽
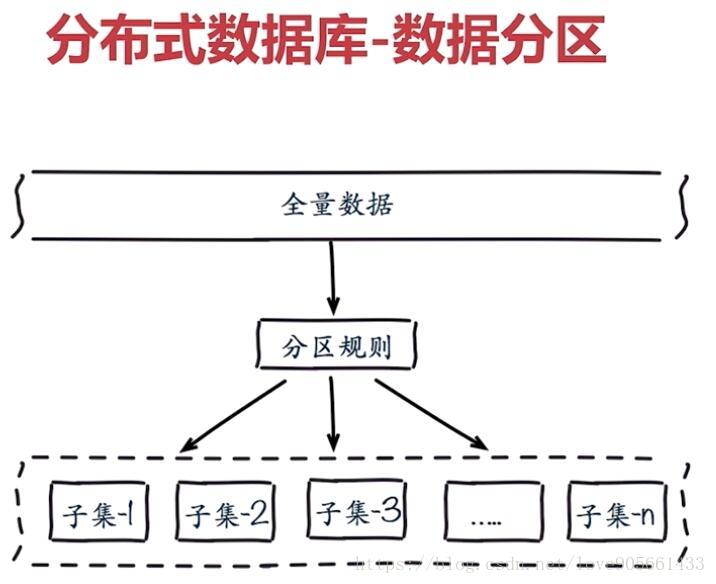
- 順序分割槽
- 雜湊分割槽
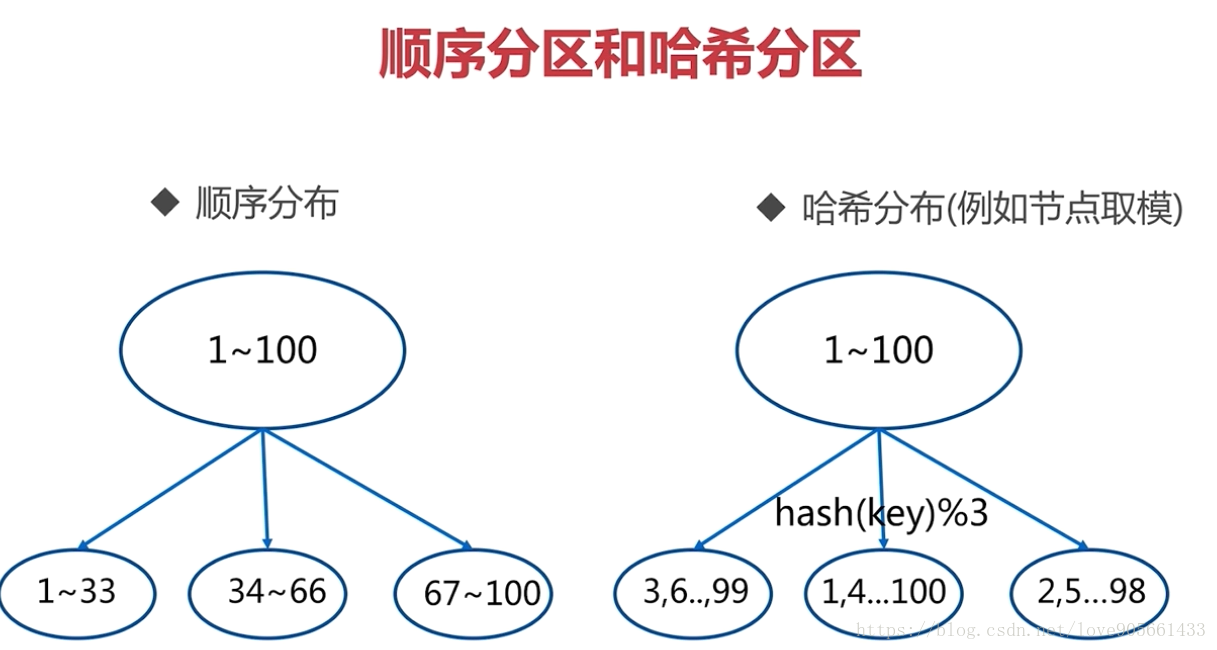
順序分割槽和雜湊分割槽對比 :

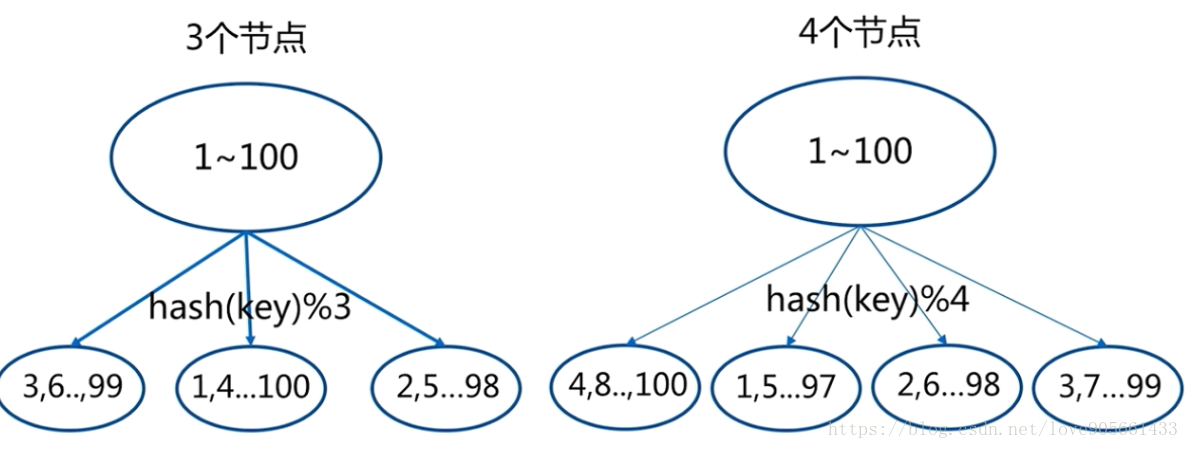
雜湊分割槽
節點取餘(不建議)
客戶端分片 : 雜湊 + 取餘
節點伸縮 : 資料節點關係變化, 導致資料遷移
遷移數量和新增節點數量有關 : 建議翻倍擴容
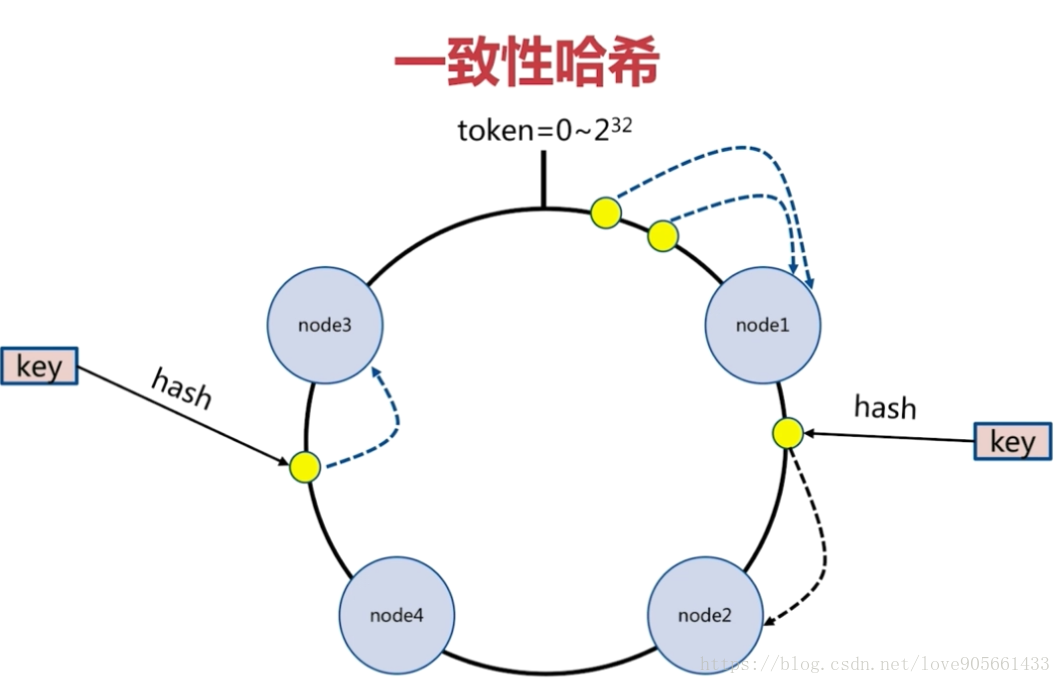
一致性雜湊
- 客戶端分片 : 雜湊 + 順時針(優化取餘)
- 節點伸縮 : 值影響臨近節點, 但還是有資料遷移
- 翻倍伸縮 : 保證最小遷移資料和負載均衡
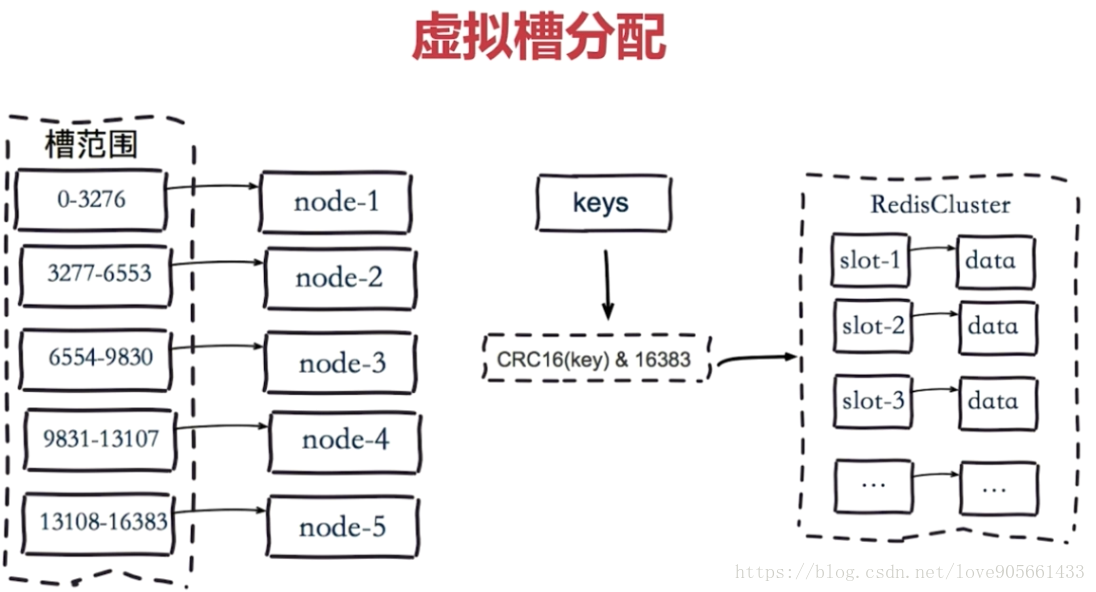
虛擬槽分割槽
預設虛擬槽 : 每個槽對映一個數據子集, 一般比節點數大
良好的雜湊函式 : 例如CRC16
服務端管理節點, 槽, 資料 : 例如Redis Cluster
叢集搭建
基本架構
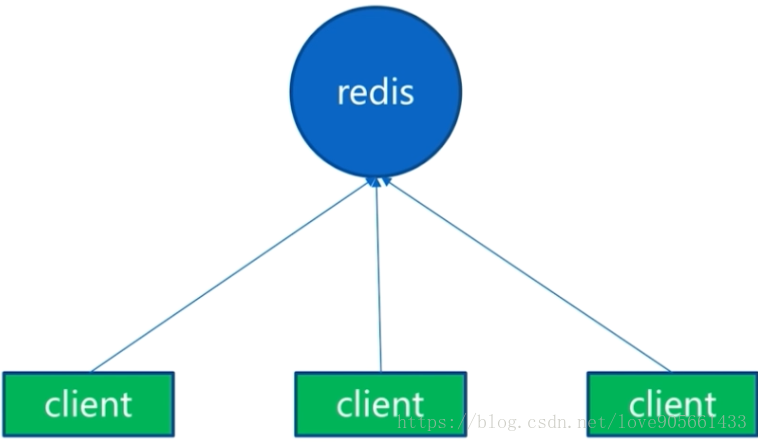
單機架構 :
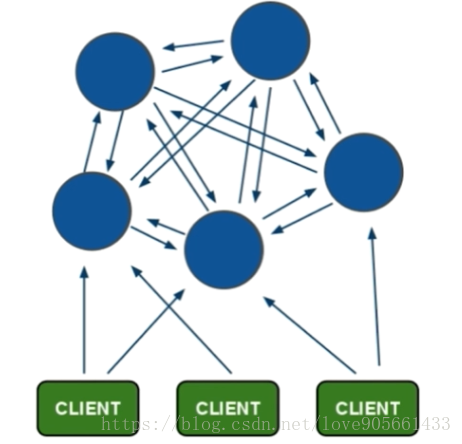
分散式架構 :
Redis Cluster架構
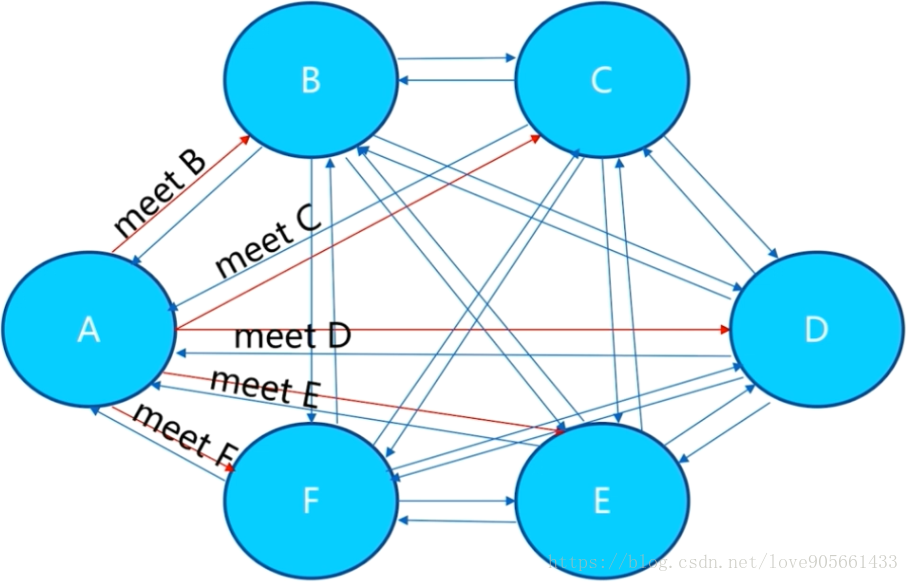
節點
meet : 節點之間進行通訊, 所有節點共享資訊
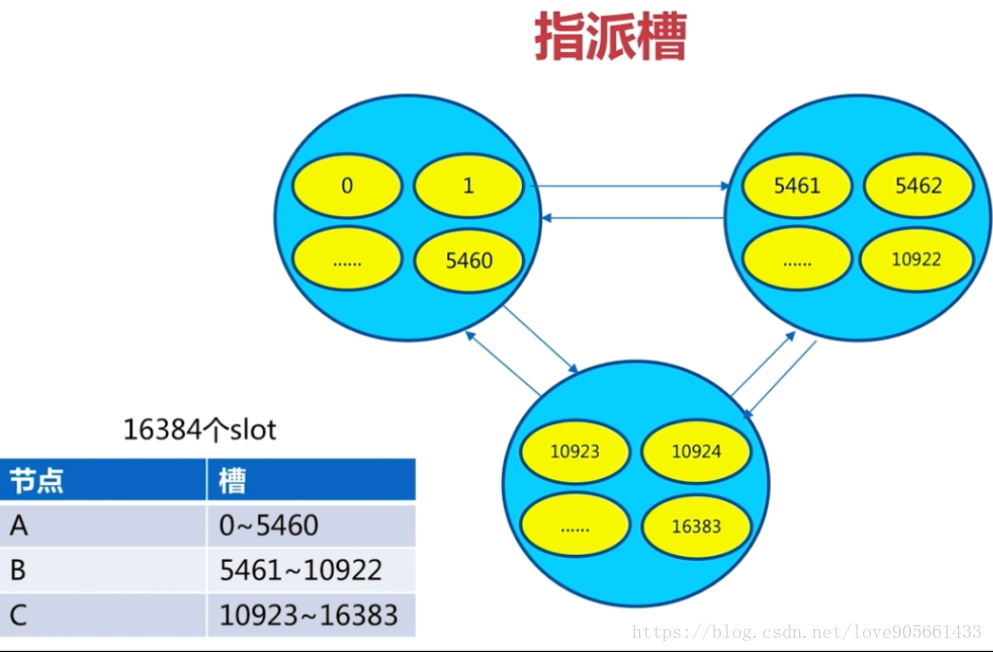
指派槽
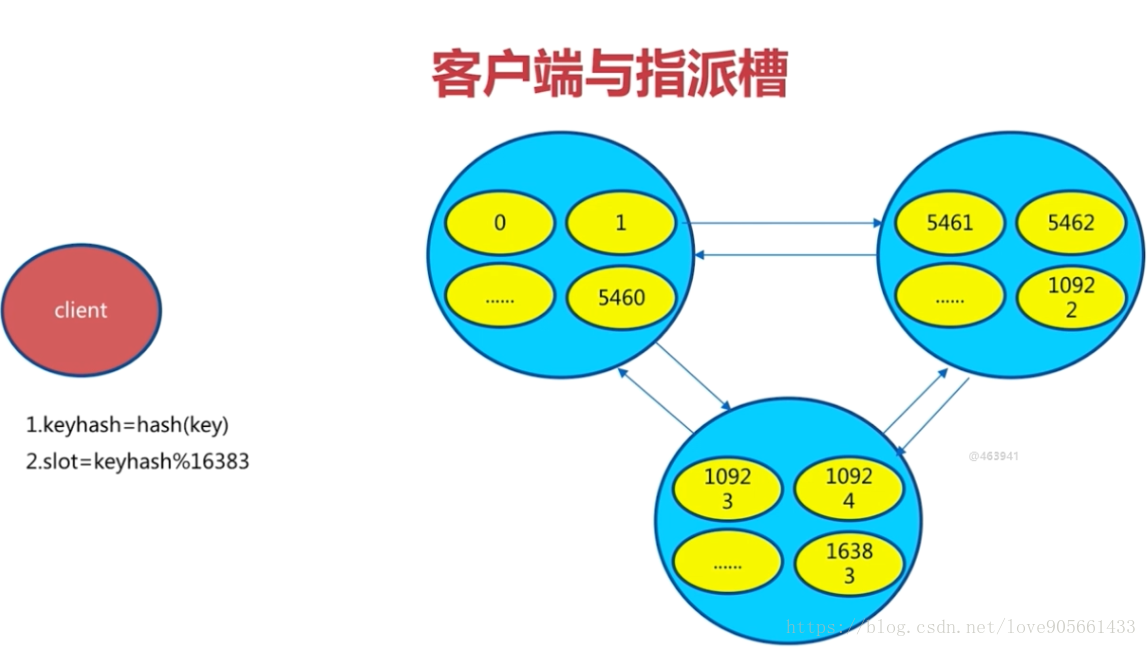
客戶端與指派槽 :
對上面兩幅圖進行一下說明 :
- 將16384個槽分別分配給A, B, C三個節點
- 客戶端訪問時, 根據雜湊對槽進行取餘,就可以獲取到資料存放的槽, 同時也能獲取到負責這個資料槽對應的節點
複製
- 主從複製
- 高可用
- 分片
Redis Cluster安裝
原生命令安裝
- 配置開啟節點
port ${port}
daemonize yes
dir 工作目錄
dbfilename “dump-${port}”.rdb
logfile “\${port}.logcluster-enabled yes : 配置是否開啟cluster
cluster-config-file nodes-${port}.conf : 指定cluster配置檔案, 節點啟動之後會生成這個檔案
meet
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7001
表示從7000 meet 7001
指派槽
cluster addslots slot[slot…]
redis-cli -h 127.0.0.1 -p 7000 cluster addslots {0…5461}, 將0-5461的槽分配給7000節點
設定主從
cluster replicate node-id
redis-cli -h 127.0.0.1 -p 7003 cluster replicate ${node-id-7000}, 表示7003節點去複製7000節點,作為7000節點的從節點
node-id在節點啟動之後生成的cluster配置檔案中檢視
Cluster節點主要配置
- cluster-enabled yes : 表示當前節點是Cluster節點
- cluster-node-timeout 15000 : 故障轉移的時間,節點超時的時間,Redis中這個配置有很多用處
- cluster-config-file “nodes.conf” : 叢集節點的配置
- cluster-require-full-coverage yes : 是否需要叢集內所有節點都正常才能提供服務, 預設是yes,通常設定為no
官方工具安裝叢集
Ruby環境準備
下載, 編譯, 安裝Ruby
解壓: tar -zxvf ruby-2.5.1.tar.gz
- ./configure -prefix=/usr/local/ruby
- make
- make install
- cd /usr/local/ruby
- cp bin/ruby /usr/local/bin
- cp bin/gem /usr/local/bin
安裝rubygem redis客戶端
下載rubygem redis客戶端
gem install -l redis-3.3.0.gem
gem list – check redis gem
安裝redis-trip.rb
拷貝redis-trip.rb指令碼到/usr/local/bin目錄下
cp ${REDIS_HOME}/src/redis-trib.rb /usr/local/bin/
建立叢集
一鍵開啟
redis-trib.rb create –replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
注: replicas 後面跟的1表示每個節點有幾個從節點
叢集伸縮
擴容叢集
準備新節點
- 叢集模式
- 配置和其他節點統一
- 啟動後是孤兒節點
加入叢集 :
加入叢集-作用 :
- 為它遷移槽和資料實現擴容
- 作為從節點負責故障轉移
加入叢集方式 :
直接執行meet命令加入叢集
使用redis官方提供的redis-trib.rb指令碼加入叢集
- redis-trip.rb add-node new_host:new_port existing_host:existing_port –slave –master-id
- redis-trip.rb add-node 127.0.0.1:6385 127.0.0.1:6379
建議使用redis-trip.rb,能夠避免新節點已經加入其他叢集,造成故障
遷移槽和資料
槽遷移計劃
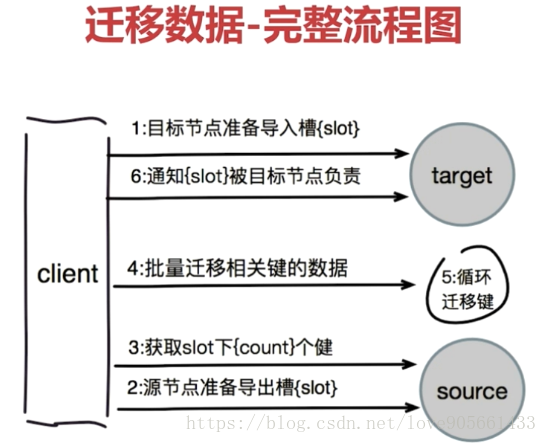
遷移資料
對目標節點發送 : cluster setslot {slot} importing {sourceNodeId}命令, 讓目標節點準備匯入槽的資料.
對源節點發送 : cluster setslot {slot} migrating {targetNodeId}命令, 讓源節點準備遷出槽的資料.
源節點迴圈執行 : cluster getkeysinslot {slot} {count}命令, 每次獲取count個屬於從槽的鍵.
在源節點上執行 : migrate {targetIP} {targetPort} key 0 {timeout} 命令把指定的key遷移.
重複執行步驟3~4直到槽下所有的鍵資料遷移到目標節點
向叢集內所有主節點發送cluster setslot {slot} node {targetNodeId} 命令, 通知槽分配給目標節點
遷移資料-完整流程圖如下:
新增從節點
收縮叢集
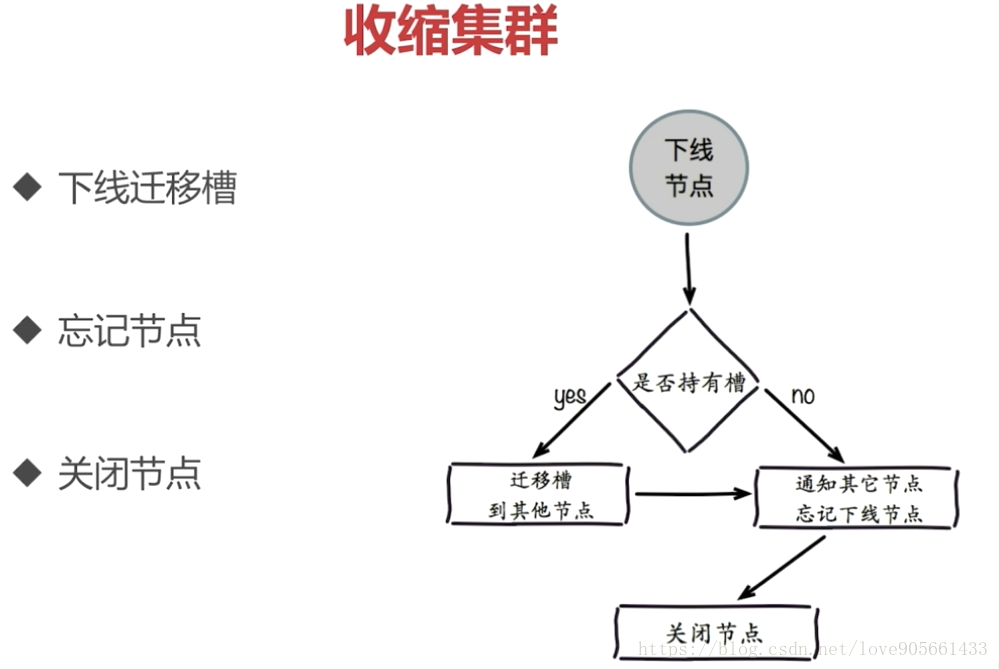
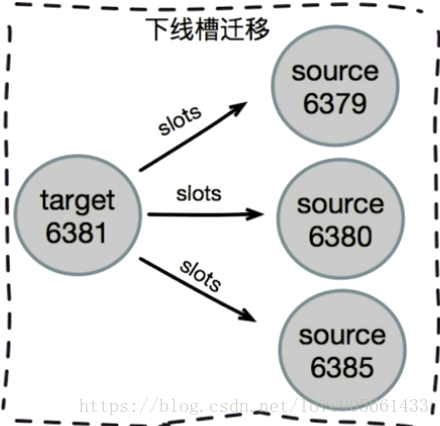
下線遷移槽
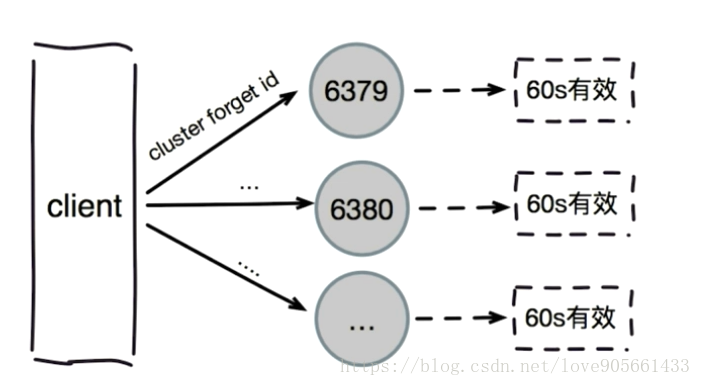
忘記節點
cluster forget {downNodeId}
關閉節點
客戶端路由
moved重定向
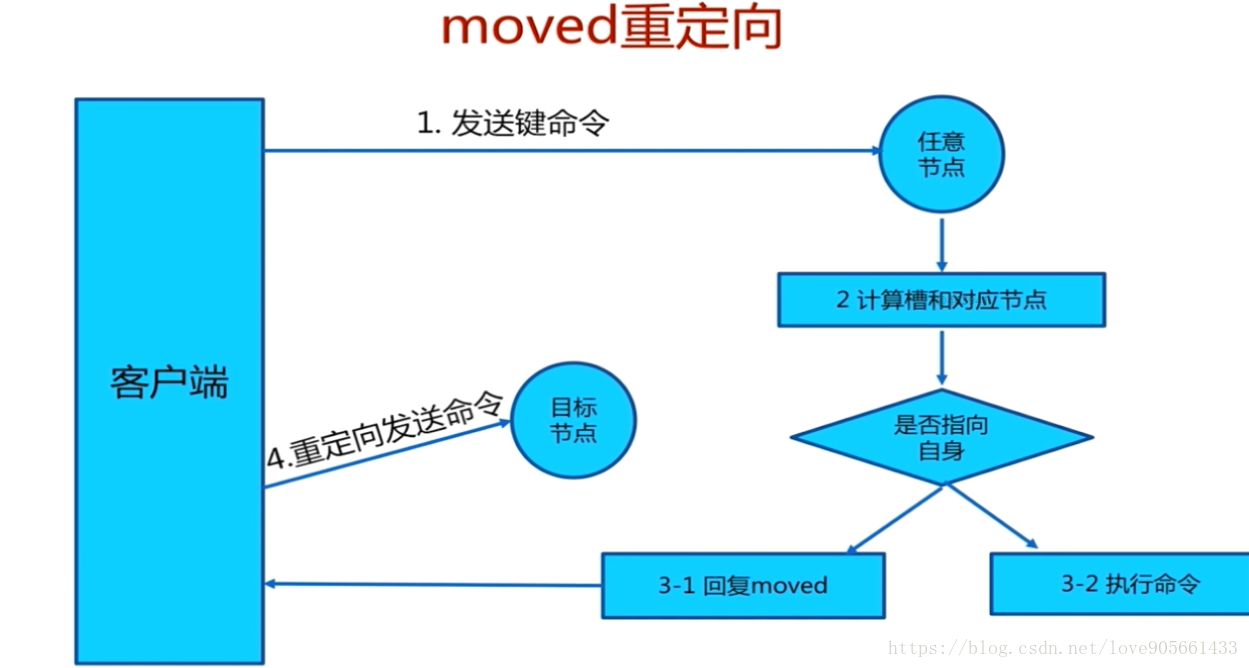
槽命中 :

槽未命中 :

ASK重定向
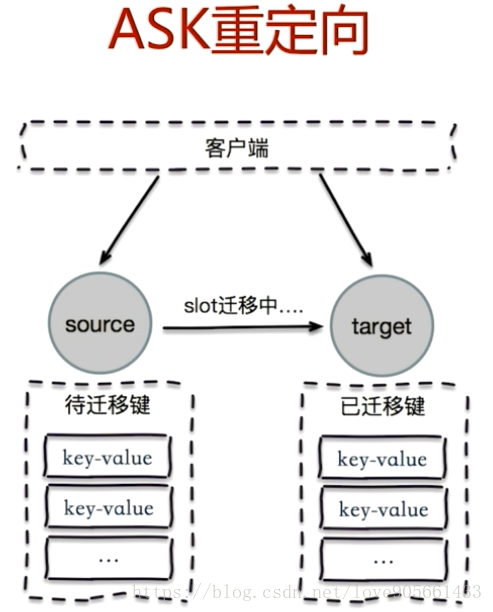

moved和ask區別
- 兩者都是客戶單重定向
- moved : 槽已經確定遷移
- ask : 槽還在遷移中
Smart客戶端 : 追求效能
- 從叢集中選一個可執行節點, 使用cluster slots初始化槽和節點對映
- 將cluster slots的結果對映到本地, 為每個節點建立JedisPool
- 準備執行命令, 客戶端原始碼JedisClusterCommand
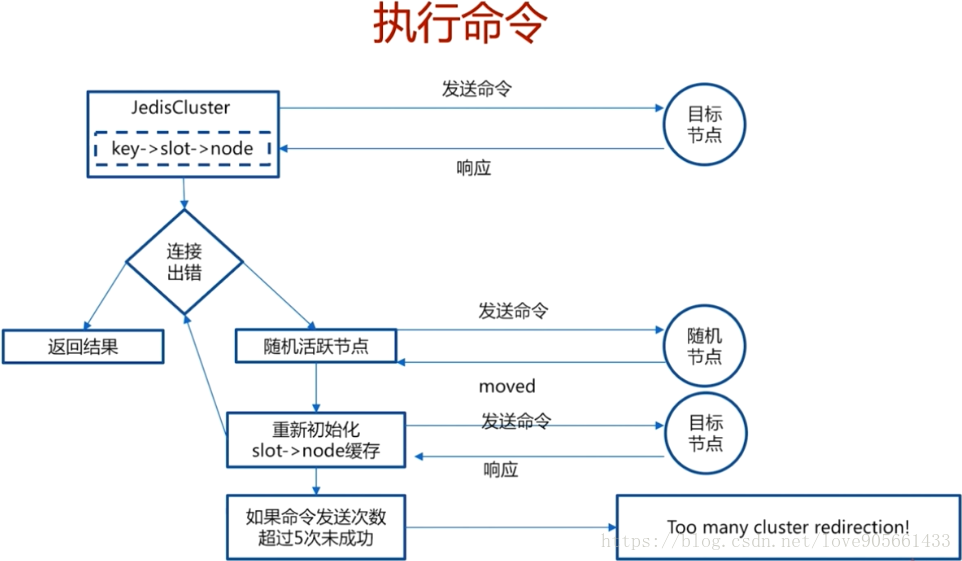
smart客戶端使用-JedisCluster
JedisCluster基本使用
- 單例 : 內建了所有節點的連線池
- 無需手動借還連線池
- 合理設定commons-pool

多節點命令實現

批量命令實現
序列mget
序列IO
並行IO
hash_tag
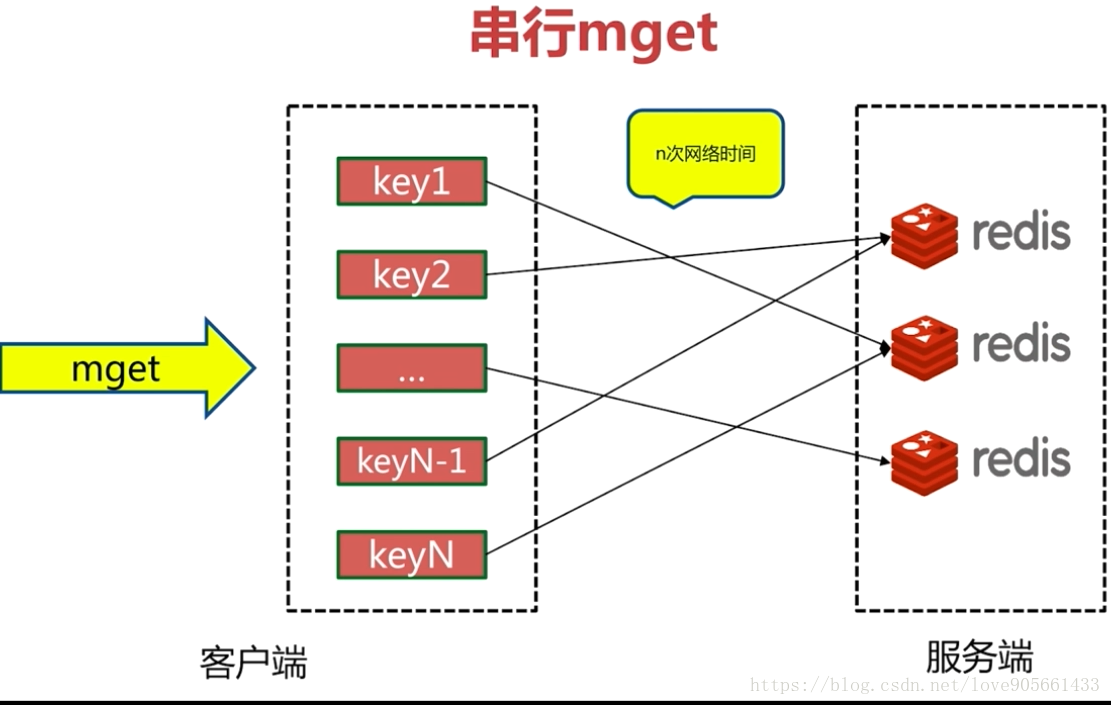
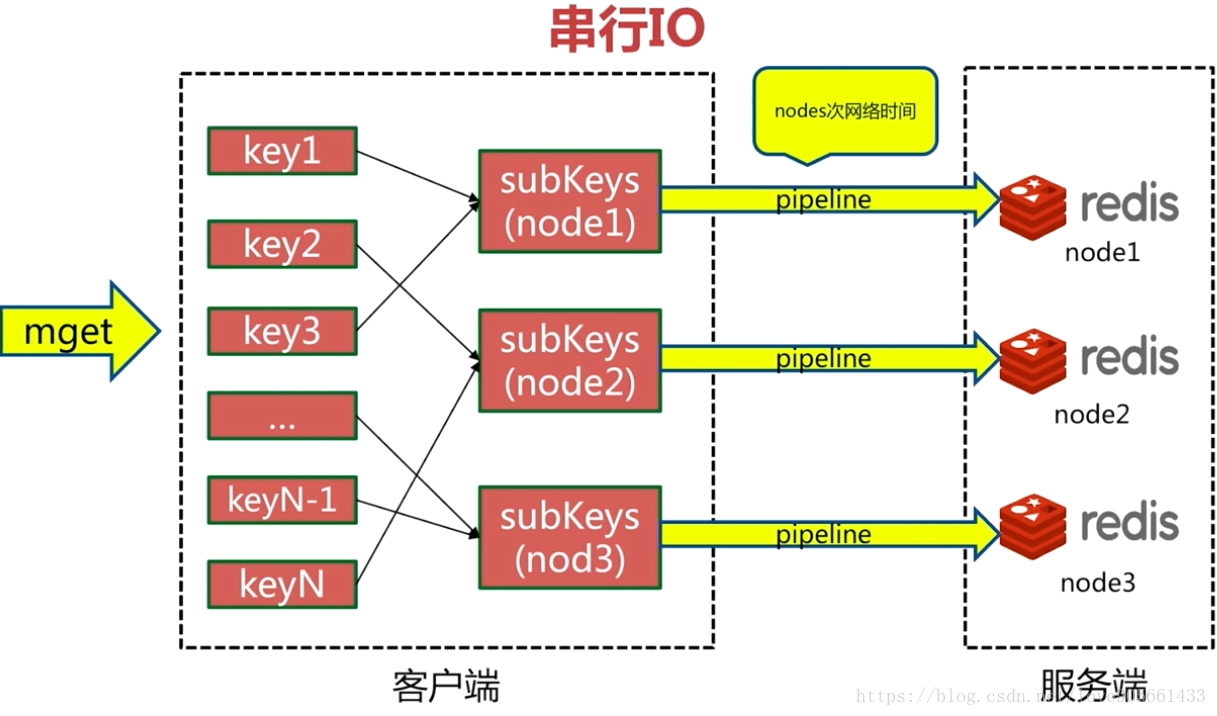
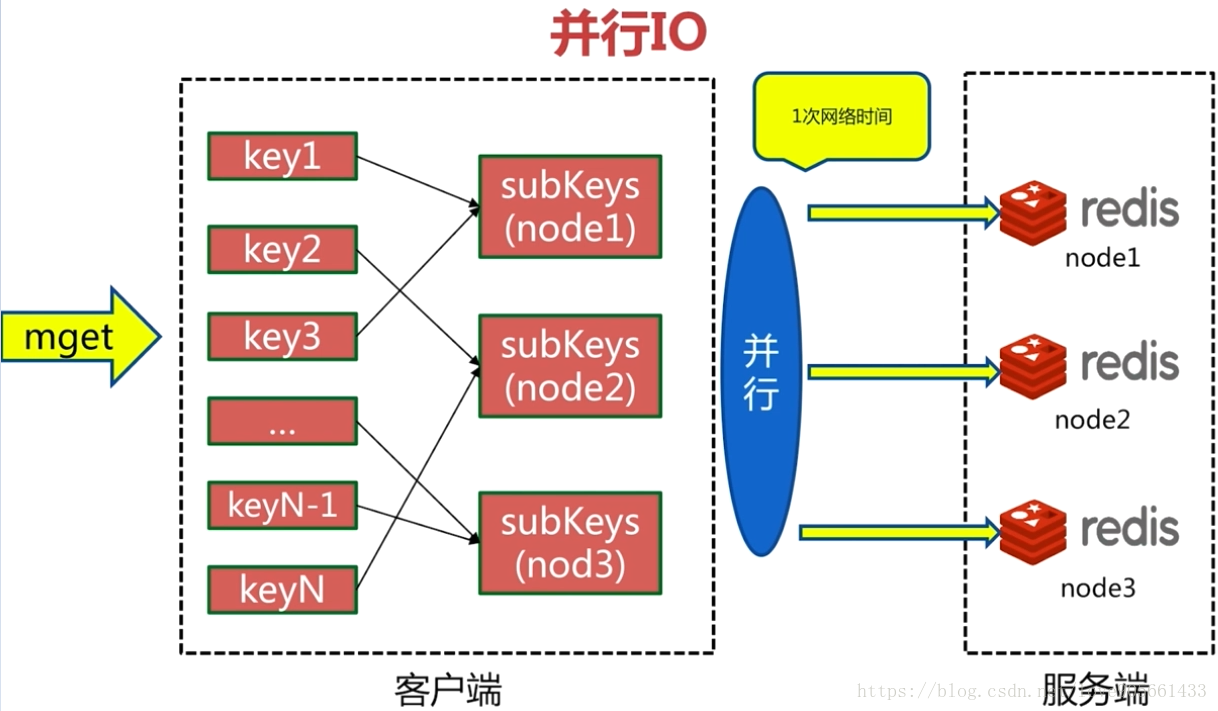
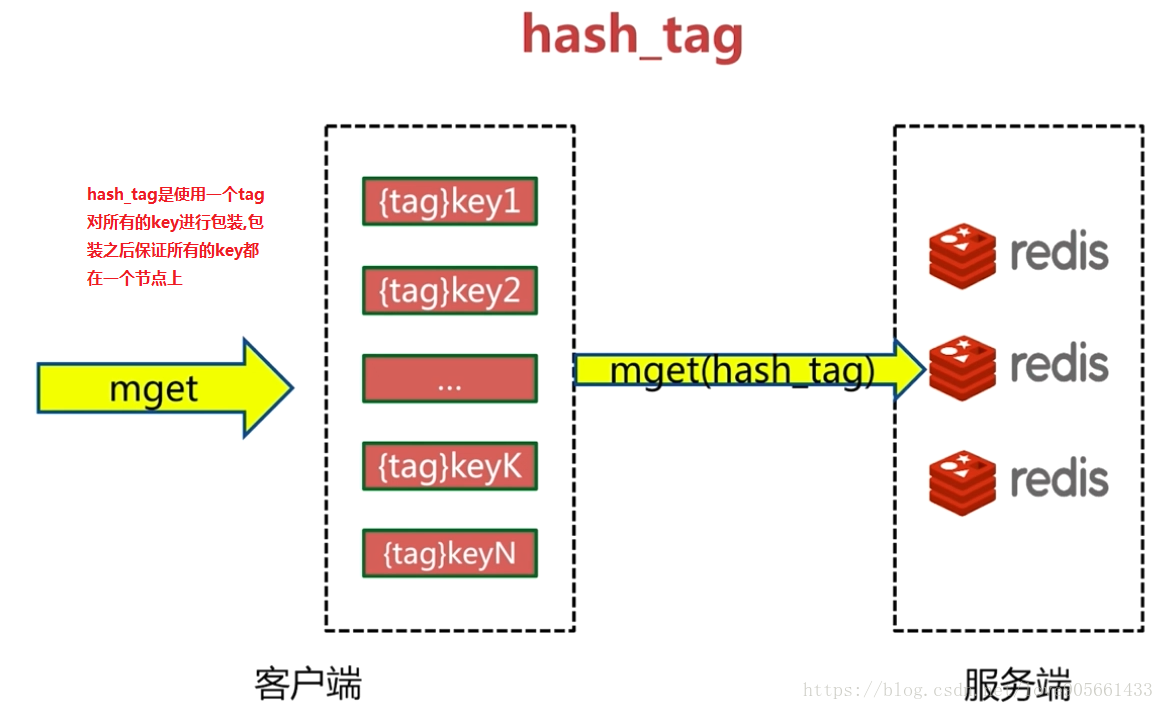
四種方案優缺點分析

Redis Cluster故障轉移
故障發現
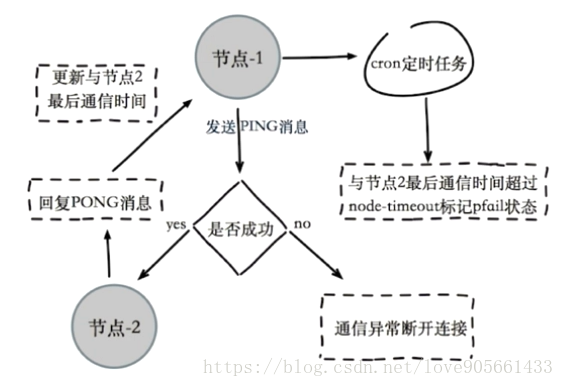
通過ping/pong訊息實現故障發現 : 不需要sentinel
主觀下線和客觀下線
- 主觀下線
定義 : 某個節點認為另一個節點不可用, “偏見”
主觀下線流程 :
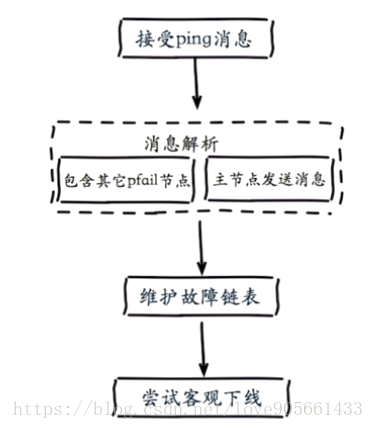
- 客觀下線
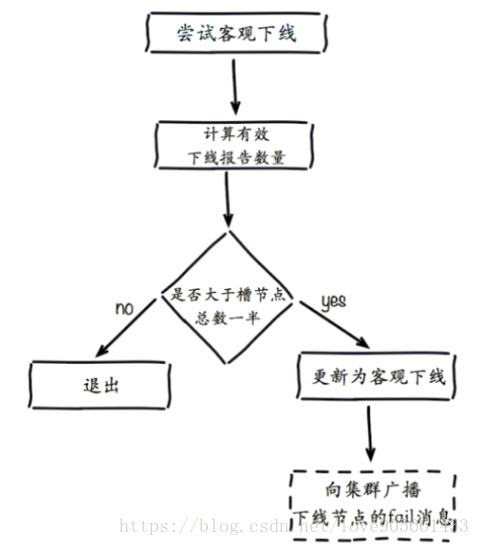
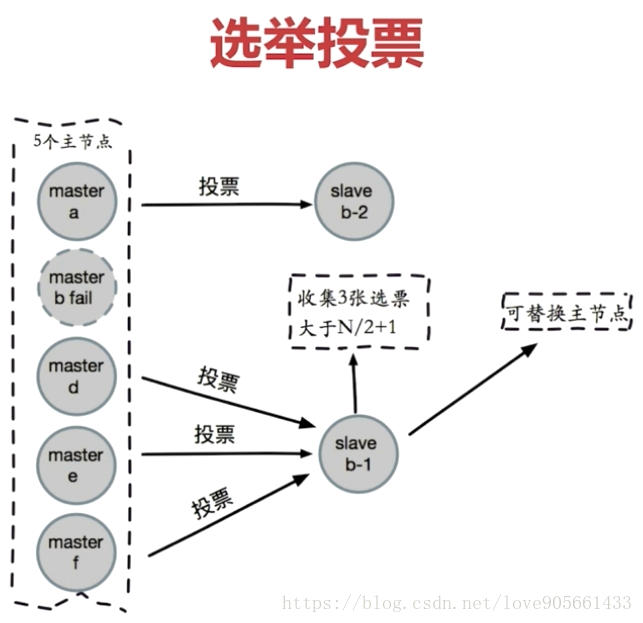
定義 : 當半數以上持有槽的主節點都標記某節點主觀下線
客觀下線邏輯流程 :
嘗試客觀下線流程 :
- 通知叢集內所有節點標記故障節點為客觀下線
- 通知故障節點的從節點觸發故障轉移流程
故障恢復
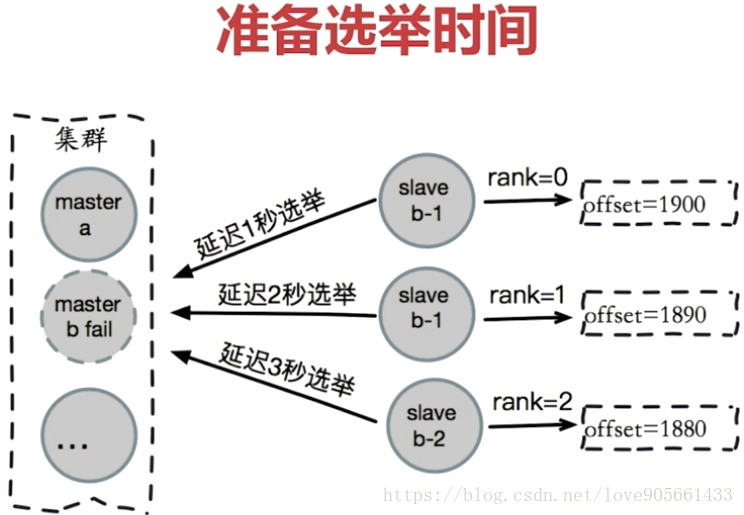
資格檢查
- 每個從節點檢查與故障主節點的斷線時間
- 超過cluster-node-timeout * cluster-slave-validity-factor取消資格
- cluster-slave-validity-factor : 預設是10
準備選舉時間
選舉投票
替換主節點
- 當前從節點取消複製變為主節點(slaveof no one)
- 執行clusterDelSlot撤銷故障主節點負責的槽, 並執行clusterAddSlot把這些槽分配給自己
- 向叢集廣播自己的pong訊息, 表明已經替換了故障從節點
Redis Cluster開發運維常見問題
叢集完整性
cluster-require-full-coverage預設為yes
- 叢集中16384槽全部可用 : 保證叢集完整性
- 節點故障或者正在故障轉移 : (error)CLUSTERDOWN The cluster is down
大多數業務無法容忍, cluster-require-full-coverage建議設定為no
頻寬消耗
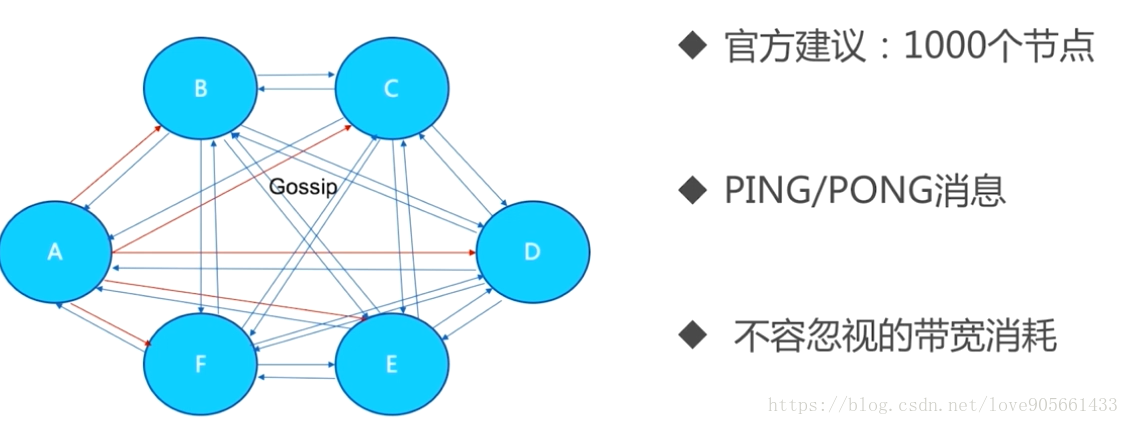
- 訊息傳送頻率 : 節點發現與其它節點最後通訊時間超過cluster-node-timeout/2時會直接傳送ping訊息
- 訊息資料量 : slots槽陣列(2KB空間)和整個叢集1/10的狀態資料(10個節點狀態資料約1KB)
- 節點部署的機器規模 : 叢集分佈的機器越多且每臺機器劃分的節點數越均勻, 則叢集內整體的可用頻寬越高
優化 :
- 避免”大”叢集 : 避免多業務使用一個叢集, 大業務可以多叢集
- cluster-node-timeout : 頻寬和故障轉移速度的均衡
- 儘量均勻分配到多機器上 : 保證高可用和頻寬
Pub/Sub廣播
- 問題 : publish在叢集每個節點廣播, 加重頻寬
- 解決 : 單獨”走”一套Redis Sentinel
叢集傾斜
資料傾斜 : 記憶體不均
- 節點和槽分配不均
- 不同槽對應鍵值數量差異較大
- CRC16正常情況下比較均勻
- 可能存在hash_tag
- cluster countkeysinslot {slot}獲取槽對應鍵值個數
- 包含bigkey
- 如大字元中, 幾百萬元素的hash,set等
- 從節點使用redis-cli –bigkeys 查詢bigkey
- 優化 : 優化資料結構
- 記憶體相關配置不一致
- hash-max-ziplist-value, set-max-insert-entries等
- 優化 : 定期”檢查”配置一致性
請求傾斜 : 熱點
- 熱點key : 重要的key或者bigkey
- 優化 :
- 避免bigkey
- 熱鍵不要用hash_tag
- 當一致性不高時, 可以用本地快取 + MQ
讀寫分離
只讀連結 : 叢集模式的從節點不接受任何讀寫請求
- 對從節點讀取時, 會重定向到負責槽的主節點
- readonly命令可以讀 : 連線級別命令
讀寫分離 : 更加複雜, 不建議叢集模式下使用讀寫分離
- 同樣的問題 : 複製延遲, 讀取過期資料, 從節點故障
- 修改客戶端 : cluster slaves {nodeId}
資料遷移
官方遷移工具 : redis-trip.rb import
- 只能從單機遷移到叢集
- 不支援線上遷移 : source需要停寫
- 不支援斷點續傳
- 單執行緒遷移 : 影響速度
線上遷移 :
- 唯品會redis-migrate-tool
- 豌豆莢 : redis-port
叢集vs單機
叢集限制
- key批量操作支援有限 : mget, mset必須在一個slot
- Key事務和Lua支援有限 : 操作的key必須在一個節點
- key是資料分割槽的最小粒度 : 不支援bigkey分割槽
- 不支援多個數據庫 : 叢集模式下只有一個db 0
- 複製只支援一層 : 不支援樹形複製結構
思考-分散式Redis不一定好
- Redis Cluster : 滿足容量和效能的擴充套件性, 很多業務”不需要”
- 大多數時客戶端效能會”降低”
- 命令無法跨節點使用 : mget, keys, scan, flush, sinter等
- Luau和事務無法跨節點使用
- 客戶端維護更復雜 : SDK和應用本身銷燬
- 很多場景Redis Sentinel已經足夠好
叢集總結
- Redis cluster資料分割槽規則採用虛擬槽方式(16384個槽), 每個節點負責一部分槽和相關資料, 實現資料和請求的負載均衡
- 搭建叢集劃分四個步驟 : 準備節點, 節點握手, 分配槽, 複製.redis-trip.rb工具用於快速搭建叢集.
- 叢集伸縮通過在節點之間移動槽和相關資料實現
- 擴容時根據槽遷移計劃把槽從源節點遷移到新節點
- 收縮時如果下線的節點有負責的槽需要遷移到其他的節點, 再通過cluster forget命令讓叢集內所有節點忘記被下線節點
- 使用smart客戶端操作叢集達到通訊效率最大化, 客戶端內部負責計算維護鍵->槽->節點的對映, 用於快速定位到目標節點
- 叢集自動故障轉移過程分為故障發現和節點恢復. 節點下線分為主觀下線和客觀下線, 當超過半數節點認為故障節點為主觀下線是標記它為客觀下線狀態.從節點負責對客觀下線的主節點觸發故障恢復流程, 保證叢集的可用性.
- 開發運維常見問題 : 超大規模叢集頻寬消耗, pub/sub廣播問題, 叢集傾斜問題, 單機和叢集對比等