
Linux 執行緒及程序總結
1 Linux 中的程序與執行緒
對於 Linux 來講,所有的執行緒都當作程序來實現,因為沒有單獨為執行緒定義特定的排程演算法,也沒有單獨為執行緒定義特定的資料結構(所有的執行緒或程序的核心資料結構都是 task_struct)。
對於一個程序,相當於是它含有一個執行緒,就是它自身。對於多執行緒來說,原本的程序稱為主執行緒,它們在一起組成一個執行緒組。
程序擁有自己的地址空間,所以每個程序都有自己的頁表。而執行緒卻沒有,只能和其它執行緒共享某一個地址空間和同一份頁表。
這個區別的 根本原因 是,在程序/執行緒建立時,因是否拷貝當前程序的地址空間還是共享當前程序的地址空間,而使得指定的引數不同而導致的。
具體地說,程序和執行緒的建立都是執行 clone 系統呼叫進行的。而 clone 系統呼叫會執行 do_fork 核心函式,而它則又會呼叫 copy_process 核心函式來完成。主要包括如下操作:
- 在呼叫 copy_process 的過程中,會建立並拷貝當前程序的 task_stuct,同時還會建立屬於子程序的 thread_info 結構以及核心棧。
- 此後,會為建立好的 task_stuct 指定一個新的 pid(在 task_struct 結構體中)。
- 然後根據傳遞給 clone 的引數標誌,來選擇拷貝還是共享開啟的檔案,檔案系統資訊,訊號處理函式,程序地址空間等。這就是程序和執行緒不一樣地方的本質所在。
2 三個資料結構
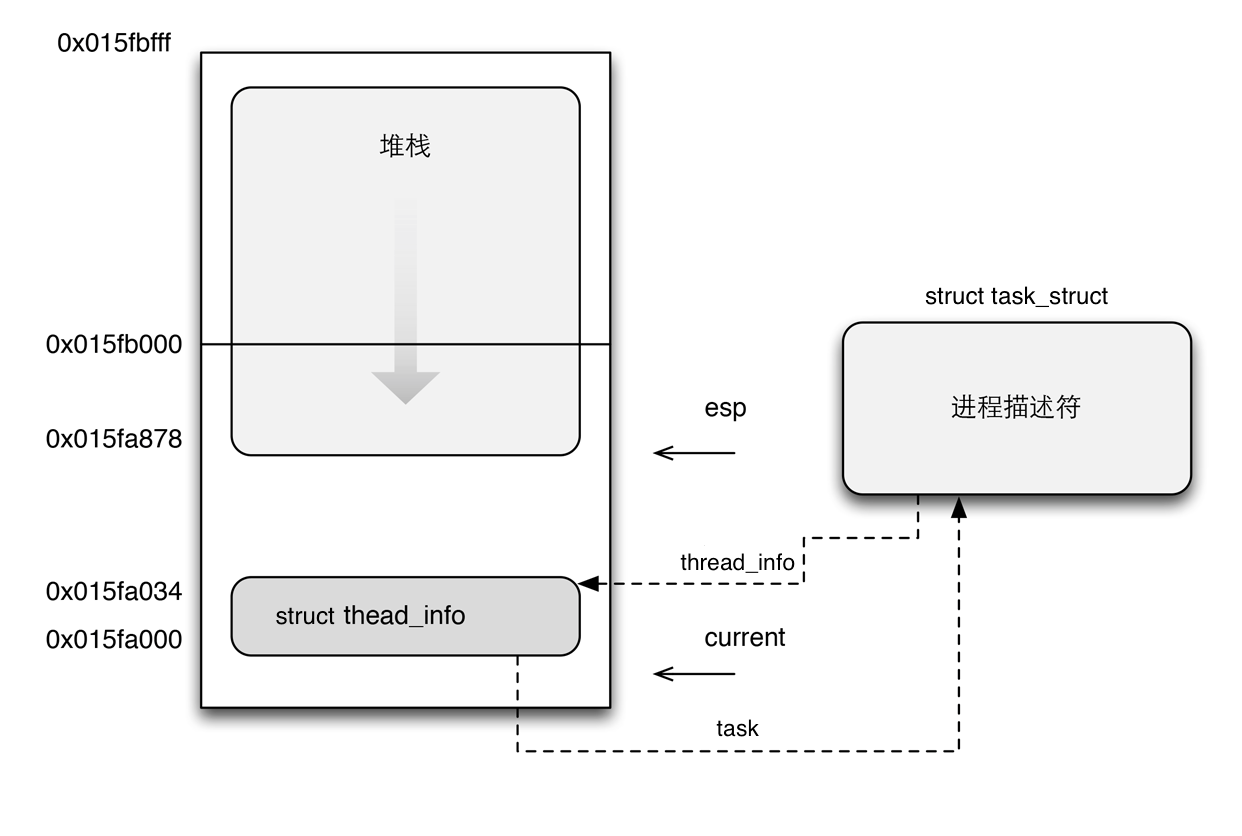
每個程序或執行緒都有三個資料結構,分別是 struct thread_info, struct task_struct 和 核心棧。
注意,雖然執行緒與主執行緒共享地址空間,但是執行緒也是有自己獨立的核心棧的。
thread_info 物件中存放的程序/執行緒的基本資訊,它和這個程序/執行緒的核心棧存放在核心空間裡的一段 2 倍頁長的空間中。其中 thread_info 結構存放在低地址段的末尾,其餘空間用作核心棧。核心使用 夥伴系統 為每個程序/執行緒分配這塊空間。
thread_info 結構體中有一個 struct task_struct *task
如下圖所示:
3 task_struct 結構體
每個程序或執行緒都有隻屬於自己的 task_struct 物件,是它們各自最為核心的資料結構。
3.1 task_struct 結構體中的主要元素
- struct thread_info *thread_info。thread_info 指向該程序/執行緒的基本資訊。
- struct mm_struct *mm。mm_struct 物件用來管理該程序/執行緒的頁表以及虛擬記憶體區。
- struct mm_struct *active_mm。主要用於核心執行緒訪問主核心頁全域性目錄。
- struct fs_struct *fs。fs_struct 是關於檔案系統的物件。
- struct files_struct *files。files_struct 是關於開啟的檔案的物件。
- struct signal_struct *signal。signal_struct 是關於訊號的物件。
3.2 task_struct 結構體中的三個 ID 與一個指標
- pid
每個 task_struct 都會有一個不同的 ID,就是這個 PID。 - tid
執行緒 ID,用來標識每個執行緒的。 -
tgid
執行緒組領頭執行緒的 PID,事實上就是主執行緒的 PID。
當建立一個子程序時,它的 tgid 與 pid 相等;
當建立一個執行緒時,它的 tgid 等於主執行緒的 pid。getpid() 函式事實上返回的是當前程序或執行緒的 tgid。
- pgid
程序組領頭程序的 PID。 - sid
會話領頭程序的 PID。 - group_leader
是一個 task_struct 型別的指標,指向的是程序組的組長對應的 task_struct 物件。
4 虛擬記憶體地址空間
4.1 記憶體管理
記憶體是由核心來管理的。
記憶體被分為 n 個頁框,然後進一步組織為多個區。而裝入頁框中的內容稱為頁。
當核心函式申請記憶體時,核心總是立即滿足(因為核心完全信任它們,所以優先順序最高)。在分配適當記憶體空間後,將其對映到核心地址空間中(3-4GB 中的某部分空間),然後將地址對映寫入頁表。
申請記憶體空間的核心函式有 vmalloc, kmalloc, alloc_pages, __get_free_pages 等。
4.2 核心常駐記憶體
就是說,核心地址空間(3-4GB)中的頁面所對映的頁框始終在實體記憶體中存在,不會被換出。即使是 vmalloc 動態申請的頁面也會一直在實體記憶體中,直至通過相關核心函式釋放掉。
其原因在於,一方面核心檔案不是太大,完全可以一次性裝入實體記憶體;另一方面在於即使是動態申請記憶體空間,也能立即得到滿足。
因此,處於核心態的普通程序或核心執行緒(後面會提到)不會因為頁面沒有在記憶體中而產生缺頁異常(不過處於核心態的普通程序會因為頁表項沒有同步的原因而產生缺頁異常)。
4.3 為什麼要有虛擬地址空間
普通程序在申請記憶體空間時會被核心認為是不緊要的,優先順序較低。因而總是延遲處理,在之後的某個時候才會真正為其分配實體記憶體空間。
比如,普通程序中的 malloc 函式在申請實體記憶體空間時,核心不會直接為其分配頁框。
另一方面,普通程序對應的可執行程式檔案較大,不能夠立即裝入記憶體,而是採取執行時按需裝入。
要實現這種延遲分配策略,就需要引入一種新的地址空間,即 虛擬地址空間。可執行檔案在裝入時或者程序在執行 malloc 時,核心只會為其分配適當大小的虛擬地址空間。
虛擬地址空間並不單純地指線性地址空間。準確地說,指的是頁面不能因為立即裝入實體記憶體而採取折衷處理後擁有的線性地址空間。
因此,雖然普通程序的虛擬地址空間為 4GB,但是從核心的角度來說,核心地址空間(也是線性空間)不能稱為虛擬地址空間,核心執行緒不擁有也不需要虛擬地址空間。
因此,虛擬地址空間只針對普通程序。
當然,這樣的話就會產生所要訪問的頁面不在實體記憶體中而發生缺頁異常。
4.4 虛擬地址空間的劃分
每一個普通程序都擁有 4GB 的虛擬地址空間(對於 32 位的 CPU 來說,即 2^32 B)。
主要分為兩部分,一部分是使用者空間(0-3GB),一部分是核心空間(3-4GB)。每個普通程序都有自己的使用者空間,但是核心空間被所有普通程序所共享。
如下圖所示:
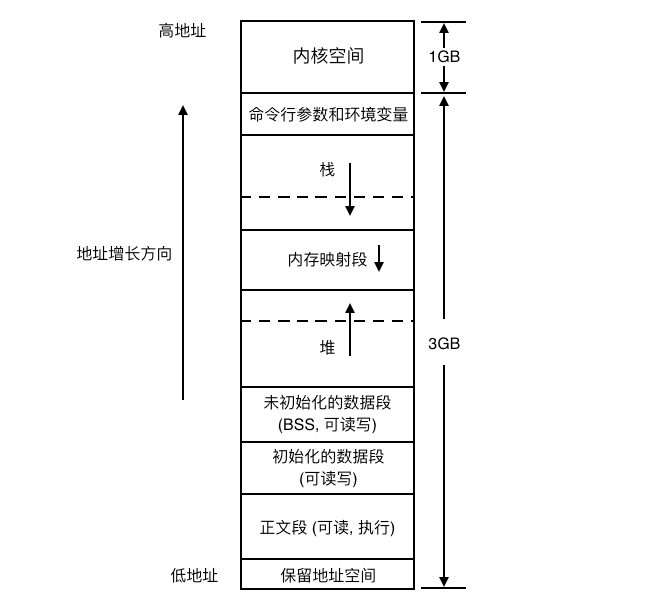
之所以能夠使用 3-4GB 的虛擬地址空間(對於普通程序來說),是因為每個程序的頁全域性目錄(後面會提到)中的後面部分存放的是核心頁全域性目錄的所有表項。當通過系統呼叫或者發生異常而陷入核心時,不會切換程序的頁表。此時,處於核心態的普通程序將會直接使用程序頁表中前面的頁表項即可。這也是為什麼在執行系統呼叫或者處理異常時沒有發生程序的上下文切換的真實原因。
同樣,正因為每個程序的也全域性目錄中的後面部分存放的是核心頁全域性目錄中的所有表項,所以所有普通程序共享核心空間。
另外,
- 使用者態下的普通程序只能訪問 0-3GB 的使用者空間;
- 核心態下的普通程序既能訪問 0-3GB 的使用者空間,也能訪問 3-4GB 的核心空間(核心態下的普通程序有時也會需要訪問使用者空間)。
4.5 普通執行緒的使用者堆疊與暫存器
對於多執行緒環境,雖然所有執行緒都共享同一片虛擬地址空間,但是每個執行緒都有自己的使用者棧空間和暫存器,而使用者堆仍然是所有執行緒共享的。
棧空間的使用是有明確限制的,棧中相鄰的任意兩條資料在地址上都是連續的。試想,假設多個普通執行緒函式都在執行遞迴操作。如果多個執行緒共有使用者棧空間,由於執行緒是非同步執行的,那麼某個執行緒從棧中取出資料時,這條資料就很有可能是其它執行緒之前壓入的,這就導致了衝突。所以,每個執行緒都應該有自己的使用者棧空間。
暫存器也是如此,如果共用暫存器,很可能出現使用混亂的現象。
而堆空間的使用則並沒有這樣明確的限制,某個執行緒在申請堆空間時,核心只要從堆空間中分配一塊大小合適的空間給執行緒就行了。所以,多個執行緒同時執行時不會出現向棧那樣產生衝突的情況,因而執行緒組中的所有執行緒共享使用者堆。
那麼在建立執行緒時,核心是怎樣為每個執行緒分配棧空間的呢?
由之前所講解可知,程序/執行緒的建立主要是由 clone 系統呼叫完成的。而 clone 系統呼叫的引數中有一個 void *child_stack,它就是用來指向所建立的程序/執行緒的堆疊指標。
而在該程序/執行緒在使用者態下是通過呼叫 pthread_create 庫函式而陷入核心的。對於 pthread_create 函式,它則會呼叫一個名為 pthread_allocate_stack 的函式,專門用來為所建立的執行緒分配的棧空間(通過 mmap 系統呼叫)。然後再將這個棧空間的地址傳遞給 clone 系統呼叫。這也是為什麼執行緒組中的每個執行緒都有自己的棧空間。
4.6 普通程序的頁表
有兩種頁表,一種是核心頁表(會在後面說明),另一種是程序頁表。
普通程序使用的則是程序頁表,而且每個普通程序都有自己的程序頁表。如果是多執行緒,則這些執行緒共享的是主執行緒的程序頁表。
4.6.1 四級頁表
現在的 Linux 核心中採用四級頁表,分別為:
- 頁全域性目錄 (Page Global Directory, pgd);
- 頁上級目錄 (Page Upper Directory, pud);
- 頁中間目錄 (Page Middle Directory, pmd);
- 頁表 (Page Table, pt)。
task_struct 中的 mm_struct 物件用於管理該程序(或者執行緒共享的)頁表。準確地說,mm_struct 中的 pgd 指標指向著該程序的頁全域性目錄。
4.6.2 普通程序的頁全域性目錄
普通程序的頁全域性目錄中,第一部分表項對映的線性地址為 0-3GB 部分,剩餘部分存放的是主核心頁全域性目錄(後面會提到)中的所有表項。
5 核心執行緒
核心執行緒是一種只執行在核心地址空間的執行緒。所有的核心執行緒共享核心地址空間(對於 32 位系統來說,就是 3-4GB 的虛擬地址空間),所以也共享同一份核心頁表。這也是為什麼叫核心執行緒,而不叫核心程序的原因。
由於核心執行緒只執行在核心地址空間中,只會訪問 3-4GB 的核心地址空間,不存在虛擬地址空間,因此每個核心執行緒的 task_struct 物件中的 mm 為 NULL。
普通執行緒雖然也是同主執行緒共享地址空間,但是它的 task_struct 物件中的 mm 不為空,指向的是主執行緒的 mm_struct 物件。
普通程序與核心執行緒有如下區別:
- 核心執行緒只執行在核心態,而普通程序既可以執行在核心態,也可以執行在使用者態;
- 核心執行緒只使用 3-4GB (假設為 32 位系統) 的核心地址空間(共享的),但普通程序由於既可以執行在使用者態,又可以執行在核心態,因此可以使用 4GB 的虛擬地址空間。
系統在正式啟動核心時,會執行 start_kernel 函式。在這個函式中,會自動建立一個程序,名為 init_task。其 PID 為 0,執行在核心態中。然後開始執行一系列初始化。
5.1 init 核心執行緒
init_task 在執行 rest_init 函式時,會執行 kernel_thread 建立 init 核心執行緒。它的 PID 為 1,用來完成核心空間初始化。
在核心空間完成初始化後,會呼叫 exceve 執行 init 可執行程式 (/sbin/init)。之後,init 核心執行緒變成了一個普通的程序,執行在使用者空間中。
init 核心執行緒沒有地址空間,且它的 task_struct 物件中的 mm 為 NULL。因此,執行 exceve 會使這個 mm 指向一個 mm_struct,而不會影響到 init_task 程序的地址空間。
也正因為此,init 在轉變為程序後,其 PID 沒變,仍為 1。
建立完 init 核心執行緒後,init_task 程序演變為 idle 程序(PID 仍為 0)。
之後,init 程序再根據再啟動其它系統程序 (/etc/init.d 目錄下的各個可執行檔案)。
5.2 kthreadd 核心執行緒
init_task 程序演變為 idle 程序後,idle 程序會執行 kernel_thread 來建立 kthreadd 核心執行緒(仍然在 rest_init 函式中)。它的 PID 為 2,用來建立並管理其它核心執行緒(用 kthread_create, kthread_run, kthread_stop 等核心函式)。
系統中有很多核心守護程序 (執行緒),可以通過:ps -efj
進行檢視,其中帶有 [] 號的就屬於核心守護程序。它們的祖先都是這個 kthreadd 核心執行緒。
5.3 主核心頁全域性目錄
核心維持著一組自己使用的頁表,也即主核心頁全域性目錄。當核心在初始化完成後,其存放在 swapper_pg_dir 中,而且所有的普通程序和核心執行緒就不再使用它了。
5.4 核心執行緒如何訪問頁表
5.4.1 active_mm
對於核心執行緒,雖然它的 task_struct 中的 mm 為 NULL,但是它仍然需要訪問核心空間,因此需要知道關於核心空間對映到實體記憶體的頁表。然而不再使用 swapper_pg_dir,因此只能另外想法解決。
由於所有的普通程序的頁全域性目錄中的後面部分為主核心頁全域性目錄,因此核心執行緒只需要使用某個普通程序的頁全域性目錄就可以了。
在 Linux 中,task_struct 中還有一個很重要的元素為 active_mm,它主要就是用於核心執行緒訪問主核心頁全域性目錄。
- 對於普通程序來說,task_struct 中的 mm 和 active_mm 指向的是同一片區域;
- 然而對核心執行緒來說,task_struct 中的 mm 為 NULL,active_mm 指向的是前一個普通程序的 mm_struct 物件。
5.4.2 mm_users 和 mm_count
但是這樣還是不行,因為如果因為前一個普通程序退出了而導致它的 mm_struct 物件也被釋放了,則核心執行緒就訪問不到了。
為此,mm_struct 物件維護了一個計數器 mm_count,專門用來對引用這個 mm_struct 物件的自身及核心執行緒進行計數。初始時為 1,表示普通程序本身引用了它自己的 mm_struct 物件。只有當這個引用計數為 0 時,才會真正釋放這個 mm_struct 物件。
另外,mm_struct 中還定義了一個 mm_users 計數器,它主要是用來對共享地址空間的執行緒計數。事實上,就是這個主執行緒所線上程組中執行緒的總個數。初始時為 1。
注意,兩者在實質上都是針對引用 mm_struct 物件而設定的計數器。
不同的是,mm_count 是專門針對自身及核心執行緒或引用 mm_struct 而進行計數;而 mm_users 是專門針對該普通執行緒所線上程組的所有普通執行緒而進行計數。
另外,只有當 mm_count 為 0 時,才會釋放 mm_struct 物件,並不會因為 mm_users 為 0 就進行釋放。
6 總結
1.Linux核心可以看作一個服務程序(管理軟硬體資源,響應使用者程序的種種合理以及不合理的請求)。
2.核心執行緒就是核心的分身,一個分身可以處理一件特定事情。核心執行緒的排程由核心負責,一個核心執行緒處於阻塞狀態時不影響其他的核心執行緒,因為其是排程的基本單位。
3.核心執行緒是直接由核心本身啟動的程序。核心執行緒實際上是將核心函式委託給獨立的程序,它與核心中的其他程序”並行”執行。核心執行緒經常被稱之為核心守護程序。
4.從CPU排程的角度來說,linux程序=執行緒.他們之間只有一點區別:
tgid相同的兩個程序切換=執行緒切換
tgid不同的兩個程序切換=程序切換
程序切換需要多做1步:切換頁目錄以使用新的地址空間
5.當用戶執行緒(=程序)呼叫系統呼叫時,實際上是進行了一次程序切換,但是因為沒有切換頁目錄(核心執行緒還在這個程序地址空間執行),我們認為這實際是一次執行緒切換.
6.所以我們可以大膽的想象為:核心執行緒是一種特殊執行緒,任何使用者程序都可以在需要使用核心提供的某些功能時啟動一個特殊執行緒,並將CPU使用權交給他,等這個特殊執行緒完成操作後再觸發一次執行緒切換或者一次程序切換(如果核心執行緒在執行過程中被掛起,CPU被切換到了另一個tgid不同的程序),我們的使用者程序就可以得到結果繼續執行.這個模式其實就是經典的生成者-消費者模型(核心執行緒=生產者 使用者執行緒=消費者).從這個角度來說,核心執行緒約等於經典執行緒模型裡的"執行緒"--這也是我們稱他為核心執行緒而不是核心程序的一個主要原因.
7.核心執行緒和經典執行緒模型裡的"執行緒"不同的地方主要有2點
a.核心執行緒是有核心初始化時就建立好的,經典執行緒模型裡的"執行緒"由使用者在需要時建立
b.核心執行緒可以被所有使用者程序共享使用,經典執行緒模型裡的"執行緒"被某一程序私有
8.為了系統安全,系統呼叫不能由使用者執行緒以函式呼叫的方式直接執行,而是以中斷的方式切換到核心執行緒,使用"執行緒壁壘"來提供安全的訪問.
9.從經典"程序-執行緒"模型來說,當我們說程序的"核心態"時實際上是指執行緒的"核心態".--當程序裡的某一個執行緒申請系統呼叫時,其他執行緒還可以在其他cpu上繼續執行(使用者態或核心態),這時不能簡單的說程序處於"核心態".但從linux"程序-執行緒"模型來說,執行緒實際是一個特殊的輕量化的程序,執行緒處於"核心態"就是這個輕量化的程序處於"核心態".