
系統穩定性評測
系統穩定性評測
什麼是系統的穩定性評測呢,主要驗證在以下兩個條件下,系統依然能夠正常的提供服務。
- 持續施壓
- 暴力破壞
持續施壓
這一點和自動化遍歷的原理很像, 我們長期執行自動化測試, 持續給後端服務施壓。 只不過有兩個不一樣的地方
- 自動化遍歷是單執行緒執行, 而在後端的穩定性測試中,要放大這個量。 比如說本來一次自動化測試是啟動50個執行緒,但我繼續放大這個量,比如我放大10倍, 100倍。讓這個系統處於一種較高的壓力。
- 自動化遍歷是隨機點選,深度不夠。 而後端的穩定性測試的場景一般是針對整個系統的,所以測試用例都是應用級的,而不是單介面測試。 也就是說不管自動化的方式是UI的還是介面的還是SDK的,都要講獨立的API組合各種業務場景。 覆蓋的真實場景越多越好。
這裡需要注意的是我們需要讓系統在這個場景下持續執行很長一段時間。 多久呢? 比如說1個星期,甚至更久, 因為很多諸如記憶體洩露的問題是會在系統執行很久之後才會出現的。所以在這期我們也需要間監控服務是否出現異常,自動化測試用例是否會出現失敗。
實現思路:
最簡單的方法就是寫個java的 schedulerExecutor。 按策略持續併發的排程自動化測試。比如以下是部分核心程式碼:
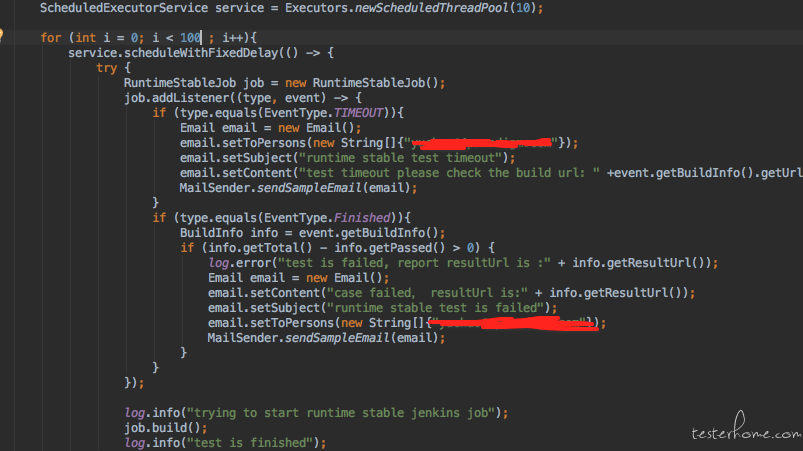
暴力破壞
第二種測試就是在人為造成的事故的場景下,系統依然能夠穩定執行。比如現在的軟體很多都是微服務架構了, 並且做了很多高可用,負載均衡,容災等設計。 所以是保證了即便部分模組甚至節點出現問題,也能夠保證系統正常提供服務的。 為了驗證這一點,我們自然也需要做一點破壞工作。 比如我們公司的產品是部署再k8s中的,那麼在執行穩定測試的途中就要使用工具按不同的策略kill不同的服務。 在業界有個很出名的工具叫chaos monkey, 是在雲伺服器中模擬各種事故,對服務進行各種破壞的工具。 當然它的使用場景有限,無法應用在k8s叢集中,但我們可以借鑑其思路呼叫k8s的API開發自己的工具。
比如我們按事故等級劃分:
- 等級一:週期隨機破壞一個服務的部分例項
- 等級二:週期按百分比隨機破壞數個服務的部分例項
- 等級三:週期破壞所有服務的部分示例
PS:以上說的部分例項是因為都是開啟了高可用與負載均衡的部署架構,理論上只要有一個例項就可以對外提供服務。 所以在每個事故等級下都會有更細粒度的劃分。 比如:
- 只破壞當前服務的一個例項
- 破壞當前服務的多個例項(由測試人員自己指定)
- 只留下當前服務的一個例項,其他例項均破壞掉。
實現思路:
也很簡單,封裝k8s的API server達到按策略隨機破壞的目的。以下是核心程式碼:
package chaos; import chaos.pod.PodKillPolicy; import chaos.pod.PodKiller; import com.fasterxml.jackson.annotation.JsonProperty; import io.fabric8.kubernetes.client.DefaultKubernetesClient; import k8s.K8SClientFactory; import lombok.Data; import lombok.extern.log4j.Log4j; import utils.Common; import java.util.*; import java.util.concurrent.TimeUnit; /** * Created by sungaofei on 18/11/7. */ @Data @Log4j public class NamespaceKiller { @JsonProperty private String namespace; @JsonProperty private List<String> deploymentList = new ArrayList<>(); @JsonProperty private PodKillPolicy podKillPolicy; @JsonProperty private AccidentLevel accidentLevel = AccidentLevel.ONE_SERVICE; @JsonProperty private double percent; public NamespaceKiller(String namespace) { this.namespace = namespace; DefaultKubernetesClient k8s = K8SClientFactory.getK8SClient(); k8s.inNamespace(namespace).apps().deployments().list().getItems().forEach((deploy) -> this.deploymentList.add(deploy.getMetadata().getName())); this.podKillPolicy = PodKillPolicy.KILL_ONE; } public void kill() { log.info(Common.parseJson(this)); List<PodKiller> podKillers = new ArrayList<>(); for (String deployName : deploymentList) { PodKiller podKiller = new PodKiller(namespace, deployName, podKillPolicy); podKillers.add(podKiller); } Random random = new Random(); // 如果策略是按照百分比去kill掉namespace下的服務 if (accidentLevel.equals(AccidentLevel.Percent_Kill)) { int size = new Long(Math.round((double) podKillers.size() * percent)).intValue(); Map<Integer, PodKiller> deletedPod = new HashMap<>(); for (int i = 0; i < size; i++) { // 如果隨機的index是之前已經被刪除過的。 那麼需要重新隨機 int index = random.nextInt(podKillers.size()); while (true){ if (!deletedPod.containsKey(index)){ deletedPod.put(index, podKillers.get(index)); break; } log.info("recreate the random index"); index = random.nextInt(podKillers.size()); } PodKiller podKiller = podKillers.get(index); podKiller.kill(); deletedPod.put(index, podKiller); } } // 如果策略是一個namespace下只隨機殺死一個deployment的服務的情況 if (accidentLevel.equals(AccidentLevel.ONE_SERVICE)){ int index = random.nextInt(podKillers.size()); podKillers.get(index).kill(); } // 如果策略是殺死一個namespace下所有的服務的情況 if (accidentLevel.equals(AccidentLevel.ALL_SERVICES)){ podKillers.forEach(PodKiller::kill); } } }
監控
在穩定性測試中必然少不了監控體系, 因為我們在評測整個系統的穩定性的時候,必然要附帶各個資源使用指標, 以及各種事故分析報告。 所以要對系統的方方面面提供完善的監控體系, 而我們使用的是prometheus 監控體系,k8s已經比較好的支援 prometheus了,所以可以整體整合進k8s中。 可以定製自己的儀表盤來視覺化我們的事故分析報告。 比如使用granfna制定過去10天內OOM的事故報告:
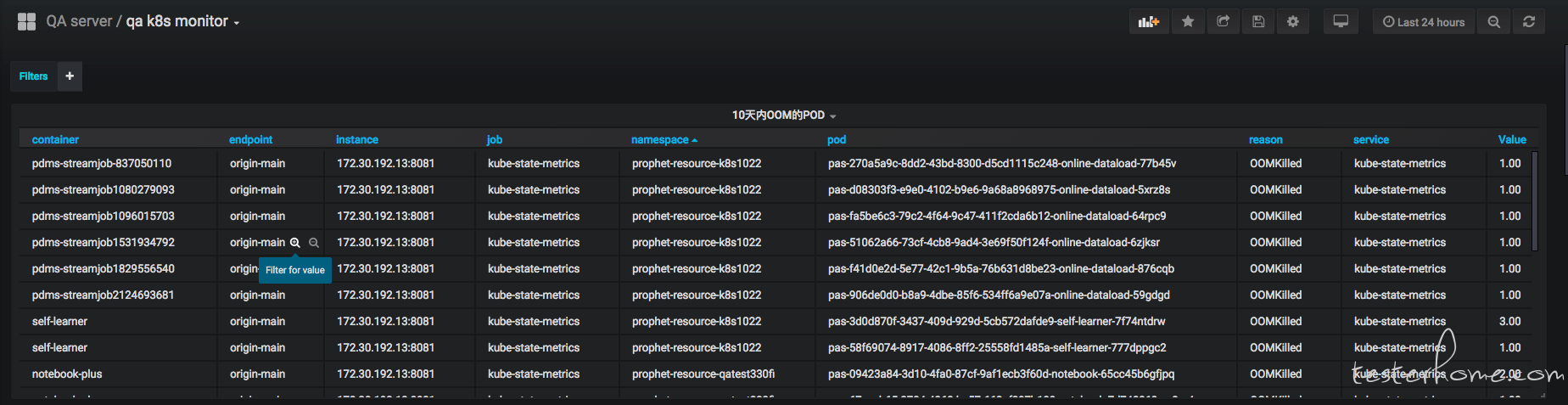
具體prometheus的教程我就先不寫了。。。有好多。。不搬了。。
結尾
在軟體界針對可靠性有以下指標:
3個9:(1-99.9%)*365*24=8.76小時,表示該軟體系統在連續執行1年時間裡最多可能的業務中斷時間是8.76小時。
4個9:(1-99.99%)*365*24=0.876小時=52.6分鐘,表示該軟體系統在連續執行1年時間裡最多可能的業務中斷時間是52.6分鐘。
5個9:(1-99.999%)*365*24*60=5.26分鐘,表示該軟體系統在連續執行1年時間裡最多可能的業務中斷時間是5.26分鐘。
穩定性測試的目標之一就是驗證並輔助系統達到更高的指標。